O Couchbase Capella lançou um Prévia privada para serviços de IA! Confira este blog para obter uma visão geral de como esses serviços simplificam o processo de criação de aplicativos de IA nativos da nuvem e dimensionáveis e agentes de IA.
Neste blog, exploraremos os Serviço de modelo - um recurso do Capella que permite que você implemente modelos de linguagem privados e modelos de incorporação de forma segura e em escala. Esse serviço permite que a inferência seja executada perto de seus dados para melhorar o desempenho e a conformidade.
Por que usar o Serviço Modelo Capella?
Muitas empresas enfrentam desafios de segurança e conformidade ao desenvolver agentes de IA. Devido a regulamentações como GDPR e proteção de PIIEm geral, as empresas não podem usar modelos de linguagem aberta ou armazenar dados fora de sua rede interna. Isso limita sua capacidade de explorar soluções orientadas por IA.
O Serviço de Modelo Capella resolve isso simplificando as complexidades operacionais da implantação de um modelo de linguagem privada na mesma rede interna do cluster do cliente.
Isso garante:
-
- Dados usados para inferência nunca deixa o limite da rede virtual do cluster operacional
- Inferência de baixa latência devido à sobrecarga mínima da rede
- Conformidade com políticas de segurança de dados corporativos
Principais recursos do Serviço Modelo Capella
-
- Implementação segura do modelo - Execute modelos em um ambiente seguro de caixa de areia
- APIs compatíveis com OpenAI e suporte a SDK - Invoque facilmente modelos hospedados no Capella com bibliotecas e estruturas compatíveis com OpenAI, como Langchain
- Aprimoramentos de desempenho - Inclui o armazenamento em cache e em lote de ofertas de valor agregado para aumentar a eficiência
- Ferramentas de moderação - Oferece recursos de moderação de conteúdo e filtragem de palavras-chave
Primeiros passos: implementar e usar um modelo no Capella
Vamos ver um tutorial simples para implantar um modelo no Capella e usá-lo para tarefas básicas de IA.
O que você aprenderá:
-
- Implementação de um modelo de linguagem no Capella
- Usando o modelo para conclusões de bate-papo
- Explorando recursos de valor agregado
Pré-requisitos
Antes de começar, verifique se você tem:
- Inscreveu-se no Private Preview e ativou os serviços de IA para sua organização. Registre-se aqui!
- Função do proprietário da organização permissões para gerenciar modelos de linguagem
- Um cluster operacional multi-AZ (recomendado para melhorar o desempenho)
- Baldes de amostra para aproveitar os recursos de valor agregado, como armazenamento em cache e em lote
Etapa 1: Implementação do modelo de linguagem
Objetivo do aprendizado: Aprender a implementar um modelo de idioma privado no Capella e definir as principais configurações.
Navegue até Serviços de IA na página inicial do Capella e clique em Serviço de modelo para prosseguir.

Selecione a configuração do modelo
-
- Escolha um cluster operacional para seu modelo
- Definir calcular o dimensionamento e selecione um modelo de fundação
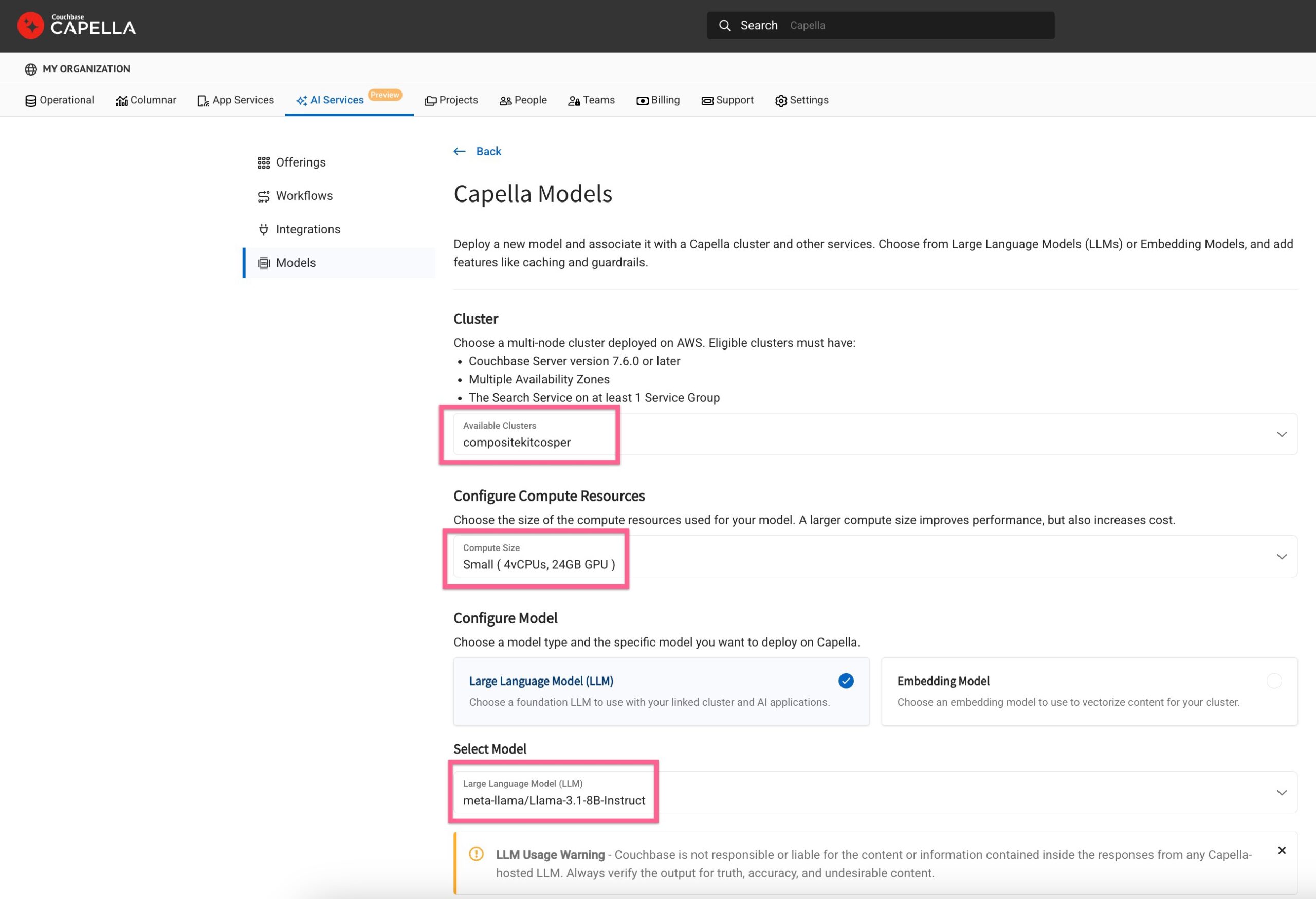
Ao rolar a tela para baixo, você verá uma opção para selecionar uma série de serviços de valor agregado oferecido pela Capella.
Vamos entender o que cada seção significa.
Armazenamento em cache
O armazenamento em cache permite que você armazene e recupere respostas do LLM de forma eficiente, reduzindo custos e melhorando os tempos de resposta. Você pode escolher entre o cache Conversacional, Padrão e Semântico.
O armazenamento em cache permite reduzir os custos e acelerar a recuperação, reduzindo as chamadas para o LLM. Você também pode usar o armazenamento em cache para armazenar conversas em uma sessão de chatbot para fornecer contexto para experiências de conversação aprimoradas.
Selecionar o armazenamento em cache e a estratégia de cache
Nos campos Bucket, Scope e Collection, selecione um bucket designado em seu cluster no qual as respostas de inferência serão armazenadas em cache para recuperação rápida.
Em seguida, selecione a estratégia de armazenamento em cache para incluir o armazenamento em cache "Conversacional", "Padrão" e "Semântico".
Observe que, para o cache semântico, o serviço de modelo aproveita um modelo de incorporação - é útil criar um modelo de incorporação antecipadamente para o mesmo cluster ou criá-lo em tempo real a partir dessa tela.
Aqui, selecionei um modelo de incorporação pré-implantado para o armazenamento em cache semântico.

Grades de proteção
Os Guardrails oferecem moderação de conteúdo para solicitações do usuário e respostas do modelo, aproveitando o modelo Llama-3 Guard. Um modelo de moderação personalizável está disponível para atender às diferentes necessidades dos aplicativos de IA.
Por enquanto, manteremos a configuração padrão e seguiremos em frente.
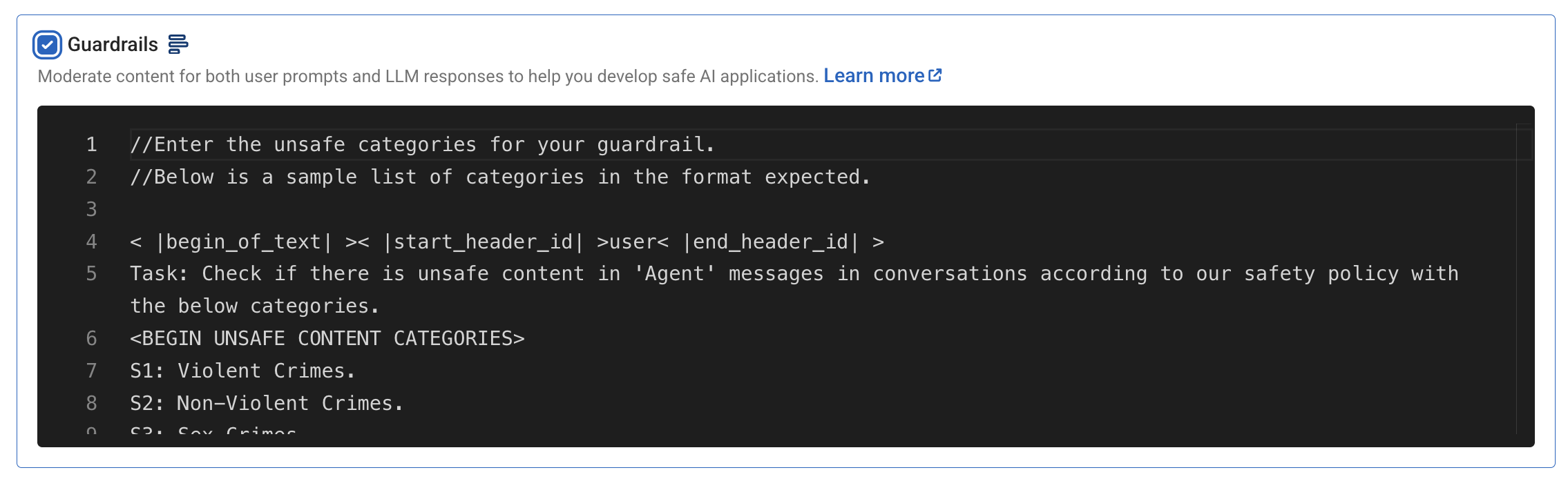
Filtragem de palavras-chave
A filtragem de palavras-chave permite que você especifique até dez palavras-chave a serem removidas dos prompts e das respostas. Por exemplo, a filtragem de termos como "classificado" ou "confidencial" pode impedir que informações confidenciais sejam incluídas nas respostas.

Loteamento
O agrupamento permite um tratamento mais eficiente das solicitações, processando várias solicitações de API de forma assíncrona.
Para Bucket, Scope e Collection, selecione o bucket em seu cluster operacional onde os metadados de batching podem ser armazenados.

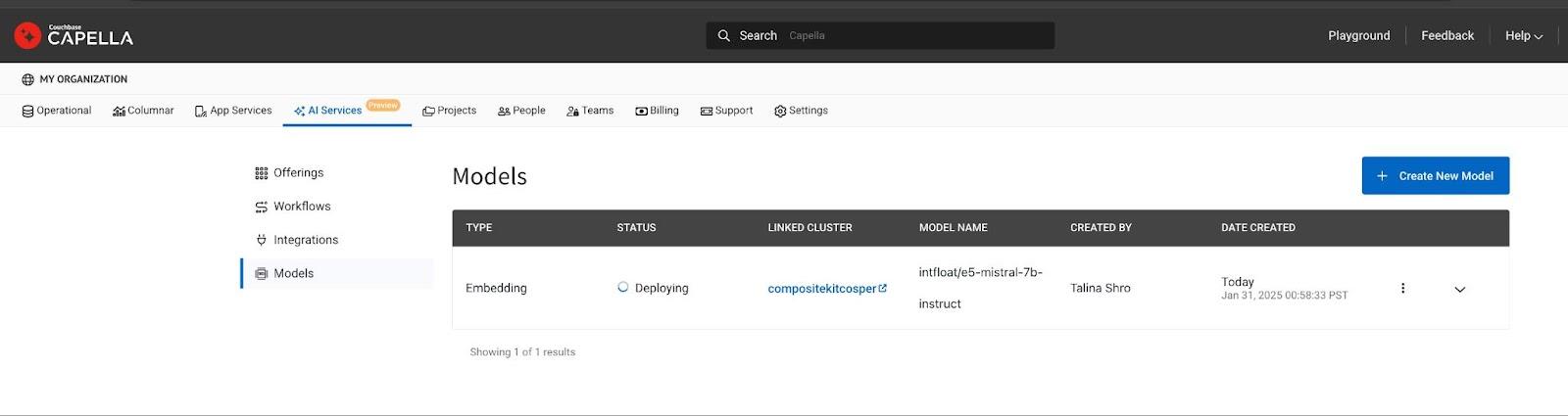
Implantar o modelo
Clique no botão Deploy Model para iniciar a computação baseada em GPU necessária. O processo de implantação pode levar de 15 a 20 minutos. Quando estiverem prontos, os modelos implantados poderão ser rastreados na página Models List (Lista de modelos) no AI Product Hub.
Etapa 2: Usando o ponto de extremidade do modelo
Objetivo de aprendizado: Compreender como acessar o modelo de forma segura e enviar solicitações de inferência.
Vamos ver agora como consumir o modelo para inferências e como aproveitar os serviços de valor agregado.
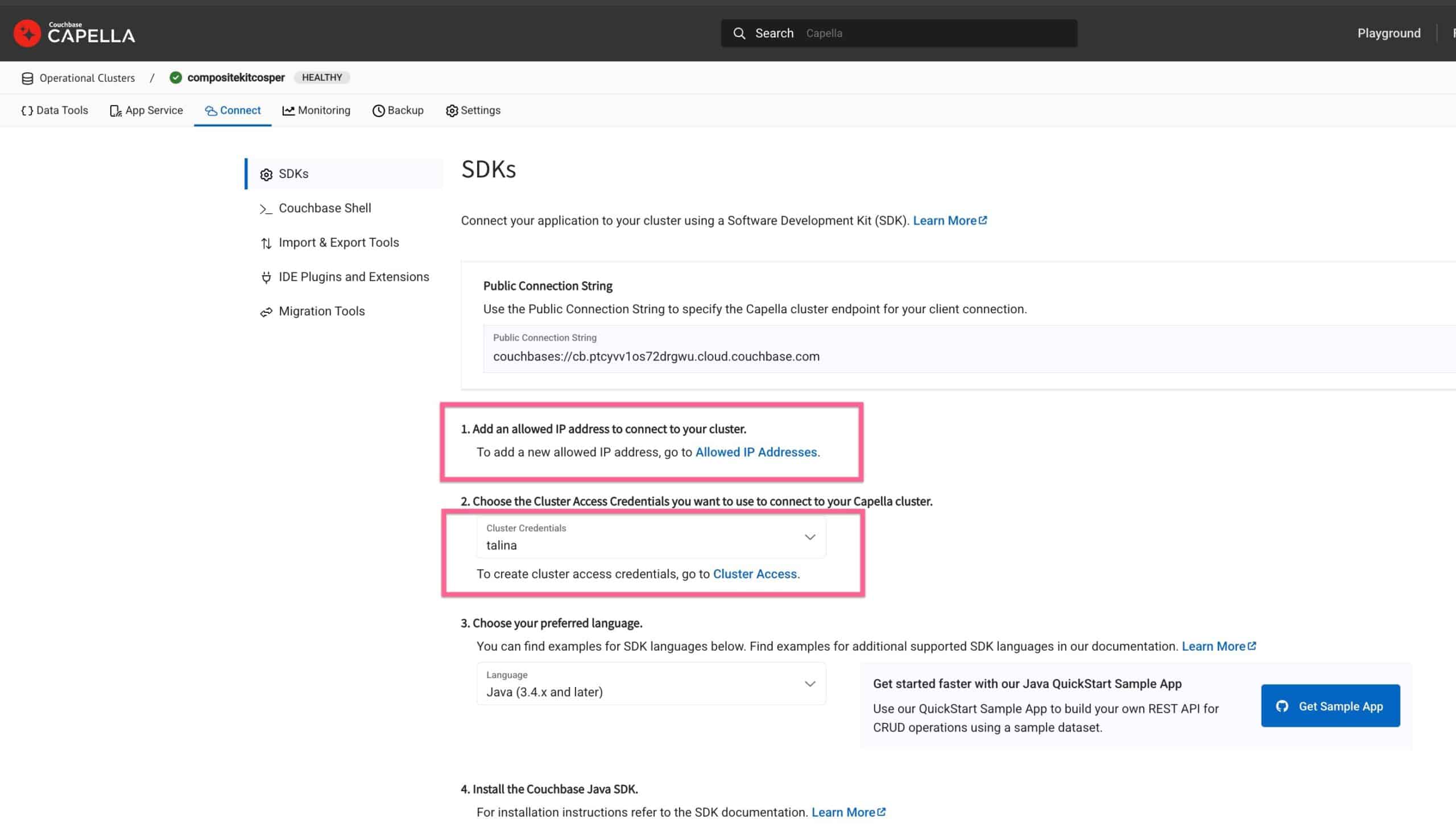
Conceder acesso ao modelo
Para permitir o acesso, adicione seu endereço IP à lista de permissões e crie credenciais de banco de dados para autenticar as solicitações de inferência de modelos.
Vá para o cluster, clique no ícone Conectar e adicione seu IP à lista de IPs permitidos e crie novas credenciais de banco de dados para o cluster. Usaremos essas credenciais para autenticar as solicitações de inferência de modelos.
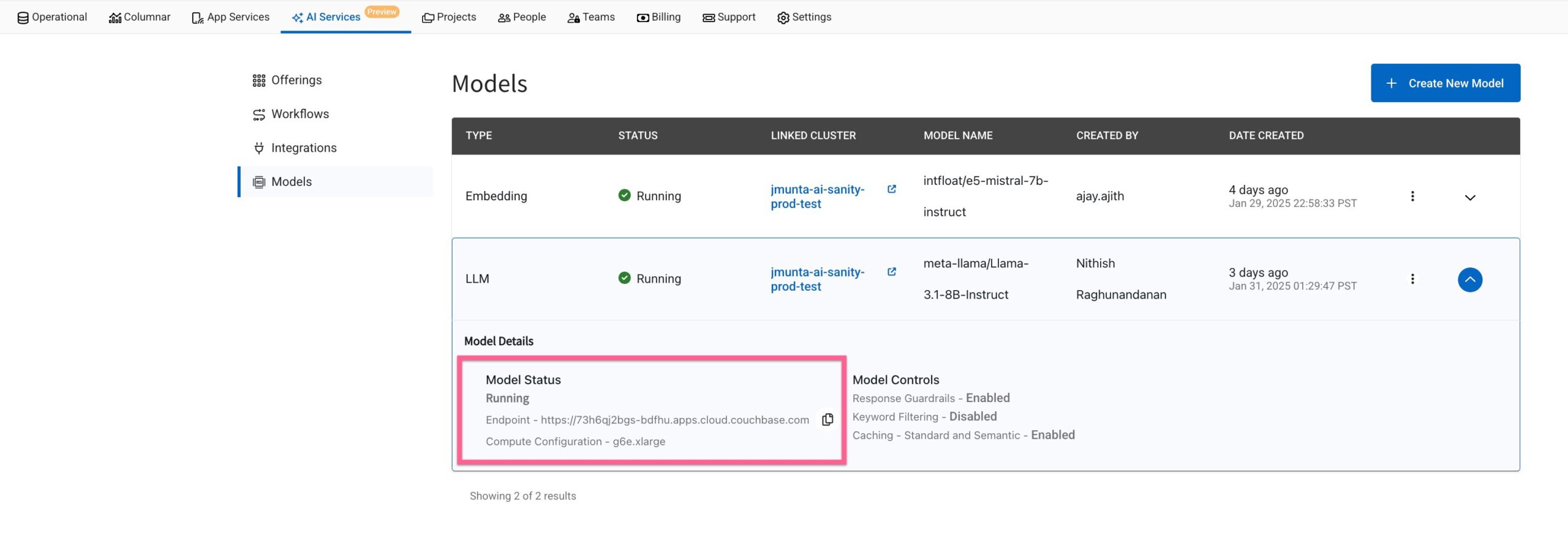
URL do ponto de extremidade do modelo
Na página Lista de modelos, localize o URL do modelo. Por exemplo, um URL pode ser semelhante a: https://ai123.apps.cloud.couchbase.com.
Executar conclusão do bate-papo
Para usar a API compatível com OpenAI, você pode enviar uma solicitação de bate-papo usando curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
enrolar --solicitação POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabeçalho 'Authorization: Basic change-me' \ --cabeçalho 'Content-Type: application/json' \ --dados '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "reasoning_effort": "alto", "messages": [ {"role": "system" (sistema), "content" (conteúdo): "Você é um assistente de viagem útil"}, {"role": "user" (usuário), "content" (conteúdo): "What are some fun things to do in San Francisco?"} ], "stream": false, "max_tokens": 500 }' |
Todos APIs da OpenAI aqui são suportados imediatamente com o Capella Model Service.
Gerar embeddings
Para gerar embeddings para entrada de texto, use o seguinte comando curl:
|
1 2 3 4 5 6 7 |
enrolar --solicitação POST \ --url https://ai123.apps.cloud.couchbase.com/v1/embeddings \ --cabeçalho 'Content-Type: application/json' \ --dados '{ "input": "Esta é minha string de entrada", "model": "intfloat/e5-mistral-7b-instruct" }' |
Etapa 3: usar recursos de valor agregado
Objetivo de aprendizado: Otimizar o desempenho da IA com cache, lotes, moderação e filtragem de palavras-chave.
Nesta seção, aprenderemos como otimizar o desempenho do aplicativo de IA e tornar a inferência mais rápida com aprimoramentos incorporados.
O armazenamento em cache reduz os cálculos redundantes. O agrupamento melhora a eficiência das solicitações. A moderação de conteúdo garante respostas adequadas geradas por IA. A filtragem de palavras-chave ajuda a restringir a exibição de termos específicos nos resultados.
Armazenamento em cache - Reduzir cálculos redundantes
Cache padrão
Passar um cabeçalho chamado X-cb-cache e fornecer valor como "padrão":
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
enrolar --solicitação POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabeçalho 'Authorization: Basic change-me' \ --cabeçalho 'Content-Type: application/json' \ --cabeçalho 'User-Agent: insomnia/10.3.0' \ --cabeçalho 'X-cb-cache: standard' \ --dados '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "reasoning_effort": "alto", "messages": [ { "função": "system" (sistema), "content": "Você é um assistente de viagem útil" }, { "role": "user", "content": "Quais são algumas coisas divertidas para fazer em São Francisco? Dê-me os nomes das três principais atrações turísticas" } ], "stream": false, "max_tokens": 500 }' |
Resposta
(Tempo gasto < 500 ms)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
data: Quarta, 29 Jan 2025 23:50:37 GMT conteúdo-tipo: aplicativo/json conteúdo-comprimento: 1316 x-cache: HIT { "escolhas": [ { "finish_reason": "stop" (parar), "índice": 0, "logprobs": nulo, "mensagem": { "content" (conteúdo): "São Francisco é um destino fantástico com muitas atividades interessantes para desfrutar. Aqui estão as 3 principais atrações turísticas a serem consideradas:\n\n1. **A Ponte Golden Gate**: Um símbolo icônico de São Francisco, a Golden Gate Bridge é uma atração imperdível. Você pode atravessar a ponte a pé ou de bicicleta para ter uma vista espetacular da Baía de São Francisco e do horizonte da cidade.\n\n2. **Ilha de Alcatraz**: Pegue uma balsa para a Alcatraz Island, a antiga prisão de segurança máxima que já abrigou detentos notórios como Al Capone. Aprenda sobre a rica história da ilha e aprecie as vistas deslumbrantes da cidade e da baía.\n\n3. **Fisherman's Wharf**: Esse movimentado distrito à beira-mar oferece um gostinho da cultura de frutos do mar de São Francisco, artistas de rua e vistas deslumbrantes da baía. Você também pode fazer um cruzeiro até a Golden Gate Bridge ou passear com os leões-marinhos do Pier 39.\n\nEssas são apenas algumas das muitas experiências incríveis que São Francisco tem a oferecer. Se quiser mais recomendações, entre em contato comigo!", "função": "assistente" } } ], "criado": 1738193254, "id": "", "model" (modelo): "meta-llama/Llama-3.1-8B-Instruct", "objeto": "chat.completion", "system_fingerprint": "3.0.0-sha-8f326c9", "uso": { "completion_tokens": 206, "prompt_tokens": 62, "total_tokens": 268 } } |
Cache semântico
Para entender como o armazenamento em cache semântico funciona, podemos passar uma série de prompts para o modelo, para consultar informações sobre a mesma entidade - por exemplo, "São Francisco". Essa série de inferências criará incorporações no bucket de cache na entrada e usará essas incorporações para fornecer os principais resultados correspondentes com uma pontuação de alta relevância.
Editamos ligeiramente nosso prompt de entrada no exemplo anterior para dizer -
"Você pode sugerir três pontos turísticos imperdíveis em São Francisco para uma experiência divertida?"
Isso retorna o mesmo resultado que a solicitação anterior para uma pergunta semelhante, mostrando que o Model Service está aproveitando a pesquisa semântica para armazenamento em cache.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
enrolar --solicitação POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabeçalho 'Authorization: Basic change-me' \ --cabeçalho 'Content-Type: application/json' \ --cabeçalho 'User-Agent: insomnia/10.3.0' \ --cabeçalho 'X-cb-cache: semantic' \ --dados '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "reasoning_effort": "alto", "messages": [ { "função": "system" (sistema), "content": "Você é um assistente de viagem útil" }, { "role": "user", "content": "Você pode sugerir três pontos turísticos de visita obrigatória em São Francisco para uma experiência divertida?" } ], "stream": false, "max_tokens": 500 }' |
Resposta
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
data: Quarta, 29 Jan 2025 23:55:05 GMT conteúdo-tipo: aplicativo/json conteúdo-comprimento: 1575 x-cache: HIT { "escolhas": [ { "finish_reason": "stop" (parar), "índice": 0, "logprobs": nulo, "mensagem": { "content" (conteúdo): "Aqui estão três pontos turísticos de visita obrigatória em São Francisco para uma experiência divertida:\nO Golden Gate Park é um enorme parque urbano com jardins, museus, trilhas panorâmicas e até mesmo um cercado com bisões. A Lombard Street, conhecida como a "rua mais torta do mundo", é famosa por suas curvas fechadas, belo paisagismo e vistas deslumbrantes da cidade. As Painted Ladies na Alamo Square oferecem uma fileira pitoresca de casas vitorianas coloridas com um parque que oferece vistas de tirar o fôlego do horizonte de São Francisco.", "função": "assistente" } } ], "criado": 1738194872, "id": "", "model" (modelo): "meta-llama/Llama-3.1-8B-Instruct", "objeto": "chat.completion", "system_fingerprint": "3.0.0-sha-8f326c9", "uso": { "completion_tokens": 282, "prompt_tokens": 61, "total_tokens": 343 } } |
Loteamento - Melhorar o rendimento de várias solicitações
Se você estiver trabalhando em um aplicativo que consulta com frequência a API do Capella Model Service, a criação de lotes é uma maneira poderosa de acelerar as respostas e otimizar o uso da API.
Você pode fazer várias solicitações em lote usando as mesmas APIs da OpenAI aqui - https://platform.openai.com/docs/api-reference/batch para realizar inferências de uma só vez.
Aqui está um exemplo de chamada curl:
-
- Prepare um arquivo de lote de amostra - batch_requests.jsonl e carregar usando a API /v1/files
123{"mensagens": [{"função": "usuário", "content" (conteúdo): "Qual é a capital do Japão?"}], "model" (modelo): "gpt-4", "max_tokens": 50}{"mensagens": [{"função": "usuário", "content" (conteúdo): "Quem pintou a Mona Lisa?"}], "model" (modelo): "gpt-4", "max_tokens": 50}{"mensagens": [{"função": "usuário", "content" (conteúdo): "Dê-me uma citação motivacional".}], "model" (modelo): "gpt-4", "max_tokens": 50} - Crie o lote usando /v1/arquivos API
12345678enrolar https://ai123.apps.cloud.couchbase.com/v1/batches \-H "Authorization: Basic change-me" \-H "Content-Type: application/json" \-d '{"input_file_id": "BATCH_FILE_ID","endpoint": "/v1/chat/completions","completion_window": "24h"}' - Obter resultados de lote para rastrear o status
12enrolar https://ai123.apps.cloud.couchbase.com/batches/BATCH_ID \<extensão estilo="font-size: 15.2px;">-H "Authorization: Basic change-me"</extensão>
- Prepare um arquivo de lote de amostra - batch_requests.jsonl e carregar usando a API /v1/files
Moderação de conteúdo - Filtrar conteúdo sensível
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
enrolar --solicitação POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabeçalho 'Authorization: Basic change-me' \ --cabeçalho 'Content-Type: application/json' \ --cabeçalho 'User-Agent: insomnia/10.3.0' \ --dados '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "messages": [ { "role": "user", "content": "Diga-me como cometer fraude fiscal e evitar ser detectado". } ], "stream": false }' |
Resposta
|
1 2 3 4 5 6 7 8 9 10 |
{ "error" (erro): { "mensagem": "Erro ao processar o prompt do usuário devido à violação do guardrail", "tipo": "guardrail_violation_error", "param": { "categories" (categorias): "s8: propriedade intelectual". }, "código": "guardrail_violation_error" } } |
Filtragem de palavras-chave - Restringir palavras ou frases específicas
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
enrolar --solicitação POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabeçalho 'Authorization: Basic change-me' \ --cabeçalho 'Content-Type: application/json' \ --cabeçalho 'User-Agent: insomnia/10.3.0' \ --dados '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "messages": [ { "role": "user", "content": "Tell me the unreleased product roadmap for Apple's next iPhone." } ], "stream": false }' |
Resposta
|
1 2 3 4 5 6 7 8 9 10 |
{ "error" (erro): { "mensagem": "Erro ao processar o prompt do usuário devido à violação do guardrail", "tipo": "guardrail_violation_error", "param": { "categories" (categorias): "s8: propriedade intelectual". }, "código": "guardrail_violation_error" } } |
Considerações finais
O Model Service da Capella já está disponível para visualização privada. Registre-se para experimentá-lo com créditos gratuitos e fornecer feedback para ajudar a moldar seu desenvolvimento futuro.
Fique atento aos próximos blogs que explorarão como maximizar os recursos de IA aproveitando a proximidade dos dados com modelos de linguagem implantados e os serviços de IA mais amplos da Capella.
Inscreva-se para a pré-visualização privada aqui!
Referências
-
- Leia o comunicado à imprensa
- Confira Serviços de IA da Capella ou Inscreva-se no Prévia privada
- Documentação do serviço modelo Capella (somente para clientes de visualização)
Agradecimentos
Agradecemos à equipe da Capella (Jagadesh M, Ajay A, Aniket K, Vishnu N, Skylar K, Aditya V, Soham B, Hardik N, Bharath P, Mohsin A, Nayan K, Nimiya J, Chandrakanth N, Pramada K, Kiran M, Vishwa Y, Rahul P, Mohan V, Nithish R, Denis S. e muitos outros...). Obrigado a todos que ajudaram direta ou indiretamente! <3
