Explicação do Flex Index
O que é um Flex Index? Uma das principais tarefas de um mecanismo de banco de dados é como gerenciar com eficiência a pesquisa e a recuperação dos dados nele contidos. A eficiência e o equilíbrio entre o consumo de recursos e o desempenho são os aspectos mais importantes de qualquer banco de dados. Diferentes tipos de índices de banco de dados, por exemplo, B-Tree, Inverted, Graph e Spatial, etc., são projetados para atender a diferentes requisitos de pesquisa. Embora os índices sejam essenciais para o desempenho da pesquisa, a escolha do tipo de índice adequado a ser usado também pode fazer uma grande diferença em sua eficácia. Porque o melhor tipo de índice é geralmente ditado pela característica do elemento de dados que está sendo indexado.
No Couchbase, o Índice Secundário Global usa uma estrutura B-Tree para pesquisa rápida exata e de intervalo, e a Pesquisa de Texto Completo usa a estrutura de índice invertido para fornecer pesquisa eficiente de termos. Além de ser altamente dimensionável, cada um desses tipos de índice também oferece seus próprios recursos exclusivos. O B-Tree é o índice mais comumente usado para valores de alta seletividade (ou seja, mais distintos, como número de pedido), enquanto os índices invertidos são mais bem utilizados para indexar conteúdo textual, em que o termo pesquisável provavelmente tem baixa seletividade.
Os aplicativos que interagem diretamente com os usuários precisam de recursos de pesquisa e, na maioria das vezes, esses aplicativos exigem tanto a pesquisa exata quanto a pesquisa de texto. Esses recursos de pesquisa geralmente estão disponíveis por meio de diferentes serviços de pesquisa e como APIs de pesquisa separadas, o que, por sua vez, pode aumentar a complexidade do desenvolvimento do aplicativo.
Para atender a essa necessidade, o Couchbase introduziu a função N1QL SEARCH() na versão 6.5. Ela permite que a consulta N1QL use tanto o predicado SQL para pesquisa exata e de intervalo quanto SEARCH() para pesquisa de texto, em que os resultados não são apenas predicados pelo termo de pesquisa, mas também por sua pontuação de relevância. Isso adiciona um fator de imprecisão à pesquisa, bem como recursos de reconhecimento de linguagem.
O recurso N1QL SEARCH(), pela primeira vez, permite que os aplicativos acessem ambos os serviços de pesquisa de consulta a partir de uma única API, usando a linguagem N1QL do Couchbase. Essa integração oferece muitas vantagens. A principal delas é a simplificação do processo de desenvolvimento de aplicativos por não precisar lidar com APIs diferentes, mas também por delegar mais do processamento de pesquisa aos serviços de back-end.
No Couchbase 6.6, levamos essa integração N1QL/FTS um passo adiante com Índice do Couchbase Flex.
O que é o Flex Index?
O índice flexível é um recurso do serviço de consulta do Couchbase para aproveitar os recursos de pesquisa, usando apenas o predicado N1QL padrão. Isso significa que você não precisa usar a sintaxe do FTS nem a função SEARCH() para que sua consulta N1QL aproveite os índices do FTS.
O suporte ao tipo de dados de pesquisa inclui texto, data e hora, numérico e booleano. Mas, para texto, somente a pesquisa por palavra-chave é suportada.
Pesquisa de palavras-chave - refere-se à maneira como um campo de texto é processado antes de ser adicionado a um índice. Índice FTS usando o padrão analisaria o texto em termos individuais antes da indexação, enquanto o analisador palavra-chave O analisador usa o texto inteiro para o índice.
Então, para entender como o Flex Index funciona, digamos que você tenha uma consulta com esta condição de pesquisa: Encontrar todas as atividades em um sistema de gerenciamento de atividades de vendas em que as atividades envolveram o cliente "Horizon Communications", aconteceram em agosto de 2020 e ocorreram durante um evento de marketing no Moscone Center.
|
1 2 3 4 5 |
SELECT * FROM crm WHERE type='activity' AND event.location = 'Moscone Center' AND account.name = 'Horizon Communications' AND act_date BETWEEN '2020-08-01' AND '2020-08-31' |
Suponha também que você tenha esse índice GSI :
|
1 2 3 |
CREATE INDEX adv_account_name_event_site_actdate ON `crm`(`account`.`name`,`event`.`location`,`act_date`) WHERE type='activity' |
Essa consulta, da forma como foi escrita, aproveitará o índice GSI acima porque:
- Todos os predicados de consulta são cobertos pelo índice.
- A consulta também tem o predicado
tipo='atividade' que corresponde ao filtro do índice. - De fato, o índice será considerado desde que a chave principal
conta.nomeé um dos predicados, e que a consulta é restrita atipo='atividade'.
Plano de consulta:

Com Índice FlexAgora, você tem a opção de solicitar que o serviço de consulta considere o uso do índice FTS para a consulta.
|
1 2 3 4 5 |
SELECT * FROM crm USE INDEX (USING FTS) WHERE type='activity' AND event.site = 'Moscone Center' AND account.name = 'Horizon Communications' AND act_date BETWEEN '2020-08-01' AND '2020-08-31' |
A adição do "ÍNDICE DE USO (USANDO FTS)A dica " sugere que o serviço de consulta considere o uso de qualquer índice FTS, se houver um disponível que possa ajudar na consulta.
E se você tiver um índice FTS definido como abaixo:
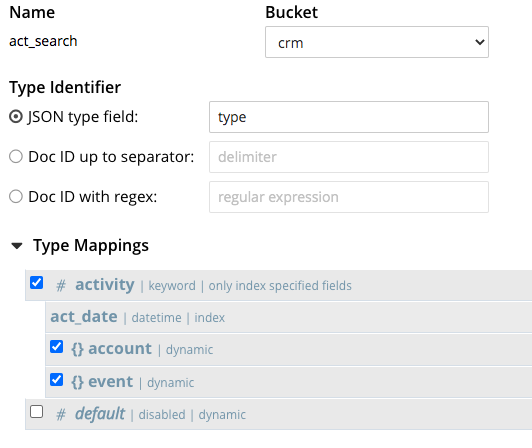
O act_search tem a seguinte definição:
- Ele tem um
tipoque restringe o conteúdo do índice para incluir apenas os documentos detipo= 'atividade'. - Ele inclui o campo filho
data_do_ato. - Ele inclui os dois mapeamentos filhos para
contaeeventoobjetos. - Observe que ele usa o
palavra-chaveanalisador.
Nesse caso, o act_search é perfeito para a consulta N1QL acima, e com o ÍNDICE DE USO (USANDO FTS) a consulta poderá usar a dica act_search Índice FTS.
Plano de consulta:

Em resumo, Índice do Couchbase Flex oferece a possibilidade de a consulta N1QL com a sintaxe de predicado N1QL padrão aproveitar de forma transparente o índice GSI ou FTS sem nenhuma modificação nos comandos N1QL.
Mas o valor do Flex Index não vem apenas com a sintaxe mais simples para usar o FTS, mas também com a versatilidade do índice FTS, alguns dos quais serão descritos nas seções subsequentes.
Então, quando você deve usar o Flex Index?
Em alto nível, Índice de flexibilidade pode resolver muitos desafios frequentemente encontrados em aplicativos que fornecem pesquisas.
- Onde as condições de pesquisa das instruções N1QL não são predeterminadas, o que significa que podem conter números variados de predicados, muitas vezes com base nas seleções do usuário. E é difícil criar índices para cobrir todas as condições de pesquisa.
- Aplicativos que fornecem recursos de pesquisa envolvendo um grande número de predicados, com operadores lógicos, como combinações AND/OR nas condições de pesquisa.
- Quando as condições de pesquisa envolvem predicados sobre elementos hierárquicos do documento, como a pesquisa que envolve elementos de matriz em uma matriz ou em várias matrizes.
- Quando os aplicativos exigem o poder do FTS, mas também precisam de agregação SQL e JOIN para incluir informações relacionadas de outros objetos.
- Ou você simplesmente deseja usar a sintaxe de predicado N1QL em vez da sintaxe FTS.
Observe que o Flex Index também pode ser usado retrospectivamente em aplicativos existentes, adicionando a opção use_fts para as chamadas de API de consulta.
1) Os padrões de pesquisa não são predeterminados
Quando se trata de fornecer recursos de pesquisa para os usuários finais, o desafio sempre foi saber o que permitir que o usuário pesquise. As diretrizes padrão determinam que a decisão seja tomada com base nas necessidades dos usuários. Porém, em sistemas complexos, em que os campos pesquisáveis geralmente não se limitam a alguns campos-chave, mas podem abranger todos os campos de um objeto, a decisão sobre a pesquisa geralmente é orientada pelo que o sistema de banco de dados subjacente pode suportar.
Os aplicativos que se baseiam no índice B-Tree tradicional para pesquisa rápida geralmente ficam aquém quando se trata de fornecer uma estrutura flexível para esse tipo de requisito de pesquisa.
Considere este documento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
"activity" : { "id": "act1000", "title": "Announcing Couchbase Flex Index CB6.6", "reference": "24-i2y5J3928", "dept": "st55", "region": "00528", "notes": "Review the 100 N1QL Flex Index queries that ElasticSQL cannot do. The important point here is that Couchbase has integrated Text Search capability into its N1QL. Whereas ElasticSearch, relatively new SQL, has added SQL to its search engine....", "owner": { "id": "usr24", "name": "John Higgins" }, "priority": "Medium", "act_type": "Appointment", "event": { "name": "N1QL Flex Index vs. ElasticSQL", "location": "Moscone Center", "theme": "CouchbaseRed", "vendor": "Kempinski" }, "account": { "id": "acc134", "name": "Horizon Communications" }, "act_date": "2020-08-06", "appointment": { "duration": 90, "start_date": "2020-08-06 11:00:00", "contacts": [ { "id": "contact2493", "title": "SalesRep", "name": "Miranda Sullivan", "email": "msullivan@horizoncell.com", "phone": "778-096-1351" } ], "participants": [ { "role": "Support Analyst", "userid": "usr57", "name": "Raven Peterson" }, { "role": "Product Specialist", "userid": "usr24", "name": "John Higgins" } ], "type": "activity" } |
Os 13 campos destacados são todos os campos possíveis que o usuário pode querer pesquisar. Então, qual seria a estratégia de índice se você quiser fornecer aos usuários o recurso de pesquisa?
| Estratégia de índice | Prós | Contras |
| Criar 13 índices individuais | 1-Eficiente para pesquisa de campo único. | 1-Se mais de um campo estiver na pesquisa, serão usados vários índices, resultando em varreduras de interseção, o que afetará o desempenho
2 - Cada vez mais ineficiente à medida que mais campos de pesquisa são incluídos |
| Criar um índice composto para combinações de pesquisa usadas com frequência | 1-Tempo de resposta rápido | 1-Inflexível, pois só há suporte para combinações de pesquisa específicas.
2-A interface do usuário do aplicativo precisa garantir que a chave principal do índice esteja presente. |
| Criar um índice composto para todas as combinações de pesquisa | 1-Tempo de resposta mais rápido | 1 - O número total de índices (13!) seria impraticável |
| Aproveitar o mecanismo de pesquisa - ElasticSearch ou Couchbase FTS | 1-Tempo de resposta rápido
2-Só é necessário um único índice |
1 - Necessidade de reescrever o aplicativo para aproveitar o mecanismo de pesquisa
2-Código de aplicativo mais complexo 3-Custo de manutenção |
A partir da lista de opções acima, fica claro que o recurso de pesquisa mais flexível exigirá o uso de um mecanismo de pesquisa, algo semelhante ao ElasticSearch ou ao Couchbase FTS. Mas, a menos que você tenha desenvolvido seu aplicativo especificamente com esses mecanismos de busca em mente, o esforço para converter a sintaxe de busca e a alteração das APIs não será trivial.
E é aí que o valor do Couchbase Flex Index entra em cena. Esse novo recurso permite que os desenvolvedores escrevam instruções de consulta N1QL usando predicados N1QL padrão, e o serviço de consulta aproveitará de forma transparente o índice FTS.
2) Consulta com qualquer combinação de predicados
Uma das principais diferenças entre o índice GSI B-Tree e o índice FTS Text é como os campos-chave são criados. O índice GSI B-Tree concatena todos os campos-chave do índice para formar a chave do nó, que é o principal motivo pelo qual uma chave principal deve estar presente na consulta antes que o índice possa ser considerado. O índice FTS, por outro lado, cria um índice invertido separado para cada campo. Esse design permite que um índice FTS seja considerado para qualquer consulta que tenha pelo menos um dos campos indexados.
Considere a seguinte consulta, que tem 13 predicados diferentes, bem como o predicado tipo='predicado de atividade.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM crm a WHERE a.type='activity' /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center South' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempskinki' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Communications' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'John Higgins' |
Para obter o melhor desempenho, você precisa ter um índice para a consulta, e o melhor índice a ser usado é um índice de cobertura, conforme fornecido pelo ADVISE:
|
1 2 3 4 5 |
CREATE INDEX adv_idx13 ON crm` (`account`.`name`,`event`.`vendor`,`account`.`id`,`event`.`location`, `event`.`theme`,`priority`,`owner`.`name`,`dept`,`event`.`name`, `owner`.`id`,`region`,`act_date`,`title`) WHERE `type` = 'activity' |
Plano de consulta:

No entanto, o que aconteceria se:
- A consulta não tem a chave principal
conta.nome? - A consulta tem uma combinação variável dos 13 predicados?
O GSI é o melhor índice a ser usado, desde que você conheça os predicados exatos da consulta. Entretanto, para aplicativos que precisam oferecer suporte a consultas ad hoc, em que o conjunto de predicados não pode ser predeterminado, é melhor considerar o uso do FTS.
Portanto, vamos considerar o seguinte índice FTS.
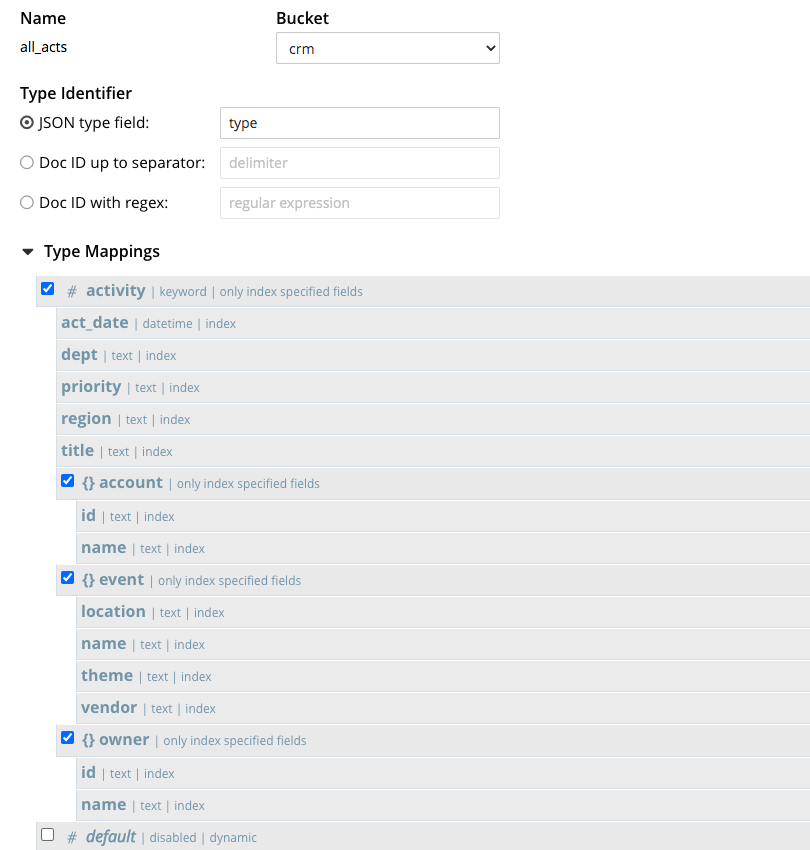
Observações:
- O índice contém um
tipopara especificar que somente os documentos com otipo= "atividade" será incluída no índice. Consulte este Mapeamentos de tipo FTS para obter mais informações. - O índice usa o analisador de palavras-chave, o que significa que o valor dos dados será adicionado ao índice em sua totalidade, sem ser analisado em termos individuais.
- Cada campo é indexado individualmente da mesma forma que o índice GSI. Todas as outras opções estão desmarcadas, pois não são relevantes para a pesquisa de palavras-chave. Consulte este Mapeamento de crianças FTS para obter mais informações.

Com esse índice FTS em vigor, a mesma consulta acima, mas com o USE INDEX (all_acts USING FTS) instruirá o serviço de consulta a considerar o uso do índice FTS. Observe que o nome do índice todos_atos é opcional.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM crm a WHERE a.type='activity' USE INDEX (USING FTS) /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempinski' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Cellular' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'John Higgins' |
Plano de consulta:

Execução de consultas:

Pontos importantes a serem observados: A consulta pode ter qualquer número variável de predicados e em qualquer combinação de campos, e a consulta ainda deve considerar o índice FTS.
3) Consulta de índice flexível com combinações de operadores lógicos - AND/OR
O benefício do índice FTS com relação às combinações de predicados também se estende ainda mais com a maneira como cada um dos campos de índice é criado. Como cada campo indexado tem sua própria estrutura invertida e como a rotina Bleve cria um mapa de bits para cada condição de pesquisa, as combinações de predicados, como AND/OR/NOT, são processadas com muito mais eficiência em comparação com o intersect-scan com índice B-Tree.
O exemplo abaixo mostra que, embora existam vários operadores lógicos OR na consulta, o operador todos_atos O índice FTS ainda está sendo considerado.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM crm a USE INDEX (USING FTS) WHERE a.type='activity' AND ( a.dept = 'iA88' OR a.region > '59416' ) AND a.priority = 'High' AND ( a.act_date BETWEEN '2018-01-01' AND '2018-08-31' OR a.event.location = 'Moscone Center' ) AND ( a.account.id = 'acc100' OR a.owner.name = 'Amanda Morrison') LIMIT 10 |
Plano de consulta:

Execução de consultas:
![]()
4) A consulta envolve vários predicados de matriz
A versatilidade do índice FTS não se limita à sua capacidade de usar o índice com apenas um subconjunto dos campos indexados na condição de pesquisa ou à sua capacidade de combinar eficientemente os resultados da pesquisa com operadores lógicos. Mas também a maneira como o índice FTS lida com elementos de matriz, o que permite que a consulta N1QL tenha qualquer número de predicados de matriz.
Agora vamos ampliar a consulta com predicados de matriz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
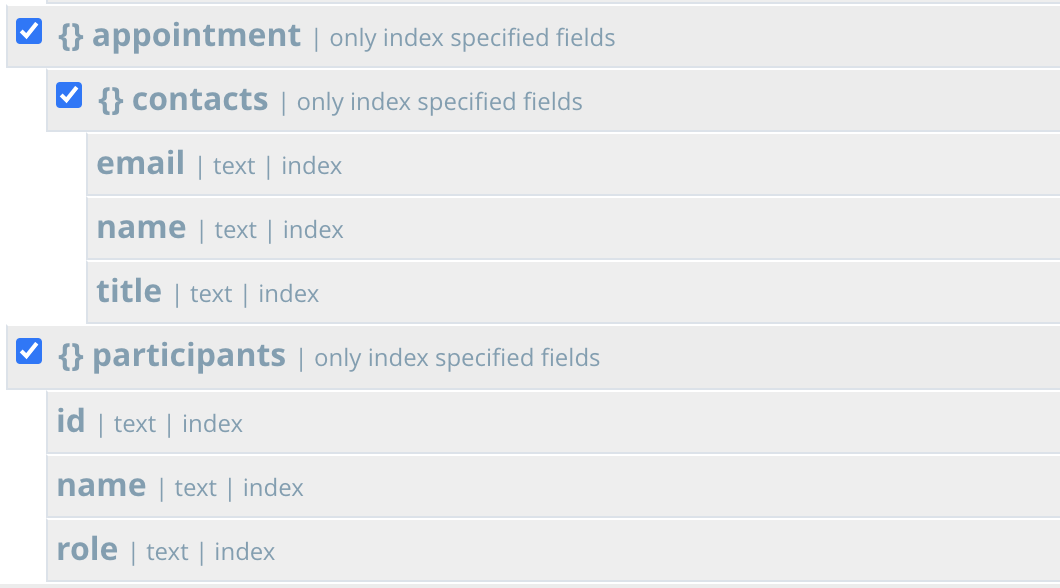
SELECT * FROM crm a WHERE a.type='activity' USE INDEX (USING FTS) /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center South' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempskinki' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Cellular' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'Binh Le' /* 14 */ AND ANY pa IN a.participants SATISFIES pa.name LIKE 'Randy%' END /* 15 */ AND ANY co IN a.appointment.contacts SATISFIES co.title LIKE 'System Arch%' END |
Você precisa adicionar as duas matrizes ao índice como mapeamentos filhos, conforme abaixo.
5) A sintaxe de pesquisa de diferenças
Esse é um caso de uso em que você está usando o FTS principalmente com pesquisa por palavra-chave e prefere uma sintaxe de predicado de pesquisa mais simples, como a do SQL.

N1QL e pesquisa sem limitações
Os aplicativos corporativos modernos exigem tanto a pesquisa exata quanto a pesquisa de texto. Para a pesquisa exata, a maioria dos RDBMS fornece um índice baseado em B-Tree para atender às necessidades. Os requisitos de pesquisa de texto aumentaram a popularidade dos mecanismos de pesquisa baseados em Lucene, como o ElasticSearch e o Solr.
- O Oracle NoSQL agora tem integração com o ElasticSearch: https://docs.oracle.com/en/database/other-databases/nosql-database/18.1/full-text-search/index.html#NSFTL-GUID-E409CC44-9A8F-4043-82C8-6B95CD939296
- Os aplicativos baseados no Oracle Enterprise RDBMS também oferecem o recurso ElasticSearch como uma opção usando o pacote de aplicativos CX. https://www.oracle.com/webfolder/technetwork/tutorials/tutorial/cloud/r13/wn/engagement/releases/20B/20B-engagement-wn.htm
Mas a adoção da funcionalidade do ElasticSearch em um modelo de dados RDBMS altamente normalizado traz uma série de desafios.
- Os requisitos de recursos para configurar o ElasticSearch, bem como os requisitos de armazenamento para ingerir os dados do RDBMS para o banco de dados do ElasticSearch.
- A necessidade de desnormalizar amplamente o modelo de dados, pois a pesquisa baseada em Lucene não oferece suporte a JOIN de banco de dados.
- O esforço de desenvolvimento para implementar a busca usando as APIs do ElasticSearch.
O esforço dos clientes que desejam usar o ElasticSearch é um dos principais motivos pelos quais vimos a adoção do SQL nesses bancos de dados NoSQL.
- Elasticsearch com SQL. https://www.elastic.co/what-is/elasticsearch-sql
- Opendistro para Elasticsearch com SQL. https://opendistro.github.io/for-elasticsearch/features/SQL%20Support.html
- O MongoDB adicionou a pesquisa ao MQL usando o Lucene em sua oferta do Atlas. https://www.mongodb.com/atlas/search
Mas as implementações SQL desses bancos de dados vêm com uma longa lista de limitações.
- Limitações do ElasticSQL: https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-limitations.html
- Não há suporte para junções de operações de conjunto, etc., etc.
- Nenhuma função de janela.
- A integração de pesquisa do MQL do MongoDB vem com uma longa lista de limitações.
- Disponível somente no serviço de pesquisa do Atlas, não no produto local.
- A pesquisa só pode ser a PRIMEIRA operação dentro do pipeline aggregate().
- Disponível somente no pipeline de agregação (aggregate()), o que significa que não pode ser usado com atualizações ou exclusões como predicado.
O Couchbase, por outro lado, tem o N1QL e o Full Text Search há muitos anos. A linguagem de consulta oferece suporte a todas as operações que você esperaria ver em um banco de dados maduro, com suporte a junções semelhantes a RDBMS, agregações e otimização de consultas baseadas em regras e em custos. O mais importante são as construções adicionais, como as operações NEST, UNNEST e ARRAY, que permitem que a linguagem N1QL trabalhe nativamente com documentos JSON.
O ponto importante do Couchbase N1QL com relação aos recursos de pesquisa é que o Couchbase Full Text Search está perfeitamente integrado à sua linguagem N1QL.
- Função de pesquisa N1QL do Couchbase 6.5. https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- Couchbase 6.6 Flex Index (o tópico deste artigo). https://docs.couchbase.com/server/6.6/n1ql/n1ql-language-reference/flex-indexes.html
Flex Index com o poder do N1QL
Aqui está um exemplo de consulta N1QL para um requisito de analisar i) quanto tempo a equipe de vendas gastou trabalhando com todos os clientes por setore também ii) retorna os três principais conjuntos de habilidades dos membros da equipe de vendas que trabalharam com esses clientes.
A consulta mostra que o Couchbase Flex Index pode ser usado com a combinação de qualquer recurso N1QL.

Considerações sobre o índice Flex
Até agora, a discussão ilustrou com exemplos como o recurso de índice Flex pode aproveitar um único índice FTS de vários campos para atender a todos os diferentes tipos de combinações de predicados e consultas com vários arrays, enquanto com o GSI você precisaria ter vários índices. Mas qual seria o impacto do tamanho do índice ao usar um índice FTS em vez de GSI? A tabela abaixo mostra quais são os tamanhos dos índices em minha configuração local do Couchbase.
Tamanho do índice
A tabela abaixo mostra um exemplo do tamanho do índice com base no conjunto de dados do modelo de atividade do crm.
Tamanho do documento: 1.5K. Contagem de documentos: 500K
| Opções de índice | Tamanho do índice GSI | Tamanho do índice FTS | Diferença de armazenamento |
| Índice de 13 campos | 205 MB | 252 MB | +25% |
| 13 campos + todos elementos de ambas as matrizes | N/A | 357 MB | - |
O objetivo da tabela acima não é fornecer um tamanho exato dos dois tipos de índices, mas sim as diferenças relativas de tamanho entre eles.
- O índice FTS é cerca de 25% maior em tamanho em comparação com o índice GSI. Esse número reflete os dados da amostra e a distribuição dos campos indexados.
- Há muita economia quando se trata de elementos de matriz.
- O índice FTS pode incluir todos os elementos de ambas as matrizes em um único índice.
Desempenho da consulta
Tanto a indexação do Couchbase quanto o Indexação de pesquisa de texto completo foram projetados para serem dimensionados com dimensionamento multidimensional e alta disponibilidade. Dito isso, esses serviços foram projetados para atender a objetivos diferentes. O serviço de indexação funciona melhor para requisitos de alta latência e alta taxa de transferência. Espera-se que as condições de pesquisa para essas consultas sejam bem definidas com pequenos conjuntos de resultados. O serviço FTS, por outro lado, foi projetado com suporte de analisador avançado para adicionar um elemento de imprecisão, com reconhecimento de idioma, além de fornecer uma pontuação de relevância para cada resultado.
- As consultas baseadas no Flex Index sempre incluirão um
buscarno processamento da consulta. Isso ocorre porque o serviço de consulta ainda estará executando afiltrofase. - A otimização do desempenho da consulta, como a agregação push-down para o índice, está disponível somente com o GSI, e não com o Flex Index.
- As consultas de índice cobertas estão disponíveis somente com o GSI.
- Com o Flex Index, a paginação da consulta é realizada no nível da consulta, pois a paginação não pode ser transferida para o FTS.
- Para consultas JOIN, somente os campos que podem ser usados em uma consulta de pesquisa do FTS serão passados para o Flex Index.
Resumo
Embora muitos bancos de dados NoSQL estejam tentando aprimorar suas linguagens de consulta, seja imitando o SQL indiretamente com o MQL, seja diretamente com o SQL no ElasticSQL, para oferecer a capacidade de realizar a pesquisa de correspondência exata, bem como a pesquisa de texto. Somente o Couchbase N1QL Flex Index oferece esses dois tipos de pesquisa de forma integrada com o N1QL SEARCH() e agora com predicados padrão disponíveis no N1QL Flex Index. Seu conhecimento de SQL é tudo o que você precisa para desenvolver um aplicativo que aproveite os dois tipos de pesquisa. Além disso, a pesquisa de texto também pode ser combinada com todos os recursos N1QL, JOIN/Aggregation/CTE e funções avançadas de janela analítica, e NEST/UNNEST/ARRAY para seus documentos JSON.
Referências
- O conjunto de dados de amostra do Activity Management Data Model usado neste artigo. https://couchbase-sample-datasets.s3.us-east-2.amazonaws.com/crm.tar
Explore os recursos do Couchbase Server 6.6