This blog was originally posted on Cecile Le Pape's personal blog. To see to original blog post, click here.
In my previous post, I talked about how to setup a flexible content management service using Couchbase as the metadata repository, on top of an Apache Chemistry server. The blobs themselves (pdf, pptx, docx, etc) are stored in a separate file system or in a blob store. Today, I would like to show how Couchbase can be used to store the blobs themselves, using a custom chunk manager. The idea is to store not only the metadata of a document (date of creation, creator, name, etc.) but in addition the blob itself.
The purpose of this new architecture is to reduce the number of different systems (and licences to pay) and also to benefit directly from the replication features offered by Couchbase.
First, let’s remember that Couchbase is not a blob store. This a memory-based document store, with an adhoc cache management tuned so that most of the data stored in Couchbase should be in RAM for fast querying. Data are also replicated between nodes (if replication is enabled) inside the cluster and optionnaly outside the cluster if XDCR is used. This is why data stored in Couchbase can not be larger than 20 MB. This is a hard limit, and in real life 1MB is already a large document to store.
Knowing that, the point is: how can I store large binary data in Couchbase ? Simple answer: chunk it!
The new architecture looks now like this:
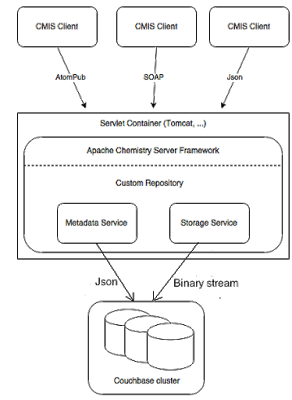
There is now 2 buckets in Couchbase:
- cmismeta : used to store metadata
- cmisstore : used to store blobs
When a folder is created, only the bucket cmismeta is modified with a new entry because of course, a folder is not associated to any blob. This is simply a structure used by the user to organise the documents and navigate in the folder tree. Folders are virtuals. The entry point of the structure is the root folder as described previously.
When a document (for instance a pdf or a pptx) is inserted into a folder, 3 things happen:
- A json document containing all its metadata is inserted into the cmismeta bucket, with a unique key. Let’s say for instance that the document has the key L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=.
- A new json document with the same key is created in the cmisstore bucket. This document contains the number of chunk, the max size of each chunk (same for all chunk except for the last one that might be smaller) and the application mime type.
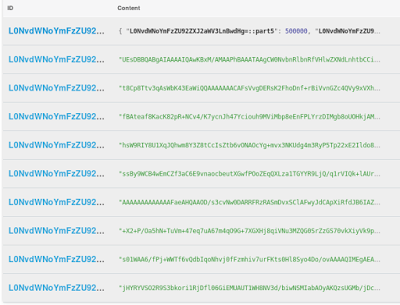
- The blob attached to the document is chunked into binary pieces (the size depends on a parameter you can set in the properties of the project). By default, a chunk is 500KB large. Each chunk is stored in the cmisstore bucket as a binary document, with the same key “L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=” as prefix, and a suffix “::partxxx” where xxx is the number of the chunk (0, 1, 2, …).
For instance, if a insert a pptx called CouchbaseOverview.pptx which size is 4476932 bytes into Couchbase, I get:
- In bucket cmismeta, a json document called L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
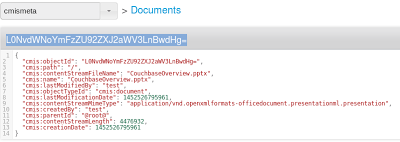
- In bucket cmisstore, a json document also called L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
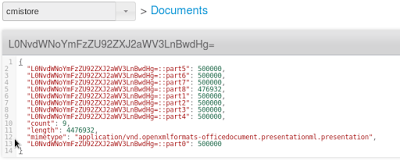
-
9 chunks containing binary data and called L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part0, L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part1, … , L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part8
The CouchbaseStorageService is the class implementing the StorageService interface already used for local storage or S3 storage as I showed into my previous blog. The first difference is the reuse of the same CouchbaseCluster instance as the one used for the MetadataService because only one Couchbase Environnement should be instantiated to save lots of resources (RAM, CPU, Network, etc).
Now let’s see the writeContent method itself:
*/
public void writeContent(String dataId, ContentStream contentStream)
JsonDocument jsondoc = JsonDocument.create(dataId, doc);
Now what to do to retrieve the file from Couchbase ? The main idea is to get each part, concatenate each other is the same order they were cut and send the byte array to the stream. There is probably a lot of way to do this, I simply implement a straightforward one using a single byte array where I write each byte into.
throws StorageException {
JsonDocument doc = bucket.get(dataId);
JsonObject json = doc.content();
Integer nbparts = json.getInt(“count”);
Integer length = json.getInt(“length”);
bucket.get(dataId + PART_SUFFIX + i,BinaryDocument.class);
Finally let’s see what happens in the workbench tool provided by Apache Chemistry ? I can see the document in the root folder and if I double click on it, the content is streamed from Couchbase and displayed in the associated viewer (here powerpoint) based on the mime type.
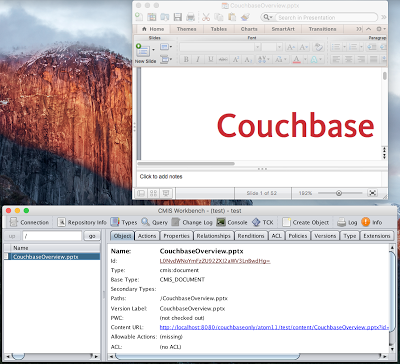
Workbench and document opened in powerpoint after double click
This is a great article, wondering if it would for video formats as well.