
We’re pleased to announce the release of Couchbase Lite 3.2 with support for vector search. This launch follows the coattails of vector search support on Capella and Couchbase Server 7.6. Now, with vector search support in Couchbase Lite, we enable cloud to edge support for vector search powering AI applications in the cloud and at the edge.
In this blog post, I will discuss the key benefits of supporting vector search at the edge, including a brief look at use cases that fall within your Couchbase Lite applications.
What is Vector Search?
Vector search is a technique to retrieve semantically similar items based on vector embedding representations of the items in a multi-dimensional space. Distance metrics are used to determine the similarity between items. Vector Search is an essential component of Generative AI and Predictive AI applications.
Couchbase Mobile Stack
If you are new to Couchbase, here is a quick primer on Couchbase Mobile.
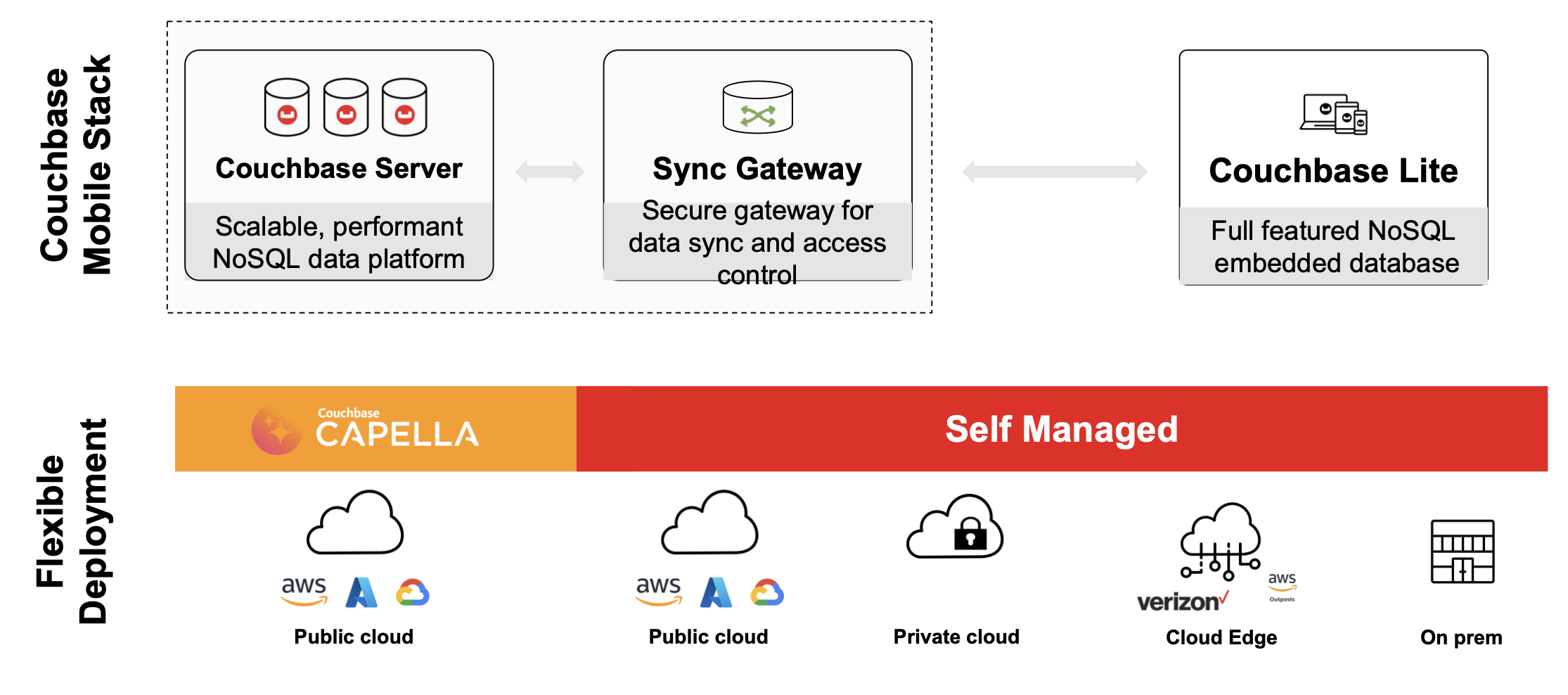
Couchbase Mobile is an offline-first, cloud-to-edge database platform. It is comprised of the following:
Cloud Database: Available as a fully managed and hosted Database-as-a-Service with Couchbase Capella, or deploy and host Couchbase Server on your own.
Embedded Database: Couchbase Lite is a full featured, NoSQL embedded database for mobile, desktop and IoT applications.
Data Sync: A secure gateway for data sync over the web, as well as peer-to-peer sync between devices. Offered as fully hosted and managed sync with Capella App Services, or install and manage Couchbase Sync Gateway yourself.
Check out our documentation for more information.
Vector Search Use Cases & Benefits
While the benefits of vector search are fairly well understood, why would you want vector search at the edge?
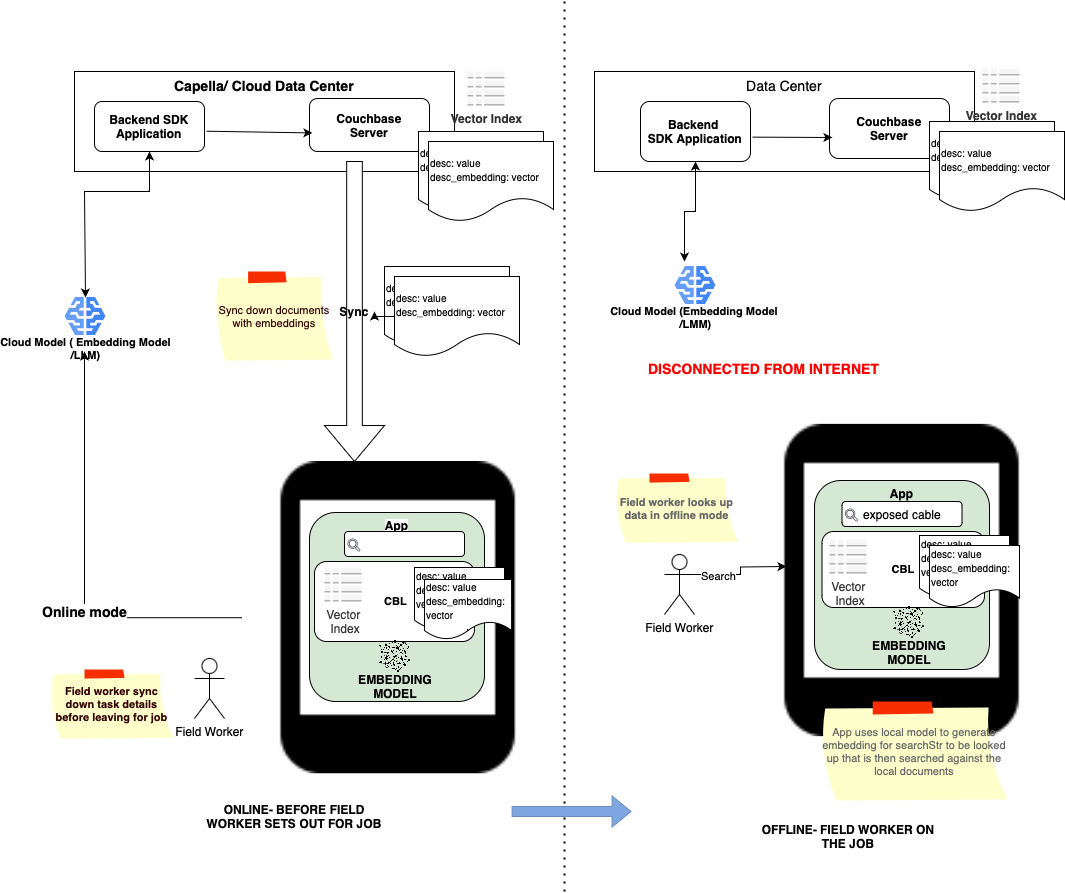
Semantic Search in Offline-First Mode
Applications where simple text-based searches are insufficient can now support semantic searches on local data to retrieve contextually relevant data even when the device is in offline mode. This ensures that the search results are always available.
Example
Consider a classic field application Utility workers out at repair sites and disaster areas operate in areas with poor or no Internet connectivity:
- The words, line, cable, wire are synonymous for a utility company. When utility workers in the field search for the phrase, line, documents with cable, wire have to be returned as well.
- Using full-text search (FTS), the application will have to maintain a synonym list which is hard to create, manage and maintain.
- Relevance is also important. So a query for: safety procedures for downed power lines – should focus on manuals that relate to downed power lines, electricity cable, high voltage line etc.
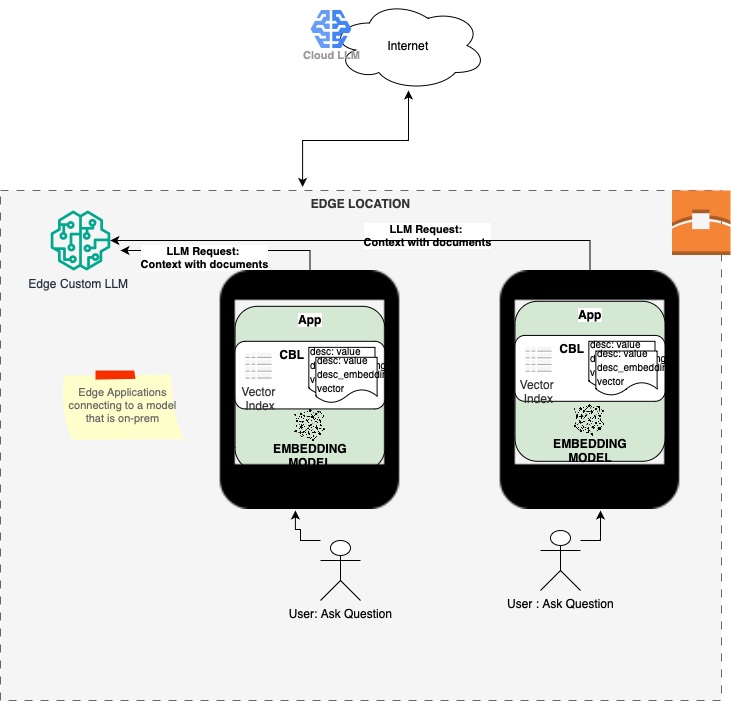
Alleviating Data Privacy Concerns
One of the primary use cases of a vector search database is the ability to fetch contextually relevant data. The search results are then included as context data to queries sent to a large language model (LLM) for customizing query responses — this is the cornerstone of Retrieval-Augmented Generation (RAG). Running searches against data that is private or sensitive in nature can raise privacy concerns. When performing searches on a local device, we can restrict searches to only users who are authenticated and authorized to access the private data on the device. Any personally identifiable information (PII) from the results of the vector search can be redacted and then leveraged within the RAG query to an LLM.
Furthermore, if a custom LLM is deployed at the edge location, e.g., a hospital, retail store, any concerns of sending the contextually relevant search results over the Internet to a remote cloud service is further alleviated.
Example
Consider the following example of a health care application:
- A doctor at a hospital is looking for treatment options for a patient recovering from surgery.
- Relevant patient context is retrieved from medical history and preferences. Access to this data is authenticated and authorized.
- The patient context is sent along with the query to an Edge LLM model hosted in the hospital that can then generate a customized recovery plan.
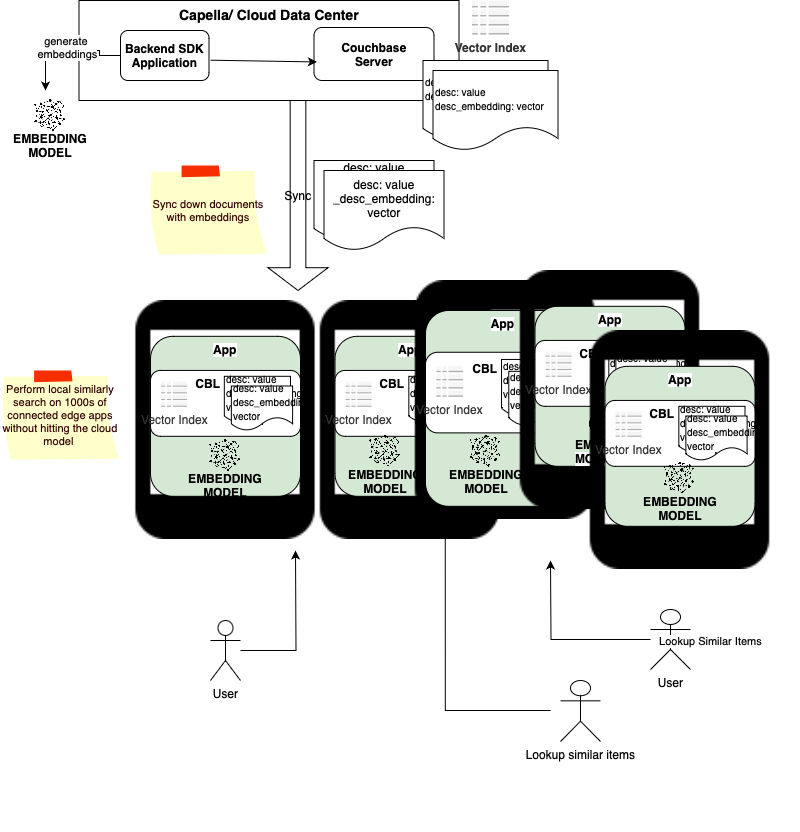
Reduced Cost-per-Query
When you have 100s of 1000s of connected clients querying against a cloud based LLM, the load on cloud model and operational costs of running the cloud based model can be considerably high. By running queries locally on the device, we can save on data transfer costs and cloud egress charges and also decentralize the operational costs.
Example
Consider the following example of a digital customer service assistant application:
- A retail store syncs with a product catalog, store-specific pricings and promotions data to customer service kiosks at the store (edge device).
- A user at the kiosk searches for a hat that matches the jacket she is wearing, captured via a camera. She is also interested in hats that are on sale.
- Instead of the kiosks sending in search queries to a remote server, similarity searches are performed locally, at the kiosk, on the catalog to find similar items that are on sale.
- As a bonus, the captured image can be discarded immediately from the kiosk, alleviating privacy concerns.
Low Latency Searches
Searches run locally against a local dataset using a local embedded model eliminate the network variability and will be consistently fast. Even in the case where the model is not embedded within the local device, but is deployed at the edge location, the round trip time (RTT) associated with queries can be significantly reduced compared to searches made over the Internet.
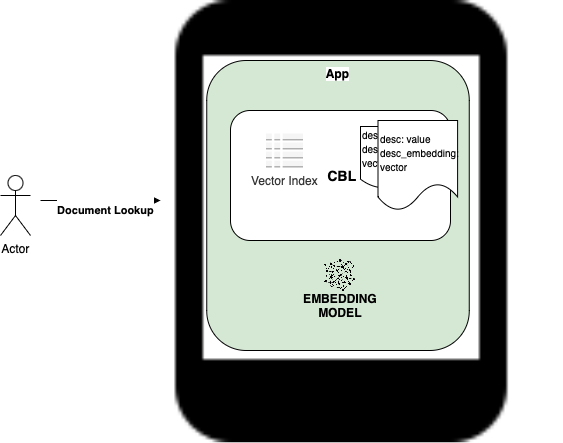
Example
Revising the retail store application:
- The product catalog, store-specific pricings and promotions documents that are synced to the customer service kiosks include vector embeddings. The vector embeddings are generated by LLM embedding models in the cloud.
- The documents that are synced down are then indexed locally at the kiosk.
- A customer at the store kiosk looking for a specific item does a regular search for Adidas women’s tennis shoes size 9 and can also run a find related items function by doing a similarly search between the product that was retrieved using a regular search and comparing it with the remaining product documents. The search is done locally and is fast.
- In this case, while the vector embeddings are generated at the cloud, the similarity search is done locally. In fact, in this particular application, there is no need for even an embedding model in the kiosk application.
Unified Cloud-to-Edge Support for Vector Similarity Search
While there are queries that are best suited for the cloud, for reasons explained earlier in the post, there are cases where the queries are better suited for the edge. Having the flexibility to run queries at the cloud or at the edge or both will allow developers to build applications that leverage the best of both worlds.
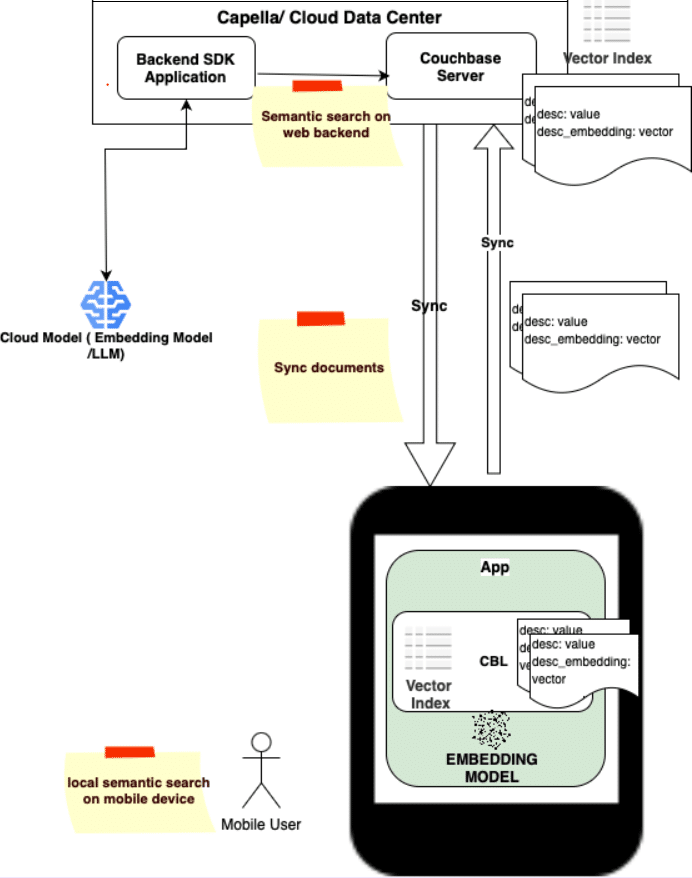
Example
- Consider a mobile banking app where user-specific transaction history for past 6 months are synced down and locally stored on device
- A user is looking for transactions related to purchase they made a few months ago. The search is done locally so its fast and is also available offline
- Transactions related to all users are stored in the cloud servers where semantic search is used by their fraud detection application to detect patterns of fraudulent activities
Show me the code!
Now that you are excited about the benefits of vector search within your edge application, lets see what it takes to implement the same. It’s quite simple and just takes a few lines of code to bring the power of semantic search within your edge application. The example below is in swift but check out the resource section below for code snippets in language of your choice.
Creating a Vector Index
In this example, we create a vector index with the default values. Applications have the option to further customize the vector index configuration with a different distance metric, the index encoding type and centroid training parameters:
|
1 2 3 4 5 6 |
// create vector index configuration. In example, the “description” document property is indexed (can be any SQL++ expression) var config = VectorIndexConfiguration(expression: “description”, dimensions: 158, centroids: 20) // create vector index with specified configuration try collection.createIndex(withName: “myIndex”, config: config) |
Doing a Similarity Search
In this example, I am running a SQL++ query to retrieve the top 10 similar documents with their description matching the target embedding of the searchPhrase:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// Retrieve vector embedding for searchPhrase from embedding model guard let searchEmbedding = modelRef.getEmbedding(for: searchPhrase) else { throws Errors.notFound } // Construct SQL++ query to return top 10 documents from database with content similar the search phrase let sql = “SELECT meta().id, description FROM _ ORDER BY APPROX_VECTOR_DISTANCE(vector, $searchParam) LIMIT 10″ // create query let query = try db.createQuery(sql) // set the embedding vector associated with the search param let params = Parameters() params.setValue(searchEmbedding, forName: “searchParam”) query.parameters = params // Execute vector search query try query.execute() |
Resources
Here are direct links to a few helpful resources.
- Step-by-Step Installation Guides
- Couchbase Lite 3.2 Download
- Couchbase Lite Vector Extensions Library Downloads
- Vector search support requires a separate extensions library that needs to be linked to your application in addition to the primary Couchbase Lite SDK.
- Couchbase Lite Vector Search Explainer video
- Sample app for Couchbase Lite vector search
Stay tuned for an upcoming blog post on reference architectures to support vector search
Leave a comment
You must be logged in to post a comment.