
Intro
As most of you know, Couchbase is a database that provides users with a range of consistency and fault tolerance options to ensure that the state of their data meet certain criteria or guarantees. Users can specify varying levels of replication, persistence, replicas, sever groups, etc to guarantee that their data is durable, consistent, and correct under certain failure scenarios and cluster operations. For the upcoming 6.5.0 release, new enhanced durability levels will provide users with even more safety and guarantees in the event of failures. Since we recognize that guarantees are only as good as their proof, we’re going to give an in-depth look at how we use Jespen, an industry standard, to test database durability at Couchbase.
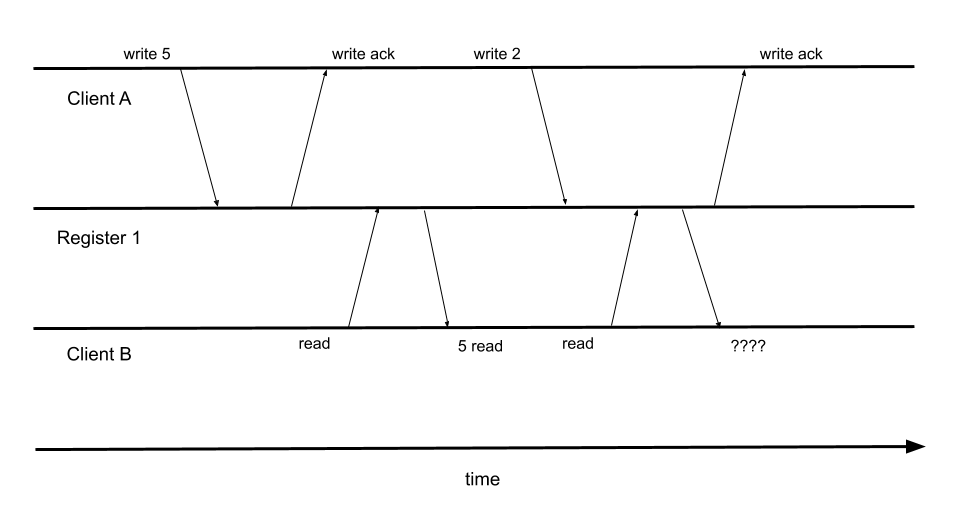
The Jepsen framework works by firing client operations at a cluster while concurrently injecting some sort of chaos like network partitions, killing process, slowing disks, etc. Jepsen will then analyze the operation history with built-in or custom operation history checkers. Most notably, Jepsen comes with a linearizable consistency checker. Couchbase, with the new enhanced durability levels in 6.5.0, only claims to be sequentially consistent. However, linearizable consistency implies sequential consistency [1]. Therefore, passing the linearizable consistency checker also implies that the operation history is indeed sequentially consistent. However, failing the linearizable consistency check does not imply that the operation history is not sequentially consistent. To summarize, when an operation passes the linearizable consistency checker, we can assume that Couchbase is sequentially consistent. If an operation fails the linearizable consistency checker, Couchbase may still be sequentially consistent, but further investigation is required to confirm.
Our goal with Jepsen is to test, from many different angles, that our Java SDK client and server-side KV engine work in unison to: 1.) Never lose acknowledged writes; and 2.) To provide, at a minimum, a sequential consistency model while cluster operations and failures are applied to the system.
Architecture
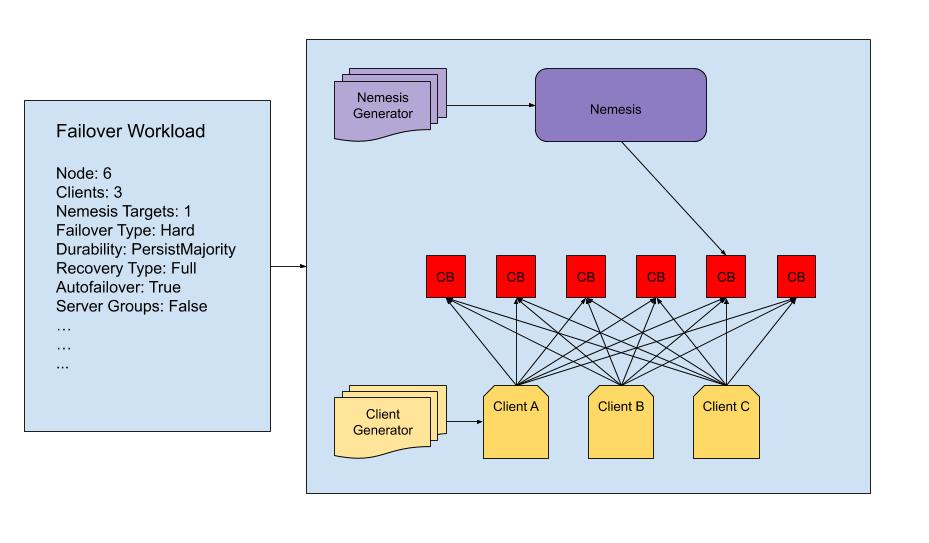
Jepsen provides interfaces for the following abstractions: Database, Client, Checker, Nemesis, Generators, and Workload. To create a Jepsen test, we had to implement all of these specifically for Couchbase. Each test is a combination of these abstractions and additional parameters.
Database
We implemented setup, teardown, and log collection logic for a Couchbase cluster. This logic includes support for custom bucket settings, server groups, and automatic failover. Full support for every possible bucket and cluster setting does not make much sense because the number of possible clusters will make testing all permutations infeasible. However, we built out support for all the most critical cluster configurations and options.
Client
We implemented two different clients: a “register” client and a “set” client. The register client will write, read, and compare-and-swap values from independent keys in a Couchbase bucket. The set client only adds and deletes documents from a bucket. You can think of the bucket as the set and the document as a member of that set. We use this client with a custom set checker instead of the linearizability checker since we are not updating any documents. Tests that use the set client and set checker all work by weaving phases of adding documents to a bucket or deleting documents from a bucket.
Both clients receive operations from a generator process. (More on that later.)
Special care must be taken to handle client errors. For example, a DurabilityImpossibleException and a RequestTimeoutException needs to be handled differently by Jepsen. In the former, we know the operation failed, but in the latter, the operation might have succeeded. In the case where we cannot distinguish if an operation has failed or succeeded, Jepsen’s linearizability checker will run a check assuming the operation failed and again assuming the operation passed. The effect of this is to roughly double check time for each ambiguous operation. Thus, we want test scenarios that limit the potential number of such operation results. The linearizability checker will pass if at least one of the two possible histories is linearizable.
Checker
For our tests, we have three checkers to choose from: linearizability checker, set checker, and sanity checker. The linearizability checker comes with Jepsen and is used to check the consistency of independent keys in a bucket. We implemented a set checker to ensure that tests with the set client have the correct set of documents in a bucket. Finally, we implemented a sanity checker that will ensure that the test itself went through the sequence of cluster state changes without error. For example, a test may involve a rebalance that fails when it should not. In this case the sanity checker will mark the test as “unknown” instead of “fail” since we are denoting failed tests as those that fail the set checker or linearizability checker. The sanity checker also ensures that at least some operations succeeded.
Nemesis
Traditionally in Jepsen, a nemesis is a process that will be fed operations from a generator process and then take action against the system accordingly. For instance, the built-in partition nemesis can receive a block and restore operation that will partition the network and restore the network between two nodes. Most of the built-in nemeses are sufficient for very basic scenarios, but we wanted to test additional scenarios that can, for example, slow a random disk in a random server group, kill the same server’s memcached process and finally restore the disk.
In order to test any scenario we want, we created a single Couchbase nemesis that models the Couchbase cluster via state changes from an initial state. We keep a map of nodes and their network, server, disk, and cluster state. Each time an operation occurs, the state is updated to reflect the change in the system. The operations passed to our nemesis specify node targeting options, an operation, and operation parameters. Node targeting options tell the nemesis, for example, to target a random node subset of size two from all the healthy nodes in a random server group. This is the main reason we track the node state — it gives us more flexibility in how our nemesis can take action.
Our nemesis has support for the following actions: failover (graceful and hard), recovery (full and delta), custom network partitioning, network recovery, waiting for automatic failover, rebalancing in a set of nodes, rebalancing out a set of nodes, swap rebalancing two sets of nodes, failing a rebalance, killing a process (memcached, babysitter, ns_server) on a set of nodes, restarting the same processes on a set of nodes, slowing dcp client, resetting dcp client, triggering compaction, failing a disk on a set of nodes, slowing a disk on a set of nodes, and recovering a disk on a set of nodes. We plan to support more nemesis operations in the future.
Generators
Another key piece of a Jepsen test are the generators for client and nemesis operations. These generators will create a finite or infinite sequence of operations. Each test will have its own nemesis generator, but most likely shares a common client generator. A nemesis generator, for instance, might be a sequence of partition, sleep, and restore, repeated infinitely. A client generator will specify a random, infinite sequence of client operation, as well as the associated parameters such as durability level, the document key, the new value to write or cas, etc. When a test starts, the client generator feeds client operations to the client and the nemesis generator feeds operations to the nemesis. The test will continue until either the nemesis generator has completed a specified number of operations, a time limit is reached, or an error is thrown.
Workload
A Jepsen workload is simply a map that ties all of the previous components together — along with any additional parameters — into a single test. Our workloads will modify the nemesis and client generator logic based on the input parameters, such as enabling server groups and automatic failover.
Challenges
There are two main challenges we encountered while building these tests, both of which stem from being resource constrained: 1.) The high number of cluster setting permutations; and 2.) The time required to run the linearizability checker.
Since Couchbase is a complex and highly customizable data platform, there are hundreds of settings to tweak. Some settings are binary (ex: automatic failover enabled), while others are continuous (RAM quota for KV). This creates an extremely high number of possible initial cluster states to test. Then, with the nearly infinite ways we could compose our nemesis operations, we have a test space that is too large to cover completely.
The linearizability checker, while super useful and a product of very good research, has some limitations. The time the checker takes to analyze a history grows exponentially with the number of operations. Furthermore, ambiguous operations cause exponential growth as well. So we have a problem: we want to push the clients as hard as we can for the duration of a test, but if we push the clients too hard, the checker may run out of memory and fail to analyze the history. This also means we want the tests to execute as fast as possible, but this will shrink the surface area for finding a bug.
Solutions
To work around these challenges, we decided to do the following: focus on a subset of test parameters that are most critical for our customers, keep the tests as short as possible, and run the tests as often as possible. By only testing common parameters such as bucket replicas, all the new enhanced durability levels, automatic failover, etc., we can focus on a manageable set of tests that will be a solid foundation for proving our durability guarantees.
We focused on critical KV configurations first, with plans to add new services and configurations (query, index, xdcr, etc.) as new features are added and at customer’s request. Next, we tuned our nemesis to operate as fast as possible by cutting down on sleep times, polling for operation statuses, limiting the number of operations, and having zero documents preloaded. Having empty buckets at the start of tests speeds up subsequent rebalances during the test. However, we do need to test scenarios where buckets have large amounts of data and relatively small amount of RAM per bucket. These high data density scenarios, which are in the works, will take much more time to run. We need to tune the initial data load size such that any rebalance operations will be fast enough to not cause the linearizability checker to run out of memory. Additionally, due to the rate limit of client operations, we need to run tests multiple times. With a slower client operation rate, there is a smaller probability of two operations overlapping or an operation happening at a buggy time, but if we run the test multiple times we can increase the total number of overlapping operations and hopefully expose a bug.
In order to run the tests as often as possible, we created a hierarchy of test suites. Our suites fall into four categories: sanity, daily, weekly, and full. The sanity test suite has a small subset of tests that should be run after new commits come in, and take less than one hour to complete. The larger daily suite should take no more than 12 hours to run and the weekly should finish within two days. The full test suite is a list of all tests and takes roughly one week to complete. To create the suites we cut down the full test suite by removing similar tests while keeping coverage at a maximum. Currently, our full suite has 612 tests, the weekly has 396, the daily has 227, and the sanity has 6 tests. We also have a suite for bugs in previous releases (4.6.x, 5.0.x, 5.5.x, 6.0.x) that we use to verify that they are no longer present in the product. Examples of these types of bugs are MB-29369 and MB-29480.
Results
Our Jepsen testing has been successful in finding several bugs within Couchbase. These bugs fall into two categories: general product bugs, and data durability and consistency bugs. The durability and consistency bugs are the reason why we began our Jepsen testing, so we consider these to be of more importance since we have a full functional regression suite that catches general product bugs. Some examples of durability and consistency bugs that we have found are MB-35135, MB-35060, and MB-35053.
Our initial Jepsen work and the bugs that it has helped us find have given us increased confidence in Couchbase’s ability to keep your data safe across a wide range of failure scenarios and cluster operations. Continuous testing is needed, however, as Jepsen may catch a bug after potentially hundreds of runs. We will continue to run our Jepsen tests on a daily and weekly basis, while building out support for more scenarios. Jepsen is an indispensable tool when building systems with data consistency and durability guarantees, and we will continue to utilize it and expand its capabilities.
Links:
[1] https://courses.csail.mit.edu/6.852/01/papers/p91-attiya.pdf
[3] https://jepsen.io/consistency/models/linearizable
[4] https://jepsen.io/consistency/models/sequential
[5] https://github.com/jepsen-io/jepsen
More Resources
Download
Documentation
Couchbase Server 6.5 Release Notes
Couchbase Server 6.5 What’s New
Blogs
Blog: Announcing Couchbase Server 6.5 GA – What’s New and Improved
Blog: Couchbase brings Distributed Multi-document ACID Transactions to NoSQL
Leave a comment
You must be logged in to post a comment.