Com tantos LLMs sendo lançados, muitas empresas estão se concentrando em aumentar as velocidades de inferência de modelos de linguagem grandes com hardware especializado e otimizações para poder dimensionar os recursos de inferência desses modelos. Uma dessas empresas que está fazendo grandes avanços nesse espaço é a Groq.
Nesta postagem do blog, exploraremos o Groq e como integrar os recursos rápidos de inferência LLM do Groq com o Couchbase Vector Search para criar aplicativos RAG rápidos e eficientes. Também compararemos o desempenho de diferentes soluções LLM, como OpenAI e Gemini, e como elas se comparam às velocidades de inferência do Groq.
O que é o Groq?
A Groq, Inc. é uma empresa americana de tecnologia especializada em inteligência artificial, particularmente conhecida por seu desenvolvimento da Unidade de Processamento de Linguagem (LPU), um circuito integrado de aplicativo específico (ASIC) projetado para acelerar as tarefas de inferência de IA. Ele foi projetado especificamente para aprimorar Modelos de linguagem grandes (LLMs) com recursos de inferência de latência ultrabaixa. As APIs do Groq Cloud permitem que os desenvolvedores integrem LLMs de última geração, como o Llama3 e o Mixtral 8x7B, em seus aplicativos.
O que isso significa para os desenvolvedores? Significa que as APIs do Groq podem ser perfeitamente integradas a aplicativos que exigem processamento de IA em tempo real com necessidades de inferência rápida.
Como começar a usar as APIs do Groq
Para aproveitar o poder das APIs do Groq, a primeira etapa é gerar uma chave de API. Esse é um processo simples que começa com a inscrição no console do Groq Cloud.
Depois de se inscrever, navegue até a página Chaves de API seção. Aqui, você terá a opção de criar uma nova chave de API.

A chave de API permitirá que você integre modelos de linguagem grandes e de última geração, como Llama3 e Mixtral em seus aplicativos. Em seguida, integraremos o modelo de bate-papo do Groq com LangChain em nosso aplicativo.
Usando o Groq como LLM
Você pode aproveitar a API do Groq como um dos provedores de LLM no LangChain:
|
1 2 3 4 5 6 |
de langchain_groq importação ChatGroq lm = ChatGroq( temperatura=0.3, nome_do_modelo="mixtral-8x7b-32768", ) |
Quando você instanciar o ChatGroq você pode passar a temperatura e o nome do modelo. Você pode dar uma olhada no objeto modelos atualmente suportados no Groq.
Criação de aplicativo RAG com Couchbase e Groq
O objetivo é criar um aplicativo de bate-papo que permita aos usuários fazer upload de PDFs e conversar com eles. Usaremos o Couchbase Python SDK e o Streamlit para facilitar o upload de PDFs para o Couchbase VectorStore. Além disso, exploraremos como usar o RAG para responder a perguntas baseadas em contexto a partir de PDFs, tudo isso com a tecnologia Groq.
Você pode seguir as etapas mencionadas em este tutorial sobre como configurar um aplicativo Streamlit RAG alimentado pelo Couchbase Vector Search. Neste tutorial, usamos o Gemini como LLM. Substituiremos a implementação do Gemini pelo Groq.
Comparação do desempenho do Groq
Neste blog, também comparamos o desempenho de diferentes provedores de LLM. Para isso, criamos um menu suspenso para que o usuário possa selecionar o provedor de LLM que deseja usar para o aplicativo RAG. Neste exemplo, estamos usando Gemini, OpenAI, Ollama e Groq como os diferentes provedores de LLM. Há um grande lista de provedores de LLM suportados pelo LangChain.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
st.barra lateral.subtítulo("Selecione LLM") llm_choice = st.barra lateral.caixa de seleção( "Selecione LLM", [ "OpenAI", "Groq", "Gêmeos", "Ollama" ] ) se llm_choice == "Gêmeos": check_environment_variable("GOOGLE_API_KEY") lm = GoogleI Gerativa( temperatura=0.3, modelo="models/gemini-1.5-pro", ) llm_without_rag = GoogleI Gerativa( temperatura=0, modelo="models/gemini-1.5-pro", ) elif llm_choice == "Groq": check_environment_variable("GROQ_API_KEY") lm = ChatGroq( temperatura=0.3, nome_do_modelo="mixtral-8x7b-32768", ) llm_without_rag = ChatGroq( temperatura=0, nome_do_modelo="mixtral-8x7b-32768", ) elif llm_choice == "OpenAI": check_environment_variable("OPENAI_API_KEY") lm = ChatOpenAI( temperatura=0.3, modelo="gpt-3.5-turbo", ) llm_without_rag = ChatOpenAI( temperatura=0, modelo="gpt-3.5-turbo", ) elif llm_choice == "Ollama": lm = Ollama( temperatura=0.3, modelo = ollama_model, base_url = ollama_url ) llm_without_rag = Ollama( temperatura=0, modelo = ollama_model, base_url = ollama_url ) |
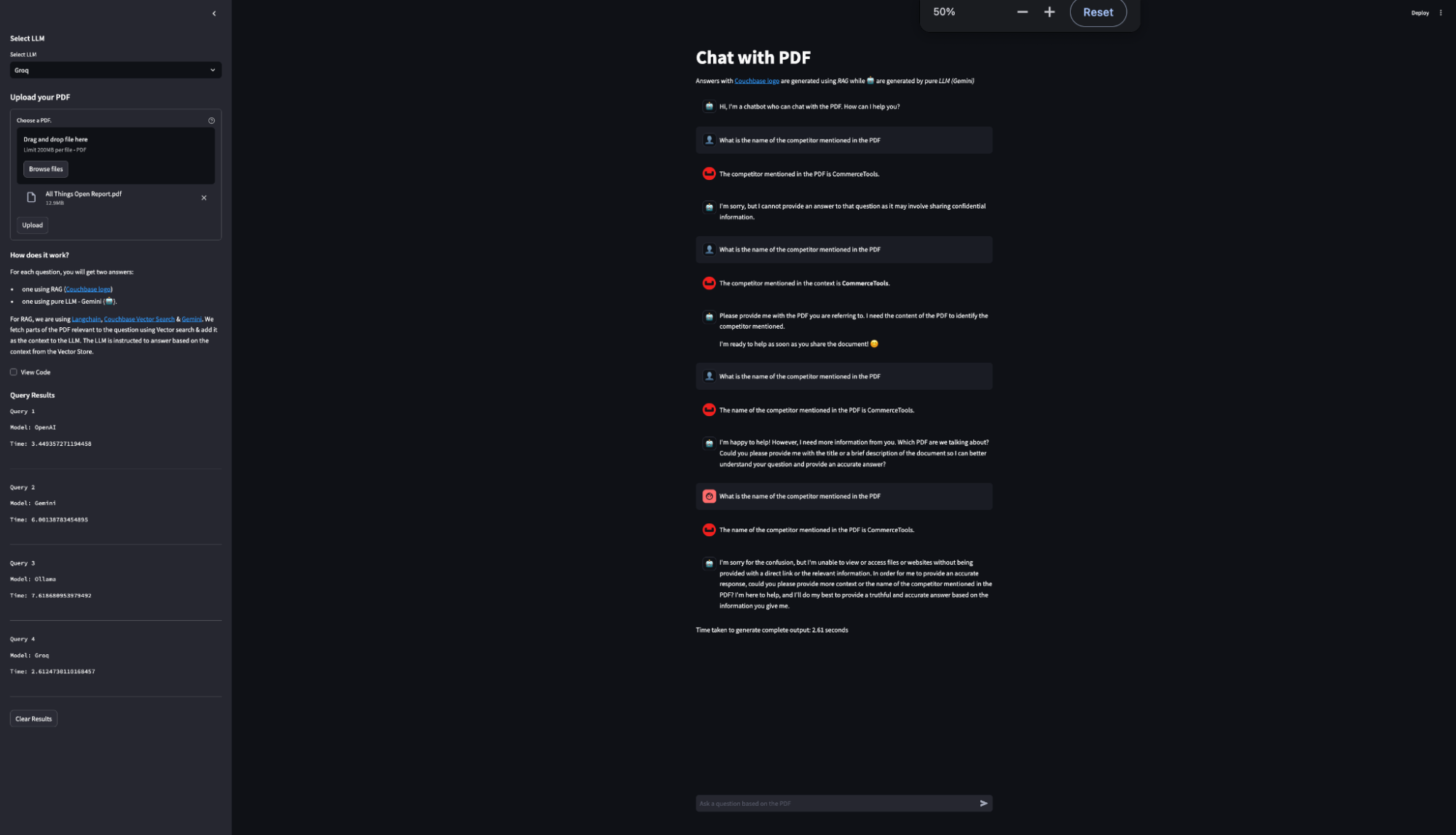
Para destacar a velocidade de inferência rápida do Groq, criamos uma maneira de calcular o tempo de inferência para a resposta LLM. Isso mede e registra o tempo gasto para cada geração de resposta. Os resultados são exibidos em uma tabela na barra lateral, mostrando o modelo usado e o tempo gasto para cada consulta, comparando diferentes provedores de LLM, como OpenAI, Ollama, Gemini e Groq; por meio dessas comparações, verificou-se que o LLM da Groq forneceu consistentemente os tempos de inferência mais rápidos. Essa referência de desempenho permite que os usuários vejam a eficiência de vários modelos em tempo real.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
se pergunta := st.entrada_de_chat("Faça uma pergunta com base no PDF"): # Tempo de início hora_inicial = tempo.tempo() # Exibir mensagem do usuário no contêiner de mensagens do bate-papo st.chat_message("usuário").remarcação para baixo(pergunta) # Adicionar mensagem do usuário ao histórico do bate-papo st.estado da sessão.mensagens.anexar( {"função": "usuário", "content" (conteúdo): pergunta, "avatar": "👤"} ) # Adicionar espaço reservado para transmitir a resposta com st.chat_message("assistente", avatar=logotipo da couchbase): message_placeholder = st.vazio() # transmitir a resposta do RAG rag_response = "" para pedaço em cadeia.fluxo(pergunta): rag_response += pedaço message_placeholder.remarcação para baixo(rag_response + "▌") message_placeholder.remarcação para baixo(rag_response) st.estado da sessão.mensagens.anexar( { "função": "assistente", "content" (conteúdo): rag_response, "avatar": logotipo da couchbase, } ) # transmite a resposta do LLM puro com st.chat_message("ai", avatar="🤖"): message_placeholder_pure_llm = st.vazio() pure_llm_response = "" para pedaço em chain_without_rag.fluxo(pergunta): pure_llm_response += pedaço message_placeholder_pure_llm.remarcação para baixo(pure_llm_response + "▌") message_placeholder_pure_llm.remarcação para baixo(pure_llm_response) st.estado da sessão.mensagens.anexar( { "função": "assistente", "content" (conteúdo): pure_llm_response, "avatar": "🤖", } ) # Finalizar a cronometragem e calcular a duração end_time = tempo.tempo() duração = end_time - iniciar_tempo # Exibir o tempo gasto st.escrever(f"Tempo necessário para gerar a saída completa: {duration:.2f} seconds") st.estado da sessão.resultados_da_consulta.anexar({ "model" (modelo): llm_choice, "tempo": duração }) st.barra lateral.subtítulo("Resultados da consulta") cabeçalho_da_tabela = "| Modelo | Tempo (s) |\n| --- | --- |\n" # criar linhas de tabela linhas_da_tabela = "" para idx, resultado em enumerar(st.estado da sessão.resultados_da_consulta, 1): linhas_da_tabela += f"| {result['model']} | {result['time']:.2f} |\n" tabela = cabeçalho_da_tabela + tabela_linhas st.barra lateral.remarcação para baixo(tabela, não seguro_permitir_html=Verdadeiro) se st.barra lateral.botão("Resultados claros"): st.estado da sessão.resultados_da_consulta = [] st.experimental_rerun() |
Como você pode ver nos resultados, a velocidade de inferência do Groq é a mais rápida em comparação com os outros provedores de LLM.
Conclusão
A LangChain é uma excelente estrutura de código aberto que oferece muitas opções possíveis para armazenamentos de vetores e LLM de sua escolha para criar aplicativos com tecnologia de IA. O Groq está na vanguarda por ser um dos mecanismos de inferência LLM mais rápidos e combina bem com aplicativos alimentados por IA que precisam de inferência rápida e em tempo real. Assim, com o poder de inferência rápida do Groq e do Couchbase Vector Search, você pode criar aplicativos RAG prontos para produção e dimensionáveis.
-
- Comece a usar o Capella hoje mesmo, de graça
- Saiba mais sobre pesquisa vetorial
