In 파트 1 에서 트위터를 스크랩하고, 트윗을 JSON 문서로 변환하고, 해당 트윗의 임베딩 표현을 얻고, 모든 것을 Couchbase에 저장하는 방법과 벡터 검색을 실행하는 방법을 살펴봤습니다. 이것이 트위터 스레드를 요약할 수 있는 검색 증강 세대 아키텍처의 첫 번째 단계입니다. 다음 단계는 대규모 언어 모델을 사용하는 것입니다. 이 모델에 스레드를 요약하라는 메시지를 표시할 수 있으며, 벡터 검색을 통해 메시지의 컨텍스트를 강화할 수 있습니다.
랭체인과 스트림릿
그렇다면 이 모든 것을 어떻게 LLM과 함께 작동하게 할 수 있을까요? 바로 이 부분에서 랭체인 프로젝트가 도움이 될 수 있습니다. 이 프로젝트의 목표는 개발자가 LLM 기반 애플리케이션을 구축할 수 있도록 하는 것입니다. 이미 다음에서 몇 가지 샘플을 사용할 수 있습니다. GitHub 를 통해 LangChain 모듈을 소개합니다. 이 RAG 데모처럼 사용자가 PDF를 업로드하고 벡터화하여 Couchbase에 저장하고 챗봇에서 사용. 이것은 자바스크립트에 있지만, 또한 Python 버전.
알고 보니 트윗 목록 대신 PDF를 사용한다는 점을 제외하면 제가 원하는 것과 정확히 일치합니다. 그래서 포크해서 여기에서 플레이하기 시작했습니다.. 여기서 Nithish는 몇 가지 흥미로운 라이브러리인 LangChain과 Streamlit을 사용하고 있습니다. 또 하나의 멋진 사실입니다! Streamlit은 PaaS와 로우 코드의 만남, 데이터 과학의 만남 서비스입니다. 이를 통해 최소한의 코딩으로 매우 쉽게 데이터 기반 앱을 배포할 수 있습니다.
구성
코드를 더 작은 덩어리로 나눠 보겠습니다. 구성부터 시작하겠습니다. 다음 메서드는 올바른 환경 변수가 설정되었는지 확인하고, 설정되지 않은 경우 애플리케이션 배포를 중지합니다.
그리고 체크_환경_변수 메서드를 여러 번 호출하여 필요한 구성이 설정되었는지 확인하고 그렇지 않은 경우 앱을 중지합니다.
|
1 2 3 4 5 |
def 체크_환경_변수(variable_name): """환경 변수가 설정되어 있는지 확인""" 만약 variable_name not in os.환경: st.오류(f"{변수_이름} 환경 변수가 설정되어 있지 않습니다. secrets.toml 파일에 추가하세요.") st.중지() |
|
1 2 3 4 5 6 7 8 |
체크_환경_변수("OPENAI_API_KEY") # 이전에 생성한 OpenApi API 키와 사용자 체크_환경_변수("DB_CONN_STR") # 카우치베이스에 연결할 연결 문자열(예: couchbase://localhost 또는 couchbases://cb.abab-abab.cloud.couchbase.com)입니다. 체크_환경_변수("DB_USERNAME") # 사용자 이름 체크_환경_변수("DB_PASSWORD") # 및 카우치베이스에 연결하기 위한 비밀번호 체크_환경_변수("DB_BUCKET") # 스코프와 컬렉션이 담긴 버킷의 이름입니다. 체크_환경_변수("DB_SCOPE") # 범위 체크_환경_변수("db_collection") #와 컬렉션 이름으로, 컬렉션은 RDBMS의 테이블로 생각할 수 있습니다. 체크_환경_변수("INDEX_NAME") # 검색 벡터 인덱스의 이름입니다. |
즉, 거기에 있는 모든 것이 필요하다는 뜻입니다. 다음에 대한 연결 OpenAI 그리고 카우치베이스. Couchbase에 대해 간단히 설명하겠습니다. 통합 캐시가 있는 JSON, 다중 모델 분산 데이터베이스입니다. K/V, SQL, 전체 텍스트 검색, 시계열, 분석으로 사용할 수 있으며, 7.6에서는 그래프 쿼리를 수행하는 재귀적 CTE 또는 현재 가장 관심 있는 벡터 검색과 같은 멋진 새 기능이 추가되었습니다. 가장 빠르게 사용해 보려면 cloud.couchbase.com30일 평가판이 있으며 신용 카드가 필요하지 않습니다.
여기에서 단계를 따라 새 클러스터를 설정할 수 있습니다. 버킷, 범위, 컬렉션 및 인덱스, 사용자를 설정하고 외부에서 클러스터를 사용할 수 있는지 확인하면 다음 단계로 넘어갈 수 있습니다. 앱에서 Couchbase에 연결하기. 이 두 가지 함수를 사용하여 수행할 수 있습니다. 다음과 같이 주석이 달린 것을 볼 수 있습니다. @st.cache_resource. 스트림릿의 관점에서 오브젝트를 캐시하는 데 사용됩니다. 이를 통해 다른 인스턴스나 재실행에 사용할 수 있습니다. 다음은 문서 발췌문입니다.
데코레이터를 사용하여 전역 리소스(예: 데이터베이스 연결, ML 모델)를 반환하는 함수를 캐시할 수 있습니다.
캐시된 객체는 모든 사용자, 세션 및 재실행에 걸쳐 공유됩니다. 여러 스레드에서 동시에 액세스할 수 있으므로 스레드 안전해야 합니다. 스레드 안전성이 문제가 되는 경우, 대신 st.session_state를 사용하여 세션별로 리소스를 저장하는 것을 고려해 보세요.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
에서 랭체인_커뮤니티.벡터 스토어 가져오기 카우치베이스 벡터 스토어 에서 랭체인_오픈아이 가져오기 OpenAIE임베딩 @st.캐시_자원(show_spinner="벡터 스토어에 연결하기") def get_vector_store( _cluster, db_버킷, db_scope, db_collection, _임베딩, index_name, ): """카우치베이스 벡터 스토어 반환""" 벡터_스토어 = 카우치베이스 벡터 스토어( 클러스터=_cluster, 버킷_이름=db_버킷, 범위_이름=db_scope, 컬렉션_이름=db_collection, 임베딩=_임베딩, index_name=index_name, 텍스트_키 ) 반환 벡터_store @st.캐시_자원(show_spinner="카우치베이스에 연결하기") def CONNECT_TO_COUCHBASE(연결 문자열, db_username, db_password): """카우치베이스에 연결""" 에서 카우치베이스.클러스터 가져오기 클러스터 에서 카우치베이스.auth 가져오기 비밀번호 인증기 에서 카우치베이스.옵션 가져오기 클러스터 옵션 에서 날짜 시간 가져오기 timedelta auth = 비밀번호 인증기(db_username, db_password) 옵션 = 클러스터 옵션(auth) 연결 문자열 = 연결 문자열 클러스터 = 클러스터(연결 문자열, 옵션) # 클러스터를 사용할 준비가 될 때까지 기다립니다. 클러스터.wait_until_ready(timedelta(초=5)) 반환 클러스터 |
따라서 이를 통해 Couchbase 클러스터에 연결하고 LangChain Couchbase 벡터 스토어 래퍼에 연결할 수 있습니다.
connect_to_couchbase(connection_string, db_username, db_password) 는 Couchbase 클러스터 연결을 생성합니다. get_vector_store(_cluster, db_bucket, db_scope, db_collection, _embedding, index_name,) 를 생성하면 카우찹세벡터스토어 래퍼입니다. 여기에는 클러스터에 대한 연결, 데이터를 저장할 버킷/범위/수집 정보, 벡터를 쿼리할 수 있도록 하는 인덱스 이름, 임베딩 속성이 들어 있습니다.
여기서는 OpenAIEmbeddings 함수를 가리킵니다. 이 함수는 자동으로 OPENAI_API_KEY 키를 생성하고 LangChain이 해당 키로 OpenAI의 API를 사용하도록 허용합니다. 모든 API 호출은 LangChain에 의해 투명하게 공개됩니다. 이는 또한 임베딩 관리와 관련하여 모델 공급자를 전환하는 것이 상당히 투명해야 한다는 것을 의미합니다.
카우치베이스에 LangChain 문서 작성하기
이제 마법이 일어나는 곳, 트윗을 가져와서 JSON으로 파싱하고 임베딩을 생성하고 특정 Couchbase 컬렉션에 JSON 문서를 작성합니다. Steamlit 덕분에 파일 업로드 위젯을 설정하고 관련 함수를 실행할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
가져오기 임시 파일 가져오기 os 에서 랭체인.문서 저장소.문서 가져오기 문서 def 저장_트위터에_벡터_저장소(업로드된 파일, 벡터_스토어): 만약 업로드된 파일 는 not 없음: 데이터 = json.load(업로드된 파일) # 업로드된 파일을 JSON으로 구문 분석하여 객체 배열을 예상합니다. 문서 = [] ids = [] 에 대한 트윗 in 데이터: # 모든 JSON 트윗의 경우 텍스트 = 트윗['text'] 전체 텍스트 = 트윗['전체_텍스트'] id = 트윗['id'] # 텍스트 필드와 관련 메타데이터가 포함된 랭체인 문서를 생성합니다. 만약 전체 텍스트 는 not 없음: doc = 문서(페이지_콘텐츠=전체 텍스트, 메타데이터=트윗) else: doc = 문서(페이지_콘텐츠=텍스트, 메타데이터=트윗) 문서.추가(doc) ids.추가(id) # Couchbase 문서 ID에 대해 유사한 배열을 생성합니다(제공되지 않은 경우 uuid가 자동으로 생성됨). 벡터_스토어.추가_문서(문서 = 문서, ids = ids) # 모든 문서 및 임베딩 저장 st.정보(f"{len(docs)} 문서에 벡터 저장소에 로드된 트윗 및 답글") |
1부의 코드와 다소 비슷해 보이지만, 모든 임베딩 생성이 LangChain에 의해 투명하게 관리된다는 점이 다릅니다. 텍스트 필드는 벡터화되고 메타데이터는 Couchbase 문서에 추가됩니다. 다음과 같이 보일 것입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "text": "@켈시하이타워 양말! 저에게 양말을 제안하는 첫 번째 회사에 수백만 달러를 던지겠습니다!"\n\n중요한 참고 사항입니다: 저는 수백만 달러가 없습니다! \문제가 있는 것 같아요.", "임베딩": [ -0.0006439118069540552, -0.021693240183757154, 0.026031888593037636, -0.020210755239867904, -0.003226784468532888, ....... -0.01691936794757287 ], "메타데이터": { "created_at": "Thu Apr 04 16:15:02 +0000 2024", "id": "1775920020377502191", "전체_텍스트": null, "text": "@켈시하이타워 양말! 저에게 양말을 제안하는 첫 번째 회사에 수백만 달러를 던지겠습니다!"\n\n중요한 참고 사항입니다: 저는 수백만 달러가 없습니다! \문제가 있는 것 같아요.", "lang": "en", "in_reply_to": "1775913633064894669", "quote_count": 1, "reply_count": 3, "favorite_count": 23, "view_count": "4658", "해시태그": [], "user": { "id": "4324751", "name": "Josh Long", "화면_이름": "스타벅스맨", "url ": "https://t.co/PrSomoWx53" } } |
이제부터는 트윗 업로드를 관리하고, 트윗을 벡터화하여 Couchbase에 저장하는 기능이 있습니다. 이제 Streamlit을 사용하여 실제 앱을 구축하고 채팅 흐름을 관리할 차례입니다. 이 기능을 몇 가지로 나누어 보겠습니다.
Streamlit 애플리케이션 작성
주요 선언과 앱의 보호부터 시작하세요. 다른 사람이 사용하지 못하도록 하고 OpenAI 크레딧을 사용해야 합니다. Streamlit 덕분에 꽤 쉽게 할 수 있습니다. 여기서는 로그인_비밀번호 환경 변수를 설정합니다. 또한 글로벌 페이지 구성도 설정했습니다. 설정_페이지_구성 메서드를 입력합니다. 그러면 비밀번호를 입력할 수 있는 간단한 양식과 간단한 페이지가 표시됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
만약 이름 == "__main__": # 인증 만약 "auth" not in st.세션_상태: st.세션_상태.auth = False st.설정_페이지_구성( 페이지 제목="랭체인, 카우치베이스 및 OpenAI를 사용한 트윗 내보내기로 채팅하기", 페이지_아이콘="🤖", 레이아웃="가운데", 초기_사이드바_상태="auto", 메뉴 항목=없음, ) AUTH = os.getenv("로그인_비밀번호") 체크_환경_변수("로그인_비밀번호") # 인증 user_pwd = st.text_input("비밀번호 입력", 유형="비밀번호") pwd_submit = st.버튼("제출") 만약 pwd_submit 그리고 user_pwd == AUTH: st.세션_상태.auth = True elif pwd_submit 그리고 user_pwd != AUTH: st.오류("비밀번호가 잘못되었습니다") |
조금 더 나아가서 환경 변수 검사, OpenAI 및 Couchbase 구성, 간단한 제목을 추가하여 앱 흐름을 시작할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
만약 st.세션_상태.auth: # 환경 변수 로드 DB_CONN_STR = os.getenv("DB_CONN_STR") DB_USERNAME = os.getenv("DB_USERNAME") DB_PASSWORD = os.getenv("DB_PASSWORD") DB_BUCKET = os.getenv("DB_BUCKET") DB_SCOPE = os.getenv("DB_SCOPE") DB_COLLECTION = os.getenv("db_collection") INDEX_NAME = os.getenv("INDEX_NAME") # 모든 환경 변수가 설정되어 있는지 확인합니다. 체크_환경_변수("OPENAI_API_KEY") 체크_환경_변수("DB_CONN_STR") 체크_환경_변수("DB_USERNAME") 체크_환경_변수("DB_PASSWORD") 체크_환경_변수("DB_BUCKET") 체크_환경_변수("DB_SCOPE") 체크_환경_변수("db_collection") 체크_환경_변수("INDEX_NAME") # OpenAI 임베딩 사용 임베딩 = OpenAIE임베딩() # 카우치베이스 벡터 스토어에 연결하기 클러스터 = CONNECT_TO_COUCHBASE(DB_CONN_STR, DB_USERNAME, DB_PASSWORD) 벡터_스토어 = get_vector_store( 클러스터, DB_BUCKET, DB_SCOPE, DB_COLLECTION, 임베딩, INDEX_NAME, ) st.title("X와 채팅") |
Streamlit에는 멋진 코드스페이스 통합 기능이 있어 개발을 정말 쉽게 만들어주니 꼭 사용해 보시기 바랍니다. 또한 VSCode 플러그인을 설치하면 Couchbase를 탐색하고 쿼리를 실행할 수 있습니다.
코드스페이스에서 SQL++ 벡터 검색 쿼리 실행
코드스페이스에서 기본 스트림릿 애플리케이션을 열었습니다.
랭체인 체인 생성
그 다음에는 체인 설정이 이어집니다. 바로 이 부분에서 LangChain이 빛을 발합니다. 여기에서 리트리버. LangChain에서 벡터화된 모든 트윗에 대해 Couchbase를 쿼리하는 데 사용할 것입니다. 이제 RAG 프롬프트를 작성할 차례입니다. 템플릿은 {컨텍스트} 그리고 {질문} 매개변수를 추가합니다. 템플릿에서 채팅 프롬프트 개체를 만듭니다.
그 다음에는 LLM을 선택해야 하는데, 여기서는 GPT4를 선택했습니다. 그리고 마지막으로 체인 생성입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# RAG의 리트리버로 카우치베이스 벡터 스토어 사용 리트리버 = 벡터_스토어.as_retriever() # RAG에 대한 프롬프트 작성하기 템플릿 = """귀하는 유용한 봇입니다. 제공된 문맥에 따라 답변할 수 없는 경우 일반적인 답변으로 응답하세요. 아래 문맥에 따라 최대한 사실에 입각하여 질문에 답변하세요: {컨텍스트} 질문: {질문}""" 프롬프트 = 채팅 프롬프트 템플릿.from_template(템플릿) # RAG의 LLM으로 OpenAI GPT 4 사용 llm = ChatOpenAI(온도=0, 모델="GPT-4-1106-프리뷰", 스트리밍=True) # RAG 체인 체인 = ( {"context": 리트리버, "question": 실행 가능한 패스스루()} | 프롬프트 | llm | StrOutputParser() ) |
체인은 선택한 모델, 컨텍스트 및 쿼리 매개 변수, 프롬프트 개체 및 StrOuptutParser. 이 역할은 LLM 응답을 구문 분석하여 스트리밍 가능/청크 가능 문자열로 다시 전송하는 것입니다. 그리고 실행 가능한 패스스루 메서드를 사용하여 질문 매개변수가 프롬프트에 '있는 그대로' 전달되도록 하지만 다른 메서드를 사용하여 질문을 변경/위생 처리할 수 있습니다. 이것이 바로 RAG 아키텍처입니다. 더 나은 답변을 얻기 위해 LLM 프롬프트에 몇 가지 추가 컨텍스트를 제공합니다.
또한 이 기능을 사용하지 않고 하나의 체인을 만들어 결과를 비교할 수도 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
# RAG 없는 순수 OpenAI 출력 template_without_rag = """당신은 도움이 되는 봇입니다. 질문에 최대한 진실하게 답변하세요. 질문: 질문: {질문}""" 프롬프트_위드아웃_래그 = 채팅 프롬프트 템플릿.from_template(template_without_rag) llm_without_rag = ChatOpenAI(모델="GPT-4-1106-프리뷰") chain_without_rag = ( {"question": 실행 가능한 패스스루()} | 프롬프트_위드아웃_래그 | llm_without_rag | StrOutputParser() ) |
프롬프트 템플릿과 체인 매개변수에는 컨텍스트가 필요 없으며, 리트리버가 필요하지 않습니다.
이제 커플 체인이 생겼으니 스트림릿을 통해 사용할 수 있습니다. 이 코드는 첫 번째 질문과 사이드바를 추가하여 다음을 허용합니다. 파일 업로드:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 프론트엔드 카우치베이스_로고 = ( "https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png" ) st.마크다운( "[카우치베이스 로고](https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png)가 있는 답변은 RAG를 사용하여 생성되는 반면 🤖는 순수 LLM(ChatGPT)으로 생성됩니다." ) 와 함께 st.사이드바: st.헤더("X 업로드") 와 함께 st.양식("업로드 X"): 업로드된 파일 = st.파일 업로더( "X 내보내기를 선택합니다.", 도움말="1시간 동안 활동이 없으면 문서가 삭제됩니다(TTL).", 유형="json", ) 제출됨 = st.양식_제출_버튼("업로드") 만약 제출됨: # 벡터 스토어에 트윗을 저장합니다. 저장_트위터에_벡터_저장소(업로드된 파일, 벡터_스토어) st.하위 헤더("어떻게 작동하나요?") st.마크다운( """ 각 질문에 대해 두 가지 답변이 제공됩니다: * RAG([카우치베이스 로고](https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png)를 사용하는 것) * 순수 LLM을 사용하는 것 - OpenAI(🤖). """ ) st.마크다운( "RAG의 경우, [Langchain](https://langchain.com/), [Couchbase Vector Search](https://couchbase.com/) 및 [OpenAI](https://openai.com/)를 사용하고 있습니다. 벡터 검색을 사용해 질문과 관련된 트윗을 가져와서 LLM에 컨텍스트로 추가합니다. LLM은 벡터 스토어의 컨텍스트에 따라 답변하도록 지시받습니다." ) # 코드 보기 만약 st.체크박스("코드 보기"): st.쓰기( "여기에서 코드를 확인하세요: [깃허브](https://github.com/couchbase-examples/rag-demo/blob/main/chat_with_x.py)" ) |
그런 다음 지침과 입력 로직을 입력합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 메시지 기록을 확인하고 비어 있는 경우 첫 번째 메시지를 추가합니다. 만약 "메시지" not in st.세션_상태: st.세션_상태.메시지 = [] st.세션_상태.메시지.추가( { "role": "assistant", "content": "안녕하세요, 트윗과 채팅할 수 있는 챗봇입니다. 무엇을 도와드릴까요?", "avatar": "🤖", } ) # 앱 재실행 시 기록의 채팅 메시지 표시 에 대한 메시지 in st.세션_상태.메시지: 와 함께 st.채팅_메시지(메시지["role"], 아바타=메시지["avatar"]): st.마크다운(메시지["content"]) # 사용자 입력에 반응 만약 질문 := st.채팅_입력("트윗을 기반으로 질문하기"): # 채팅 메시지 컨테이너에 사용자 메시지 표시 st.채팅_메시지("user").마크다운(질문) # 채팅 기록에 사용자 메시지 추가하기 st.세션_상태.메시지.추가( {"role": "user", "content": 질문, "avatar": "👤"} ) # 응답 스트리밍을 위한 자리 표시자 추가 와 함께 st.채팅_메시지("assistant", 아바타=카우치베이스_로고): 메시지_플레이스홀더 = st.빈() # RAG의 응답을 스트리밍합니다. rag_response = "" 에 대한 청크 in 체인.스트림(질문): rag_response += 청크 메시지_플레이스홀더.마크다운(rag_response + "▌") 메시지_플레이스홀더.마크다운(rag_response) st.세션_상태.메시지.추가( { "role": "assistant", "content": rag_response, "avatar": 카우치베이스_로고, } ) # 순수 LLM의 응답을 스트리밍합니다. # 응답 스트리밍을 위한 자리 표시자 추가 와 함께 st.채팅_메시지("ai", 아바타="🤖"): 메시지_플레이스홀더_순수_llm = st.빈() pure_llm_response = "" 에 대한 청크 in chain_without_rag.스트림(질문): pure_llm_response += 청크 메시지_플레이스홀더_순수_llm.마크다운(pure_llm_response + "▌") 메시지_플레이스홀더_순수_llm.마크다운(pure_llm_response) st.세션_상태.메시지.추가( { "role": "assistant", "content": pure_llm_response, "avatar": "🤖", } ) |
이를 통해 사용자는 스트림라이트 앱을 실행하는 데 필요한 모든 것을 갖추게 됩니다:
-
- 트윗이 포함된 JSON 파일 업로드
- 각 트윗을 LangChain 문서로 변환하기
- 임베딩 표현과 함께 Couchbase에 저장합니다.
- 두 개의 다른 프롬프트를 관리합니다:
- 컨텍스트를 추가하기 위해 LangChain 리트리버가 있는 것
- 없는
앱을 실행하면 다음과 같은 화면이 표시됩니다:
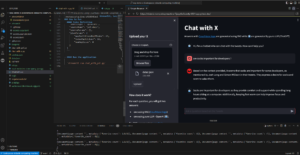
코드스페이스에서 열린 전체 스트림라이트 애플리케이션 예제
결론
"개발자에게 양말이 중요합니까?"라고 물으면 두 가지 흥미로운 대답이 나옵니다:
제공된 문맥에 따르면 Josh Long과 Simon Willison이 트윗에서 언급한 것처럼 일부 개발자에게는 양말이 중요한 것 같습니다. 이들은 양말에 대한 욕구를 표현하고 양말을 소중히 여기는 것 같습니다.
양말은 장시간 컴퓨터 앞에 앉아 있는 개발자에게 편안함과 지지력을 제공하기 때문에 매우 중요합니다. 또한 발을 따뜻하게 유지하면 집중력과 생산성 향상에도 도움이 됩니다.
이제 트위터 스레드에 대해 알고 그에 따라 답변할 수 있는 봇이 생겼습니다. 재미있는 점은 이 봇이 컨텍스트에서 텍스트 벡터만 사용한 것이 아니라 사용자 이름과 같이 저장된 모든 메타데이터도 사용했다는 것입니다. 왜냐하면 파트 1에서 인덱스를 만들 때 모든 LangChain 문서 메타데이터도 색인화했기 때문입니다.
하지만 이것이 정말 X 스레드를 요약한 것일까요? 그렇지 않습니다. 왜냐하면 벡터 검색은 전체 스레드가 아니라 가장 가까운 문서로 컨텍스트를 보강하기 때문입니다. 따라서 약간의 데이터 엔지니어링이 필요합니다. 다음 파트에서 이에 대해 이야기해 보겠습니다!
리소스
-
- 받기 RAG 데모 코드 예시 따라하기
- 가입하기 무료 평가판 카우치베이스 카펠라 DBaaS를 직접 체험해 보세요.