
SUMMARY
Data modeling, a process that supports efficient database design and management, involves three stages: conceptual, logical, and physical. The first stage, the conceptual model, defines high-level entities and relationships. The second stage, the logical model, adds technical detail like attributes, data types, and structures, and the final stage, the physical model, implements the design in a specific database management system (DBMS). Each model serves a unique purpose, from clarifying business requirements to guiding system implementation. These models are crucial to maintaining data integrity and can evolve as your business needs change.
Continue reading part one of our three-part series on data modeling to gain an even greater understanding of conceptual, logical, and physical models.
What is data modeling?
Data modeling is the process of organizing data structures, relationships, and rules to support database design and data management. It involves defining how data is structured, stored, and accessed, using diagrams or models that map out entities, attributes, and relationships. By organizing data logically and consistently, data modeling helps ensure accuracy, efficiency, and scalability in information systems. A well-designed data model should also be able to respond to change and handle future requirements.
Why is data modeling important?
Creating a data model is an important step in application development. It enables your team to decide what data is necessary and how to collect and structure it. A data model can be considered a set of decisions, assertions, and assumptions. Even if something is modeled incorrectly, those assumptions are written down and help the team understand why it was modeled that way. With this baseline of information, the team can better determine whether making a change is the right course of action in the future.
Conceptual vs. logical vs. physical data modeling
Conceptual, logical, and physical data models each serve a key function in the data modeling process. A conceptual model provides a high-level system overview, focusing on the main entities and relationships without going into technical details. A logical model adds more structure by defining data elements, attributes, and their relationships. A physical model addresses implementation details, specifying how data will be stored in a database’s tables, columns, and indexes.
Here’s how to think of each model in the simplest terms:
- Conceptual – the “what” model
- Logical – the “how” of the details
- Physical – the “how” of the implementation
Each level of conceptual, physical, and logical data models can involve different roles from your team.
Conceptual data model
The conceptual data model can be considered the “whiteboard” data model. It does not address the “how.”
For this model, it’s important to focus on capturing all the types of data (or “entities”) that the system will need. In addition to entities, a conceptual data model will also capture:
- Attributes: Individual properties of an entity. For instance, a “person” entity may have “name” and “shoe size.” An “address” entity may have “zip code” and “city.”
- Relationships: How an entity connects to other entities. For instance, a “person” entity may have one or more “addresses.”
Along with the entities, their attributes, and relationships, a conceptual model can also:
- Organize scope: Details which entities are included and which are not included.
- Define business rules: For instance, are person entities allowed to have multiple addresses? What about multiple emails? Do they need to have a unique identifier?
Architects often create the conceptual data model with business stakeholders and domain experts.
Conceptual data model example
There are many “languages” for describing a conceptual data model. But as long as it’s documented in an accessible way, it can be as easy as boxes and arrows.
Here’s a diagram of a conceptual data model that involves two core entities, travel routes (and their associated schedules), and airlines:
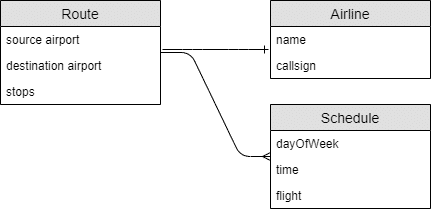
While these may look like tables in a relational database, the conceptual modeling stage is too early to determine how the data will be stored. That determination comes later: it could be tables, JSON documents, graph nodes, CSV files, blockchain, or any other number of storage mediums.
Logical data model
A logical data model is decided upon after stakeholders agree on a conceptual model.
This stage involves filling in the details of the conceptual model. It’s still too early to pick a database management system (DBMS), but this stage can help you decide which database to use (relational, document, etc.). For instance, if you choose relational, you’ll need to decide which tables to create. If you choose document, you’ll need to define the collections.
During this step, you should also decide the details of each field or column and relationship. These details include data types, sizes, lengths, arrays, nested objects, etc.
Architects and business analysts typically create the logical model.
Logical data model example
For instance, if you’re going with a relational model, the logical model might look like this:
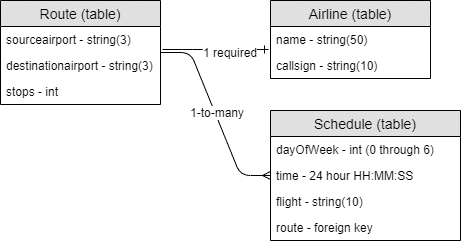
However, with a document database, the schedule can be modeled directly as part of the route. There’s no need for a foreign key, but it’s still helpful to consider it its own sub-entity. So that logical model might look like this:
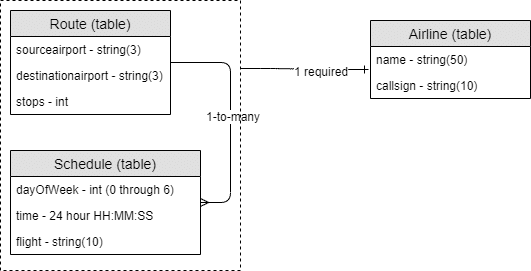
A schedule, which has a fairly small, finite footprint, should be embedded in the same collection. Social media posts, which are unbounded, should be modeled in separate collections.
Physical data model
Once you’ve defined a logical model, it’s time to implement it into a database.
If you decide on a relational model, some options you can choose from include Microsoft SQL Server, Oracle, PostgreSQL, or MySQL. However, if your modeling process reveals that your data model will likely change frequently to adapt to new requirements, you should consider using a document database. Couchbase, a NoSQL document database, supports relational concepts like JOINs, ACID transactions, and flexible JSON data.
The physical data model should include:
- A specific DBMS
- Specifications for storing data (e.g., on disk, RAM, or hybrid)
- Instructions for accommodating replications, shards, partitions, etc.
Database administrators (DBAs) and developers typically create the physical data model.
Physical data model example
Here’s an example of a physical model for Couchbase:
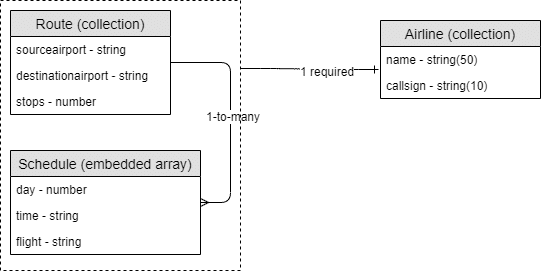
It’s usually helpful to show sample data along with the physical model.
Here’s a sample route document:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ “airlineid”: “airline_137”, “sourceairport”: “TLV”, “destinationairport”: “MRS”, “stops”: 0, “schedule”: [ { “day”: 0, “utc”: “10:13:00”, “flight”: “AF198” }, { “day”: 0, “utc”: “01:31:00”, “flight”: “AF943” }, { “day”: 1, “utc”: “12:40:00”, “flight”: “AF356” }, // … etc … ] } |
And here’s a sample airline document:
|
1 2 3 4 5 |
key: airline_137 { “name”: “Air France”, “callsign”: “AIRFRANS”, } |
The above examples are simplified views of an actual physical data model. To work with an in-depth version of this data model, you can sign up for a free account of Couchbase Capella.
How are conceptual, logical, and physical data models used in AI applications?
In AI applications, conceptual data models define high-level entities and their relationships, such as “user,” “interaction,” or “sensor data,” to establish what the AI system needs to understand. Logical data models build on this foundation by detailing the attributes, data types, and relationships, creating a clear blueprint for how structured data will be organized for training, validation, and inference. These are then translated into physical data models, which define database schemas or data lake structures optimized for performance, storage, and accessibility. Together, these models ensure efficient data handling throughout the AI pipeline, from model training to real-time predictions and analytics.
Data modeling advantages
Data modeling offers many advantages that improve the quality, efficiency, and scalability of databases. Providing a blueprint of data structures and relationships helps teams align on data requirements and reduces misunderstandings during development. It also supports better database design by identifying redundancies, inconsistencies, and gaps early in the planning process. With a well-structured model, organizations can strengthen data integrity, streamline data access, and improve application performance. Additionally, data modeling makes adapting to changing business needs easier by offering a flexible foundation for future updates and integrations.
Data modeling challenges
One common challenge with data modeling is capturing business requirements and translating them into a structured model, especially when stakeholders have different perspectives. If not properly managed, data models can also become overly complicated or rigid, making them harder to maintain or scale as requirements change. Additionally, aligning models across different teams and departments can lead to inconsistencies if collaboration is not prioritized. Ensuring that models stay up to date with changing data sources and business processes requires ongoing coordination.
Next steps and resources
In part two, we discuss the various physical data models, including relational, document, graph, and wide table, to help you decide which data model best suits your needs.
Before you head to that blog post, you can review the resources below to learn more about the topic we’ve just covered:
- The Couchbase Data Model
- Phases of Data Modeling – Couchbase Developer Portal
- Data Modeling Guide – PDF
- JSON Data Modeling Support for Developers
FAQs
What are the three types of data models? The three types of data models are conceptual, logical, and physical, each representing different levels of detail in database design.
How do I model data? To model data, start by identifying key entities, attributes, and relationships based on business requirements. Next, create a conceptual data model to outline the high-level structure, followed by a logical model that adds details like data types and rules. Finally, develop a physical data model that maps the design to a specific type of database.
What are examples of conceptual, physical, and logical data models? An example of a conceptual data model is an entity-relationship diagram (ERD) that outlines high-level entities like “Customer,” “Order,” and “Product” without technical details. A logical data model adds more structure, such as defining attributes like “CustomerID” and “OrderDate,” and specifying data types and rules. A physical data model translates this into a specific database format, detailing table names, column types, indexes, and storage settings tailored to a platform like PostgreSQL or Couchbase.
Leave a comment
You must be logged in to post a comment.