
With so many LLMs coming out, a lot of companies are focusing on enhancing the inference speeds for large language models with specialized hardware and optimizations to be able to scale the inference capabilities of these models. One such company making huge strides in this space is Groq.
In this blog post we will explore Groq and how you integrate Groq’s fast LLM inferencing capabilities with Couchbase Vector Search to create fast and efficient RAG applications. We will also compare the performance of different LLM solutions like OpenAI, Gemini and how they compare with Groq’s inference speeds.
What is Groq?
Groq, Inc. is an American technology company specializing in artificial intelligence particularly known for its development of the Language Processing Unit (LPU), an application-specific integrated circuit (ASIC) designed to accelerate AI inference tasks. It is specifically designed to enhance Large Language Models (LLMs) with ultra-low latency inference capabilities. Groq Cloud APIs enable developers to integrate state-of-the-art LLMs like Llama3 and Mixtral 8x7B into their applications.
What does this mean for developers? It means that Groq APIs can be seamlessly integrated into applications that demand real-time AI processing with quick inference needs.
How to Get Started with Groq APIs
To tap into the power of Groq APIs, the first step is to generate an API key. This is a straightforward process that begins with signing up on the Groq Cloud console.
Once you’re signed up, navigate to the API Keys section. Here, you’ll have the option to create a new API key.

The API Key will allow you to integrate state-of-the-art large language models like Llama3 and Mixtral into your applications. Next, we will be integrating the Groq chat model with LangChain in our application.
Using Groq as the LLM
You can leverage the Groq API as one of the LLM providers in LangChain:
|
1 2 3 4 5 6 |
from langchain_groq import ChatGroq llm = ChatGroq( temperature=0.3, model_name=“mixtral-8x7b-32768”, ) |
When you instantiate the ChatGroq object you can pass the temperature and the model name. You can take a look at the currently supported models in Groq.
Building RAG application with Couchbase and Groq
The goal is to create a chat application that allows users to upload PDFs and chat with them. We’ll be using the Couchbase Python SDK and Streamlit to facilitate PDF uploads into Couchbase VectorStore. Additionally, we’ll explore how to use RAG for context-based question-answering from PDFs, all powered by Groq.
You can follow the steps mentioned in this tutorial on how to set up a Streamlit RAG application powered by Couchbase Vector Search. In this tutorial we leverage Gemini as the LLM. We will replace the implementation for Gemini with Groq.
Comparing Groq’s performance
In this blog we also compare the performance of different LLM providers. For this we have built a drop down for the user to be able to select what LLM provider they wish to use for the RAG application. In this example we are using Gemini, OpenAI, Ollama and Groq as the different LLM providers. There is a large list of LLM providers supported by LangChain.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
st.sidebar.subheader(“Select LLM”) llm_choice = st.sidebar.selectbox( “Select LLM”, [ “OpenAI”, “Groq”, “Gemini”, “Ollama” ] ) if llm_choice == “Gemini”: check_environment_variable(“GOOGLE_API_KEY”) llm = GoogleGenerativeAI( temperature=0.3, model=“models/gemini-1.5-pro”, ) llm_without_rag = GoogleGenerativeAI( temperature=0, model=“models/gemini-1.5-pro”, ) elif llm_choice == “Groq”: check_environment_variable(“GROQ_API_KEY”) llm = ChatGroq( temperature=0.3, model_name=“mixtral-8x7b-32768”, ) llm_without_rag = ChatGroq( temperature=0, model_name=“mixtral-8x7b-32768”, ) elif llm_choice == “OpenAI”: check_environment_variable(“OPENAI_API_KEY”) llm = ChatOpenAI( temperature=0.3, model=“gpt-3.5-turbo”, ) llm_without_rag = ChatOpenAI( temperature=0, model=“gpt-3.5-turbo”, ) elif llm_choice == “Ollama”: llm = Ollama( temperature=0.3, model = ollama_model, base_url = ollama_url ) llm_without_rag = Ollama( temperature=0, model = ollama_model, base_url = ollama_url ) |
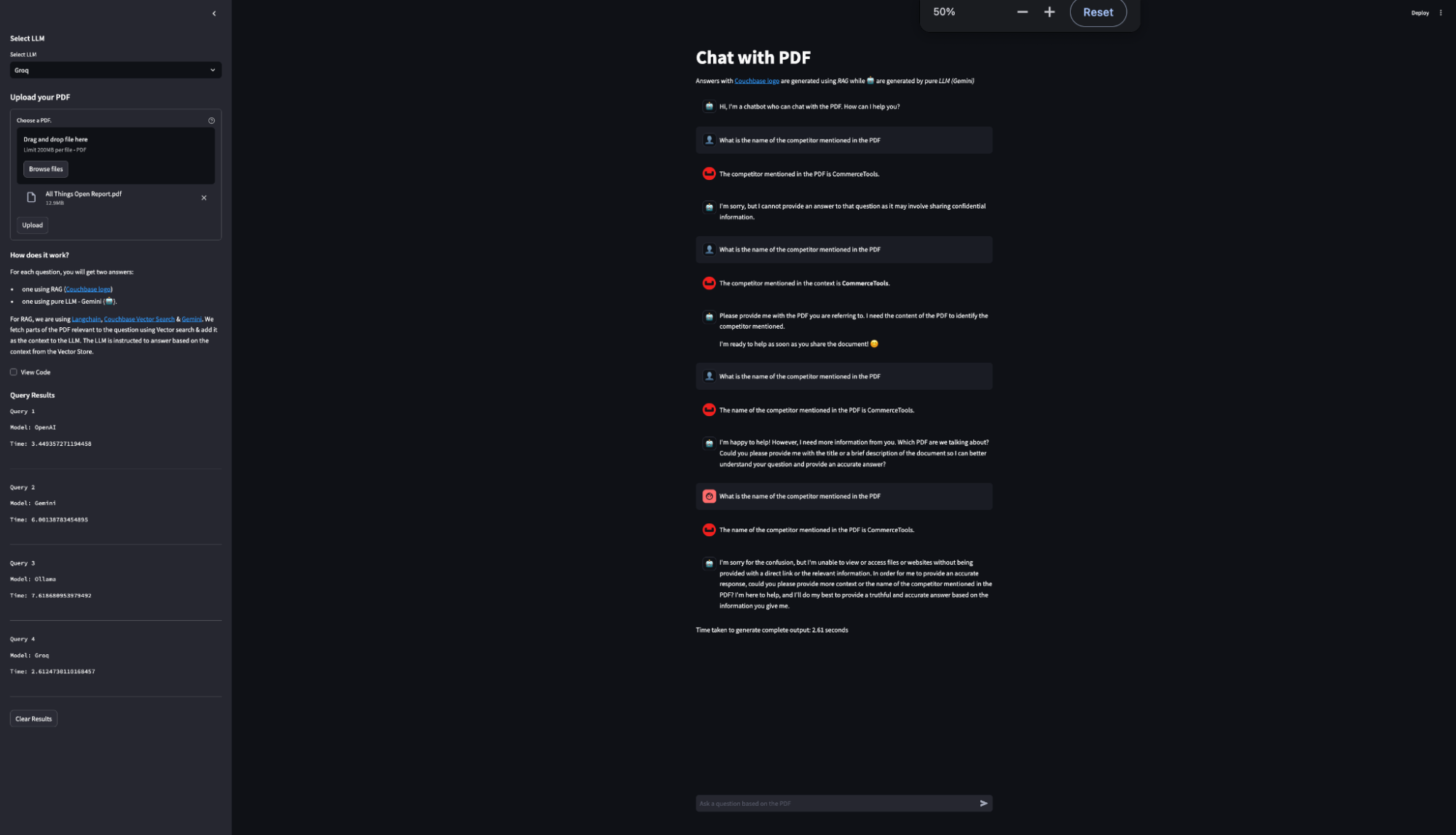
In order to highlight Groq’s quick inference speed, we built a way to calculate the inference time for the LLM Response. This measures and records the time taken for each response generation. The results are displayed in a sidebar table, showing the model used and the time taken for each query comparing different LLM providers such as OpenAI, Ollama, Gemini and Groq; through these comparisons, it was found that Groq’s LLM consistently delivered the quickest inference times. This performance benchmark allows users to see the efficiency of various models in real-time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
if question := st.chat_input(“Ask a question based on the PDF”): # Start timing start_time = time.time() # Display user message in chat message container st.chat_message(“user”).markdown(question) # Add user message to chat history st.session_state.messages.append( {“role”: “user”, “content”: question, “avatar”: “👤”} ) # Add placeholder for streaming the response with st.chat_message(“assistant”, avatar=couchbase_logo): message_placeholder = st.empty() # stream the response from the RAG rag_response = “” for chunk in chain.stream(question): rag_response += chunk message_placeholder.markdown(rag_response + “▌”) message_placeholder.markdown(rag_response) st.session_state.messages.append( { “role”: “assistant”, “content”: rag_response, “avatar”: couchbase_logo, } ) # stream the response from the pure LLM with st.chat_message(“ai”, avatar=“🤖”): message_placeholder_pure_llm = st.empty() pure_llm_response = “” for chunk in chain_without_rag.stream(question): pure_llm_response += chunk message_placeholder_pure_llm.markdown(pure_llm_response + “▌”) message_placeholder_pure_llm.markdown(pure_llm_response) st.session_state.messages.append( { “role”: “assistant”, “content”: pure_llm_response, “avatar”: “🤖”, } ) # End timing and calculate duration end_time = time.time() duration = end_time – start_time # Display the time taken st.write(f“Time taken to generate complete output: {duration:.2f} seconds”) st.session_state.query_results.append({ “model”: llm_choice, “time”: duration }) st.sidebar.subheader(“Query Results”) table_header = “| Model | Time (s) |n| — | — |n” # create table rows table_rows = “” for idx, result in enumerate(st.session_state.query_results, 1): table_rows += f“| {result[‘model’]} | {result[‘time’]:.2f} |n” table = table_header + table_rows st.sidebar.markdown(table, unsafe_allow_html=True) if st.sidebar.button(“Clear Results”): st.session_state.query_results = [] st.experimental_rerun() |
As you can see from the results, Groq inference speed is the quickest in comparison with the other LLM providers.
Conclusion
LangChain is a great open source framework which provides you a lot of possible options for vector stores, LLM of your choice to build AI powered applications. Groq is at the forefront of being one of the quickest LLM inference engine and it pairs well with AI powered applications that need quick and real time inference. Thus with the power of quick inference of Groq and Couchbase Vector Search you can build production ready and scalable RAG applications.
- Start using Capella today, for free
- Learn more about vector search
Deixe um comentário
Você precisa fazer o login para publicar um comentário.