Flex Index Explained
What is a Flex Index? One of the key tasks of a database engine is how to efficiently manage the search and retrieval of the data therein. The efficiency and balance between resource consumption and performance are the most critical aspects of any database. Different types of database indexes, e.g. B-Tree, Inverted, Graph, and Spatial, etc., are designed to meet different search requirements. While indexes are essential for search performance, choosing the appropriate index type to use can also make a big difference to their effectiveness. Because the best type of indexes are often dictated by the characteristic of the data element being indexed.
In Couchbase, Global Secondary Index uses a B-Tree structure for fast exact and range search, and Full Text Search uses the inverted index structure to provide efficient term search. In addition to being highly scalable, each of these types of index also offers its own unique capabilities. B-Tree is the most commonly used index for high selectivity values (i.e. more distinct, such as order number), while inverted indexes are best used for indexing textual content, where the searchable term is likely to have low selectivity.
Applications that interface directly with users need search capability, and more often than not, these applications require both exact search, as well as text search. These search capabilities are often available through different search services, and as separate search APIs, which in turn can increase the complexity of the application development.
To address this need, Couchbase introduced the N1QL SEARCH() function in v6.5. It allows N1QL query to use both SQL predicate for exact and range search, and SEARCH() for text search, where results are not only predicated by the search term, but also by its relevance score. This adds a fuzziness factor to the search, as well as language aware capabilities.
The N1QL SEARCH() feature, for the first time, allows applications to access both query search services from a single API, using the Couchbase N1QL language. This integration offers many advantages. Chief among them is the simplification of the application development process by not having to deal with different APIs, but also delegating more of the search processing to the back end services.
In Couchbase 6.6, we took this N1QL/FTS integration one step further with Couchbase Flex Index.
What is Flex Index?
Flex index is a capability for Couchbase query service to leverage search capabilities, using only the standard N1QL predicate. Meaning you do not need to use the FTS syntax, nor the SEARCH() function, for your N1QL query to leverage FTS indexes.
The search datatype support includes text, datetime, numeric and boolean. But for text, only the keyword search is supported.
Keyword search – refers to the way a text field is processed before adding to an index. FTS index using the standard analyzer would parse the text into individual terms before indexing, whereas the keyword analyzer uses the entire text for the index.
So to understand how Flex Index works, let’s say that you have a query with this search condition: To find all the activities in a sales activity management system where the activities had involved the customer “Horizon Communications”, and happened in August 2020, and took place during a marketing event at the Moscone Center.
|
1 2 3 4 5 |
SELECT * FROM crm WHERE type='activity' AND event.location = 'Moscone Center' AND account.name = 'Horizon Communications' AND act_date BETWEEN '2020-08-01' AND '2020-08-31' |
Assume also that you have this GSI index :
|
1 2 3 |
CREATE INDEX adv_account_name_event_site_actdate ON `crm`(`account`.`name`,`event`.`location`,`act_date`) WHERE type='activity' |
This query, as it is written, will leverage the above GSI index because:
- All query predicates are covered by the index.
- The query also has the predicate
type=’activity’ that matches the filter of the index. - In fact, the index will be considered as long as the leading key
account.nameis one of the predicates, and that the query is restricted totype=’activity’.
Query Plan:

With Flex Index, you now have the option to request the query service to consider using the FTS index for the query.
|
1 2 3 4 5 |
SELECT * FROM crm USE INDEX (USING FTS) WHERE type='activity' AND event.site = 'Moscone Center' AND account.name = 'Horizon Communications' AND act_date BETWEEN '2020-08-01' AND '2020-08-31' |
The addition of the “USE INDEX (USING FTS)” hint suggests to the query service to consider using any FTS index, if one is available that can help with the query.
And if you have an FTS index defined as below:
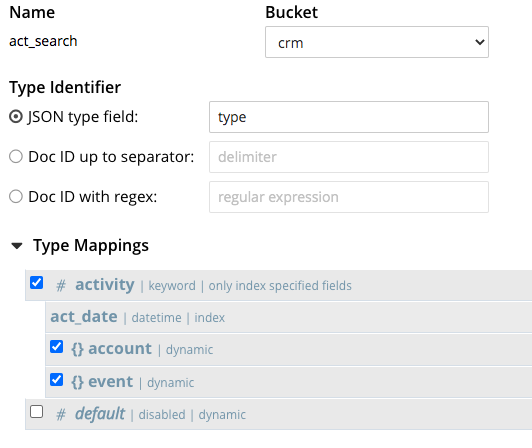
The act_search index has the following definition:
- It has a
typemapping that restricts the index content to include only the documents oftype= ‘activity’. - It includes the child field
act_date. - It includes the two child mappings for
accountandeventobjects. - Note that it uses the
keywordanalyzer.
In this case, the act_search is a perfect fit for the above N1QL Query, and with the USE INDEX (USING FTS) hint, the query will be able to use the act_search FTS index.
Query Plan:

So in a nutshell, Couchbase Flex Index provides the ability for N1QL Query with standard N1QL predicate syntax to transparently leverage either GSI or FTS index without any modification to the N1QL statements.
But the value of Flex Index comes not only with the simpler syntax for using FTS, but also the versatility of the FTS index, some of which will be described in the subsequent sections.
So when should you use Flex Index?
At the high level, Flex index can solve many challenges often found in applications that provide searches.
- Where the search conditions of the N1QL statements are not predetermined, meaning they can contain varied numbers of predicates, often based on user’s selections. And it is difficult to create indexes to cover all of the search conditions..
- Applications that provide search capabilities involving a large number of predicates, with logical operators, such as AND/OR combinations in the search conditions.
- Where the search conditions involve predicates on hierarchical document elements, such as search that involve array elements in an array, or in multiple arrays.
- Where the applications require the power of FTS, but also need SQL aggregation, and JOIN to include related information from other objects.
- Or you simply want to use the N1QL predicate syntax over the FTS syntax.
Note that Flex Index can also be used retrospectively on existing applications by adding the use_fts parameter to the query API calls.
1) The search patterns are not predetermined
When it comes to providing search capability to the end users, the challenge has always been what you would allow the user to search on. Standard guidelines dictate that the decision be determined by the users’ needs. But in complex systems, where the searchable fields are often not limited to a few key fields, but can encompass all the fields in an object, the decision on search is often driven by what the underlying database system can support.
Applications that are based on traditional B-Tree index for fast lookup often fall short when it comes to providing a flexible framework for this type of search requirement.
Consider this document:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
"activity" : { "id": "act1000", "title": "Announcing Couchbase Flex Index CB6.6", "reference": "24-i2y5J3928", "dept": "st55", "region": "00528", "notes": "Review the 100 N1QL Flex Index queries that ElasticSQL cannot do. The important point here is that Couchbase has integrated Text Search capability into its N1QL. Whereas ElasticSearch, relatively new SQL, has added SQL to its search engine....", "owner": { "id": "usr24", "name": "John Higgins" }, "priority": "Medium", "act_type": "Appointment", "event": { "name": "N1QL Flex Index vs. ElasticSQL", "location": "Moscone Center", "theme": "CouchbaseRed", "vendor": "Kempinski" }, "account": { "id": "acc134", "name": "Horizon Communications" }, "act_date": "2020-08-06", "appointment": { "duration": 90, "start_date": "2020-08-06 11:00:00", "contacts": [ { "id": "contact2493", "title": "SalesRep", "name": "Miranda Sullivan", "email": "msullivan@horizoncell.com", "phone": "778-096-1351" } ], "participants": [ { "role": "Support Analyst", "userid": "usr57", "name": "Raven Peterson" }, { "role": "Product Specialist", "userid": "usr24", "name": "John Higgins" } ], "type": "activity" } |
The 13 highlighted fields are all the possible fields that the user may want to search. So what would be the index strategy if you want to provide users with search capability?
| Index Strategy | Pros | Cons |
| Create 13 individual indexes | 1-Efficient for single field search. | 1-If more than one field is in the search then multiple indexes will be used, resulting in intersection-scans, which will affect performance
2-Increasingly inefficient as more search fields are included |
| Create composite index for frequently used search combinations | 1-Fast response time | 1-Inflexible as only specific search combinations are supported.
2-App UI has to ensure that the index leading key is present. |
| Create composite index for all search combinations | 1-Fastest response time | 1-The total number of indexes (13!) would be impractical |
| Leverage Search Engine – ElasticSearch or Couchbase FTS | 1-Fast response time
2-Only a single index is required |
1-Need to rewrite the application to leverage the search engine
2-More complex application code 3-Maintenance cost |
From the above list of options, it is clear that the most flexible search capability will require using a search engine, something similar to ElasticSearch or Couchbase FTS. But unless you have developed your application specifically with these search engines in mind, the effort to convert the search syntax and change of APIs will not be trivial.
And this is where the value of Couchbase Flex Index comes into the picture. This new feature allows developers to write N1QL Query statements using standard N1QL predicates, and the Query service will transparently leverage the FTS index.
2) Query with any predicate combinations
One of the key differences between GSI B-Tree and FTS Text index is how the key fields are built. The GSI B-Tree index concatenates all of the key fields of the index together to make up the node key, which is the main reason why a leading key must be present in the query before the index can be considered. The FTS index, on the other hand, creates a separate inverted index for each field. This design allows an FTS index to be considered for any query that has at least one of the indexed fields.
Consider the following query which has 13 different predicates, as well as the type=’activity predicate.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM crm a WHERE a.type='activity' /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center South' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempskinki' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Communications' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'John Higgins' |
To get the best performance, you need to have an index for the query, and the best index to have is a covering index as given by ADVISE:
|
1 2 3 4 5 |
CREATE INDEX adv_idx13 ON crm` (`account`.`name`,`event`.`vendor`,`account`.`id`,`event`.`location`, `event`.`theme`,`priority`,`owner`.`name`,`dept`,`event`.`name`, `owner`.`id`,`region`,`act_date`,`title`) WHERE `type` = 'activity' |
Query Plan:

However what would happen if:
- The query does not have the leading key
account.name? - The query has a varying combination of the 13 predicates?
GSI is the best index to have, providing you know the exact query predicates. However for applications that need to provide support for ad hoc queries, where the predicate set can not be predetermined, then it is best to consider using FTS.
So let’s now consider the following FTS index.
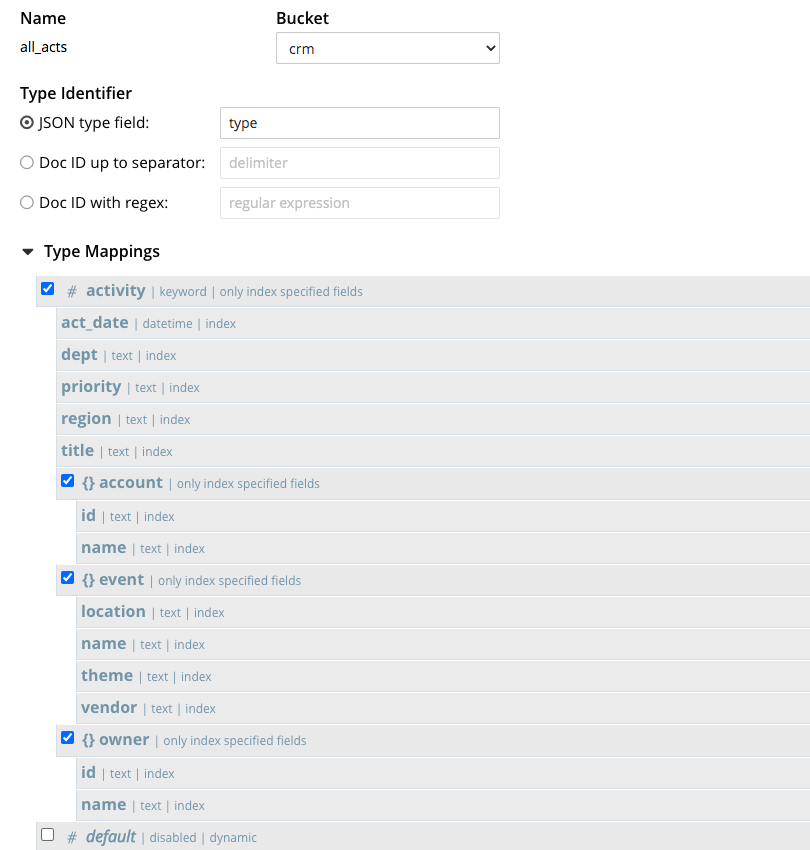
Notes:
- The index contains a
typemapping to specify that only documents with thetype= ‘activity’ will be included in the index. Refer to this FTS type mappings documentation for more information. - The index uses the keyword analyzer, meaning the data value will be added to the index in its entirety without getting parsed into individual terms.
- Each field is indexed individually in much the same way as the GSI index. All other options are unchecked, as they are not relevant to keyword search. Refer to this FTS child mapping documentation for more information.

With this FTS index in place, the same query as above, but with the USE INDEX (all_acts USING FTS) hint, will instruct the query service to consider using FTS index instead. Note that the index name all_acts is optional.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM crm a WHERE a.type='activity' USE INDEX (USING FTS) /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempinski' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Cellular' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'John Higgins' |
Query Plan:

Query Execution:

Key point to note: The query can have any varying number of predicates, and in any field combinations, and the query should still consider the FTS index.
3) Flex Index Query with combinations of logical operators – AND/OR
The benefit of the FTS index with regard to predicate combinations also extends further with the way each of the index fields is created. Because each indexed field has its own inverted structure, and because the Bleve routine creates a bitmap for each search condition, predicate combinations such as AND/OR/NOT are processed much more efficiently compared to the intersect-scan with B-Tree index.
The example below shows that even though there are several logical operators OR in the query, the all_acts FTS index is still be considered.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM crm a USE INDEX (USING FTS) WHERE a.type='activity' AND ( a.dept = 'iA88' OR a.region > '59416' ) AND a.priority = 'High' AND ( a.act_date BETWEEN '2018-01-01' AND '2018-08-31' OR a.event.location = 'Moscone Center' ) AND ( a.account.id = 'acc100' OR a.owner.name = 'Amanda Morrison') LIMIT 10 |
Query Plan:

Query Execution:
![]()
4) Query involves multiple array predicates
The versatility of the FTS index does not just stop with its ability to use the index with only a subset of the indexed fields in the search condition, or its ability to efficiently combine the search results with logical operators. But also the way FTS index handles array elements which allows the N1QL query to have any number of the array predicates.
Now let’s extend the query further with array predicates:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
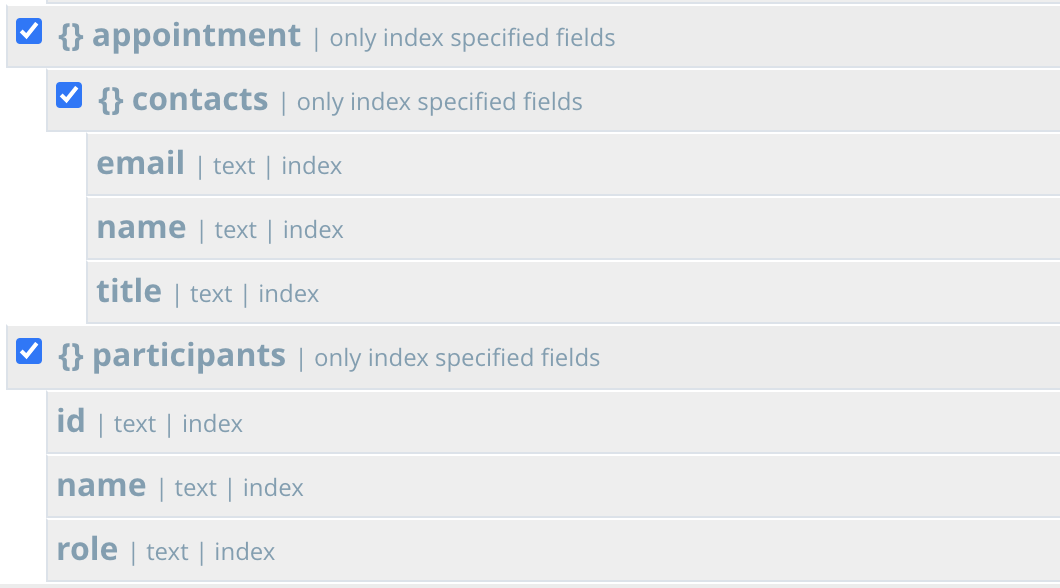
SELECT * FROM crm a WHERE a.type='activity' USE INDEX (USING FTS) /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center South' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempskinki' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Cellular' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'Binh Le' /* 14 */ AND ANY pa IN a.participants SATISFIES pa.name LIKE 'Randy%' END /* 15 */ AND ANY co IN a.appointment.contacts SATISFIES co.title LIKE 'System Arch%' END |
You do need to add the two arrays to the the index as child mappings as below.
5) The difference search syntax
This is a use case, where you are using FTS primarily with keyword search, and prefer a simpler SQL like search predicate syntax.

N1QL and Search without limitations
The modern enterprise applications require both exact search and text search. For exact search most RDBMS provide B-Tree based index to meet the needs. The requirements for text search have increased the popularity of the Lucene based search engines, such as ElasticSearch and Solr.
- Oracle NoSQL now has integration with ElasticSearch: https://docs.oracle.com/en/database/other-databases/nosql-database/18.1/full-text-search/index.html#NSFTL-GUID-E409CC44-9A8F-4043-82C8-6B95CD939296
- Oracle Enterprise RDBMS based applications also provide ElasticSearch capability as an option using the CX application suite. https://www.oracle.com/webfolder/technetwork/tutorials/tutorial/cloud/r13/wn/engagement/releases/20B/20B-engagement-wn.htm
But adopting ElasticSearch functionality in a highly normalized RDBMS data model brings a number of challenges.
- The resource requirements to set up ElasticSearch, as well as the storage requirements to ingest the RDBMS data for the ElasticSearch database.
- The need to denormalize the data model extensively, as Lucene based search does not support database JOIN.
- The development effort to implement the search using ElasticSearch APIs.
The effort for customers who want to use ElasticSearch is one of the key reasons why we have seen the adoption of SQL in these NoSQL databases.
- Elasticsearch with SQL. https://www.elastic.co/what-is/elasticsearch-sql
- Opendistro for Elasticsearch with SQL. https://opendistro.github.io/for-elasticsearch/features/SQL%20Support.html
- MongoDB has added search to MQL using Lucene in its Atlas offering. https://www.mongodb.com/atlas/search
But the SQL Implementations of these databases come with a long list of limitations.
- ElasticSQL limitations: https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-limitations.html
- No support for set operations joins, etc, etc.
- No window functions.
- MongoDB’s MQL’s search integration comes with a long list of limitations.
- Available only on the Atlas search service, not on the on-premise product.
- Search can only be the FIRST operation within the aggregate() pipeline.
- Available only within the aggregation pipeline (aggregate()), which means it can’t be used with updates or deletes as predicate.
Couchbase, on the other hand, has had N1QL and Full Text Search for many years. The query language supports all the operations that you would expect to see in a mature database, supporting RDBMS-like joins, aggregations, both rule-based and cost-based query optimization. Most important are the additional constructs such as NEST, UNNEST, and ARRAY operations to allow the N1QL language to work natively with JSON documents.
The important point about Couchbase N1QL with regard to search capabilities is that Couchbase Full Text Search is seamlessly integrated into its N1QL language.
- Couchbase 6.5 N1QL Search function. https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- Couchbase 6.6 Flex Index (the topic of this article). https://docs.couchbase.com/server/6.6/n1ql/n1ql-language-reference/flex-indexes.html
Flex Index with the power of N1QL
Here is an example N1QL query for a requirement to analyze i) how much time the sales team has spent working with all the customer by industry, and also ii) returns the top three skillsets from the sales team members who have worked with these customers.
The query shows that Couchbase Flex Index can be used with the combination of any N1QL features.

Flex Index Considerations
The discussion so far has illustrated with examples how the Flex index feature can leverage a single multiple-field FTS index to meet all different types of predicate combinations and queries with multiple arrays, where with GSI you would need to have several indexes. But what would be the index size impact of using an FTS index instead of GSI? The table below shows what the index sizes are in my local Couchbase setup.
Index Size
The table below an example of index size based on the crm activity model dataset.
Document size: 1.5K. Document count: 500K
| Index options | GSI Index Size | FTS Index Size | Storage Difference |
| Index on 13 fields | 205 MB | 252 MB | +25% |
| 13 fields + all elements from both arrays | N/A | 357 MB | – |
The purpose of the above table is not meant to provide an accurate size of the two types of indexes, but rather the relative size differences between them.
- The FTS index is around 25% greater in size compared to the GSI index. This number reflects the sample data, and the distribution of the indexed fields.
- There are a lot of savings when array elements are involved.
- The FTS index can include all elements of both arrays in a single index.
Query Performance
Both Couchbase Indexing and the Full-Text Search indexing services have been designed to scale with Multi Dimensional Scaling, and High Availability. That said, these services are designed to meet different goals. Indexing service works best for high latency and high throughput requirements. The search conditions for these queries are expected to be well defined with small result sets. FTS service, on the other hand, was designed with advanced analyzer support to add an element of fuzziness, language aware, as well as providing a relevancy score for each result.
- Queries which are based in Flex Index will always include a
fetchphase in the query processing. This is because the query service will still be performing thefilterphase. - Query performance optimization, such as aggregation push-down to index is available only with GSI, and not with Flex Index.
- Covered index queries are available with GSI only.
- With Flex Index, query pagination is performed at the query level, as pagination cannot be pushed down to FTS.
- For JOIN queries, only the fields that can be used in an FTS search query will be passed to Flex Index.
Summary
While many NoSQL databases are trying to improve their query languages, either by mimicking SQL indirectly with MQL, or directly with SQL in ElasticSQL, to provide the ability to perform exact match search as well as text search. Only Couchbase N1QL Flex Index provides both of these types of search seamlessly with N1QL SEARCH(), and now with standard predicates available in N1QL Flex Index. Your SQL knowledge is all that you need to develop an application to leverage both types of search. Furthermore, the text search can also be combined with all the N1QL features, JOIN/Aggregation/CTE and advanced Analytical Window Functions, and NEST/UNNEST/ARRAY for your JSON documents.
References
- The Activity Management Data Model sample dataset used in this article. https://couchbase-sample-datasets.s3.us-east-2.amazonaws.com/crm.tar
Explore Couchbase Server 6.6 resources