Introdução
Como a maioria de vocês sabe, o Couchbase é um banco de dados que oferece aos usuários uma variedade de opções de consistência e tolerância a falhas para garantir que o estado dos dados atenda a determinados critérios ou garantias. Os usuários podem especificar níveis variados de replicação, persistência, réplicas, grupos de servidores etc. para garantir que seus dados sejam duráveis, consistentes e corretos em determinados cenários de falha e operações de cluster. Para a próxima versão 6.5.0, novos recursos aprimorados durabilidade fornecerão aos usuários ainda mais segurança e garantias em caso de falhas. Como reconhecemos que as garantias são tão boas quanto suas provas, vamos dar uma olhada detalhada em como usamos o Jespen, um padrão do setor, para testar a durabilidade do banco de dados no Couchbase.
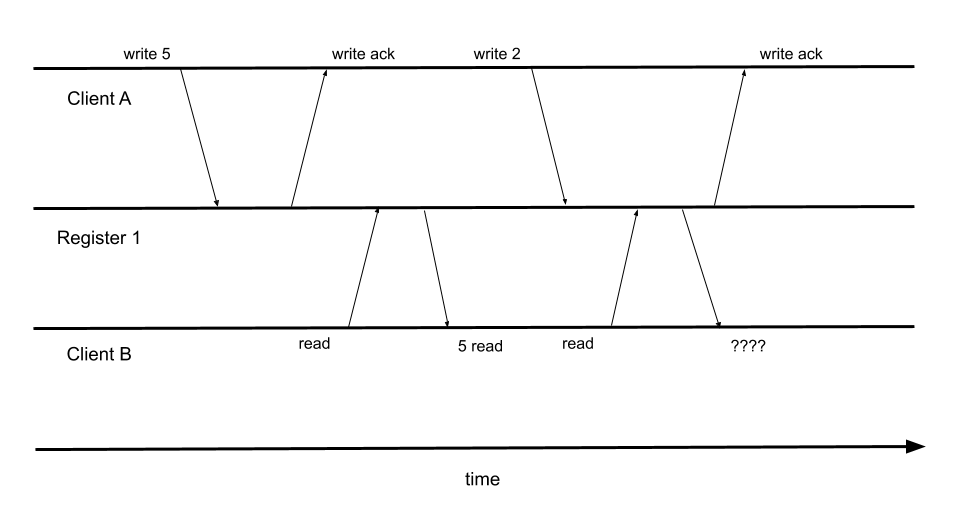
A estrutura do Jepsen funciona disparando operações de cliente em um cluster e, ao mesmo tempo, injetando algum tipo de caos, como partições de rede, eliminação de processos, redução da velocidade dos discos etc. Em seguida, o Jepsen analisará o histórico de operações com verificadores de histórico de operações incorporados ou personalizados. Mais notavelmente, o Jepsen vem com um consistência linearizável verificador. O Couchbase, com os novos níveis de durabilidade aprimorados na versão 6.5.0, afirma ser apenas sequencialmente consistente. No entanto, a consistência linearizável implica consistência sequencial [1]. Portanto, a aprovação no verificador de consistência linearizável também implica que o histórico de operações é de fato consistente em termos de sequência. No entanto, a reprovação na verificação de consistência linearizável não implica que o histórico da operação não seja consistente em termos de sequência. Para resumir, quando uma operação passa no verificador de consistência linearizável, podemos presumir que o Couchbase é consistente em termos de sequência. Se uma operação falhar no verificador de consistência linearizável, o Couchbase ainda poderá ser consistente em termos de sequência, mas será necessário investigar mais para confirmar.
Nosso objetivo com o Jepsen é testar, de vários ângulos diferentes, que nosso cliente Java SDK e o mecanismo KV do lado do servidor trabalhem em uníssono para: 1.) Nunca perder gravações reconhecidas; e 2.) Fornecer, no mínimo, um modelo de consistência sequencial enquanto operações de cluster e falhas são aplicadas ao sistema.
Arquitetura
O Jepsen fornece interfaces para as seguintes abstrações: Banco de dados, Cliente, Verificador, Nemesis, Geradores e Carga de trabalho. Para criar um teste do Jepsen, tivemos que implementar todas essas abstrações especificamente para o Couchbase. Cada teste é uma combinação dessas abstrações e de parâmetros adicionais.
Banco de dados
Implementamos a lógica de configuração, desmontagem e coleta de registros para um cluster do Couchbase. Essa lógica inclui suporte para configurações de bucket personalizadas, grupos de servidores e failover automático. O suporte total para todas as configurações possíveis de bucket e cluster não faz muito sentido porque o número de clusters possíveis tornará inviável o teste de todas as permutações. No entanto, criamos suporte para todas as configurações e opções de cluster mais importantes.
Cliente
Implementamos dois clientes diferentes: um cliente de "registro" e um cliente de "conjunto". O cliente de registro gravará, lerá e comparará e trocará valores de chaves independentes em um bucket do Couchbase. O cliente de conjunto apenas adiciona e exclui documentos de um bucket. Você pode pensar no bucket como o conjunto e o documento como um membro desse conjunto. Usamos esse cliente com um verificador de conjunto personalizado em vez do verificador de linearização, pois não estamos atualizando nenhum documento. Todos os testes que usam o cliente de conjunto e o verificador de conjunto funcionam tecendo fases de adição de documentos a um compartimento ou de exclusão de documentos de um compartimento.
Ambos os clientes recebem operações de um processo gerador. (Mais sobre isso adiante).
Deve-se tomar cuidado especial para tratar os erros do cliente. Por exemplo, uma DurabilityImpossibleException e uma RequestTimeoutException precisam ser tratadas de forma diferente pelo Jepsen. No primeiro caso, sabemos que a operação falhou, mas no segundo, a operação pode ter sido bem-sucedida. No caso de não conseguirmos distinguir se uma operação falhou ou foi bem-sucedida, o verificador de linearização do Jepsen executará uma verificação presumindo que a operação falhou e novamente presumindo que a operação foi bem-sucedida. O efeito disso é praticamente dobrar o tempo de verificação para cada operação ambígua. Portanto, queremos cenários de teste que limitem o número potencial de resultados de operações desse tipo. O verificador de linearização será aprovado se pelo menos um dos dois históricos possíveis for linearizável.
Verificador
Para nossos testes, temos três verificadores para escolher: verificador de linearização, verificador de conjunto e verificador de sanidade. O verificador de linearização vem com o Jepsen e é usado para verificar a consistência de chaves independentes em um bucket. Implementamos um verificador de conjunto para garantir que os testes com o cliente de conjunto tenham o conjunto correto de documentos em um intervalo. Por fim, implementamos um verificador de sanidade que garantirá que o teste em si passou pela sequência de alterações de estado do cluster sem erros. Por exemplo, um teste pode envolver um rebalanceamento que falha quando não deveria. Nesse caso, o verificador de sanidade marcará o teste como "desconhecido" em vez de "falho", já que estamos denotando testes falhos como aqueles que falham no verificador de conjunto ou no verificador de linearização. O verificador de sanidade também garante que pelo menos algumas operações foram bem-sucedidas.
Nêmesis
Tradicionalmente, no Jepsen, um nêmesis é um processo que receberá operações de um processo gerador e, em seguida, tomará medidas contra o sistema de acordo. Por exemplo, o nêmesis de partição incorporado pode receber uma operação de bloqueio e restauração que particionará a rede e restaurará a rede entre dois nós. A maioria dos nemeses incorporados é suficiente para cenários muito básicos, mas queríamos testar cenários adicionais que pudessem, por exemplo, reduzir a velocidade de um disco aleatório em um grupo de servidores aleatórios, eliminar o processo memcached do mesmo servidor e, por fim, restaurar o disco.
Para testar qualquer cenário que quisermos, criamos um único Couchbase nemesis que modela o cluster do Couchbase por meio de alterações de estado a partir de um estado inicial. Mantemos um mapa de nós e seus estados de rede, servidor, disco e cluster. Sempre que ocorre uma operação, o estado é atualizado para refletir a alteração no sistema. As operações passadas ao nosso nemesis especificam opções de direcionamento de nós, uma operação e parâmetros de operação. As opções de direcionamento de nós dizem ao nemesis, por exemplo, para direcionar um subconjunto de nós aleatórios de tamanho dois de todos os nós íntegros em um grupo de servidores aleatórios. Esse é o principal motivo pelo qual rastreamos o estado do nó: ele nos dá mais flexibilidade na forma como o nemesis pode agir.
Nosso nemesis tem suporte para as seguintes ações: failover (gracioso e rígido), recuperação (completa e delta), particionamento de rede personalizado, recuperação de rede, espera por failover automático, rebalanceamento em um conjunto de nós, rebalanceamento em um conjunto de nós, rebalanceamento de swap em dois conjuntos de nós, falha em um rebalanceamento, eliminação de um processo (memcached, babysitter, ns_server) em um conjunto de nós, reiniciar os mesmos processos em um conjunto de nós, diminuir a velocidade do cliente dcp, redefinir o cliente dcp, acionar a compactação, falhar em um disco em um conjunto de nós, diminuir a velocidade de um disco em um conjunto de nós e recuperar um disco em um conjunto de nós. Planejamos oferecer suporte a mais operações nemesis no futuro.
Geradores
Outra peça fundamental de um teste Jepsen são os geradores de operações de cliente e nêmesis. Esses geradores criarão uma sequência finita ou infinita de operações. Cada teste terá seu próprio gerador de nêmesis, mas provavelmente compartilha um gerador de cliente comum. Um gerador de nêmesis, por exemplo, pode ser uma sequência de partição, suspensão e restauração, repetida infinitamente. Um gerador de cliente especificará uma sequência aleatória e infinita de operação do cliente, bem como os parâmetros associados, como o nível de durabilidade, a chave do documento, o novo valor a ser gravado ou descartado etc. Quando um teste é iniciado, o gerador de cliente alimenta as operações do cliente para o cliente e o gerador de nêmesis alimenta as operações para o nêmesis. O teste continuará até que o gerador de nêmesis tenha concluído um número especificado de operações, um limite de tempo seja atingido ou um erro seja lançado.
Carga de trabalho
Uma carga de trabalho Jepsen é simplesmente um mapa que une todos os componentes anteriores, juntamente com quaisquer parâmetros adicionais, em um único teste. Nossas cargas de trabalho modificarão a lógica do gerador de nemesis e do cliente com base nos parâmetros de entrada, como a ativação de grupos de servidores e failover automático.
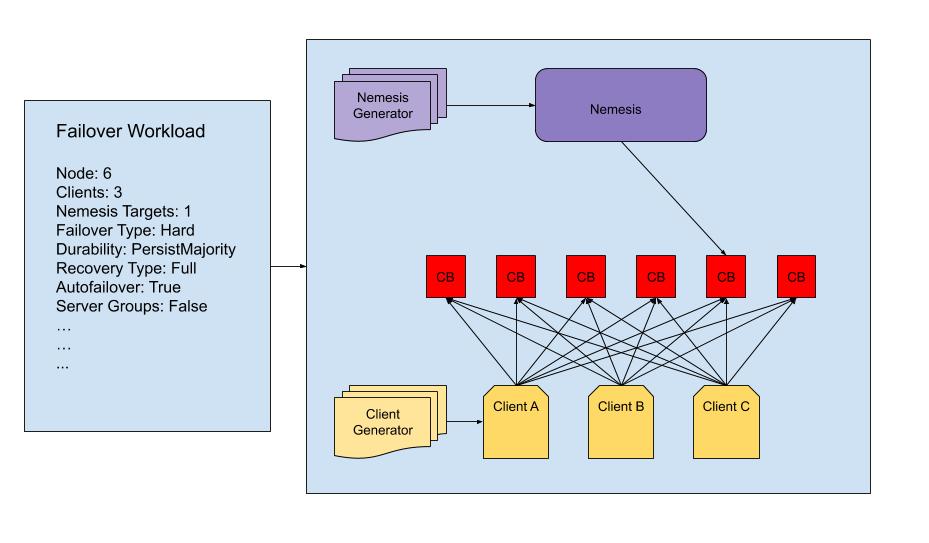
Desafios
Há dois desafios principais que encontramos ao criar esses testes, ambos decorrentes da limitação de recursos: 1.) O alto número de permutações de configuração de cluster; e 2.) O tempo necessário para executar o verificador de linearização.
Como o Couchbase é uma plataforma de dados complexa e altamente personalizável, há centenas de configurações a serem ajustadas. Algumas configurações são binárias (ex.: failover automático ativado), enquanto outras são contínuas (cota de RAM para KV). Isso cria um número extremamente alto de possíveis estados iniciais de cluster a serem testados. Então, com as maneiras quase infinitas de compor nossas operações nêmesis, temos um espaço de teste muito grande para cobrir completamente.
O verificador de linearização, embora muito útil e produto de uma pesquisa muito boa, tem algumas limitações. O tempo que o verificador leva para analisar um histórico cresce exponencialmente com o número de operações. Além disso, operações ambíguas também causam crescimento exponencial. Portanto, temos um problema: queremos pressionar os clientes o máximo possível durante um teste, mas se pressionarmos demais os clientes, o verificador poderá ficar sem memória e não conseguirá analisar o histórico. Isso também significa que queremos que os testes sejam executados o mais rápido possível, mas isso reduzirá a área de superfície para encontrar um bug.
Soluções
Para contornar esses desafios, decidimos fazer o seguinte: concentrar-nos em um subconjunto de parâmetros de teste que são mais importantes para nossos clientes, manter os testes o mais curtos possível e executá-los com a maior frequência possível. Ao testar apenas parâmetros comuns, como réplicas de bucket, todos os novos níveis de durabilidade aprimorados, failover automático etc., podemos nos concentrar em um conjunto gerenciável de testes que será uma base sólida para comprovar nossas garantias de durabilidade.
Primeiro, nos concentramos nas configurações críticas do KV, com planos de adicionar novos serviços e configurações (consulta, índice, xdcr etc.) à medida que novos recursos são adicionados e a pedido do cliente. Em seguida, ajustamos nosso nêmesis para operar o mais rápido possível, reduzindo os tempos de espera, pesquisando o status da operação, limitando o número de operações e tendo zero documentos pré-carregados. Ter baldes vazios no início dos testes acelera os reequilíbrios subsequentes durante o teste. No entanto, precisamos testar cenários em que os compartimentos têm grandes quantidades de dados e uma quantidade relativamente pequena de RAM por compartimento. Esses cenários de alta densidade de dados, que estão sendo desenvolvidos, levarão muito mais tempo para serem executados. Precisamos ajustar o tamanho da carga de dados inicial de modo que as operações de rebalanceamento sejam rápidas o suficiente para que o verificador de linearização não fique sem memória. Além disso, devido ao limite de taxa das operações do cliente, precisamos executar os testes várias vezes. Com uma taxa de operação de cliente mais lenta, há uma probabilidade menor de duas operações se sobreporem ou de uma operação ocorrer em um momento de erro, mas se executarmos o teste várias vezes, poderemos aumentar o número total de operações sobrepostas e, com sorte, expor um erro.
Para executar os testes com a maior frequência possível, criamos uma hierarquia de conjuntos de testes. Nossos conjuntos se dividem em quatro categorias: sanidade, diário, semanal e completo. O conjunto de testes de sanidade tem um pequeno subconjunto de testes que deve ser executado após a entrada de novos commits e leva menos de uma hora para ser concluído. O conjunto diário maior não deve levar mais de 12 horas para ser executado e o semanal deve ser concluído em dois dias. O conjunto completo de testes é uma lista de todos os testes e leva cerca de uma semana para ser concluído. Para criar os conjuntos, reduzimos o conjunto completo de testes removendo testes semelhantes e mantendo a cobertura em um nível máximo. Atualmente, nosso conjunto completo tem 612 testes, o semanal tem 396, o diário tem 227 e o de sanidade tem 6 testes. Também temos um conjunto para bugs em versões anteriores (4.6.x, 5.0.x, 5.5.x, 6.0.x) que usamos para verificar se eles não estão mais presentes no produto. Exemplos desses tipos de bugs são MB-29369 e MB-29480.
Resultados
Nossos testes Jepsen conseguiram encontrar vários bugs no Couchbase. Esses bugs se enquadram em duas categorias: bugs gerais do produto e bugs de durabilidade e consistência dos dados. Os bugs de durabilidade e consistência são o motivo pelo qual iniciamos nossos testes Jepsen, portanto, consideramos que eles são mais importantes, pois temos um conjunto completo de regressão funcional que detecta bugs gerais do produto. Alguns exemplos de bugs de durabilidade e consistência que encontramos são MB-35135, MB-35060e MB-35053.
Nosso trabalho inicial com o Jepsen e os bugs que ele nos ajudou a encontrar nos deram mais confiança na capacidade do Couchbase de manter seus dados seguros em uma ampla gama de cenários de falha e operações de cluster. No entanto, são necessários testes contínuos, pois o Jepsen pode detectar um bug após centenas de execuções. Continuaremos a executar nossos testes do Jepsen diariamente e semanalmente, enquanto desenvolvemos suporte para mais cenários. O Jepsen é uma ferramenta indispensável na criação de sistemas com garantias de consistência e durabilidade de dados, e continuaremos a utilizá-lo e a expandir seus recursos.
Links:
[1] https://courses.csail.mit.edu/6.852/01/papers/p91-attiya.pdf
[3] https://jepsen.io/consistency/models/linearizable
[4] https://jepsen.io/consistency/models/sequential
[5] https://github.com/jepsen-io/jepsen
Mais recursos
Baixar
Faça o download do Couchbase Server 6.5
Documentação
Notas de versão do Couchbase Server 6.5
Couchbase Server 6.5 O que há de novo
Blogs
Blog: Anunciando o Couchbase Server 6.5 GA - O que há de novo e aprimorado
Blog: O Couchbase traz as transações ACID multi-documento distribuídas para o NoSQL