Full-Text Search – Indexing Tips
Understanding the Full-Text Search (FTS) indexing options are essential for building the right index for the job at hand. The right index here refers to a lean and rich enough inverted index that can serve those various types of customer search requests.
Some indexing best practices to keep in mind while creating an FTS index include the following.
-
Avoid default type mapping at production
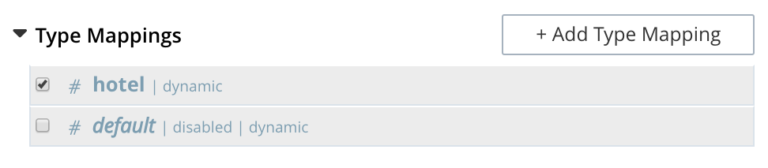
When a user creates an FTS index from the Couchbase web console, the pre-defined type mapping option chosen for an index is default. This is a special type of mapping applied to each document whose type either does not match a user-specified type mapping or has no recognized type attribute.
Therefore, if the default mapping is left enabled, all documents with all fields are included in the index. This will occur regardless of whether the user actively specifies type mappings or not.
The default dynamic mapping produces larger indexes and is potentially unsuitable for production deployments.
Disable the default type mapping, as shown below, to ensure that only user-specified type mappings are included in the index.
-
Specify the right type mappings
Identify the fields on which you need to make the documents searchable and define a custom type mapping mentioning the fields to be indexed. You may identify and index only a subset of your document types by specifying a single / set of type mappings you are interested in.
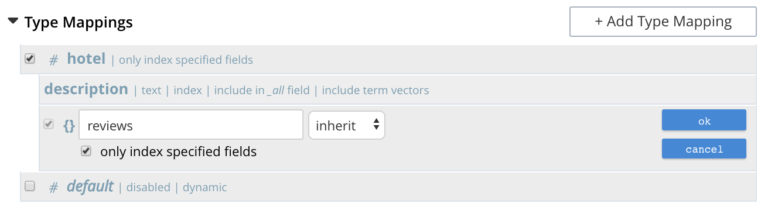
Further read: https://docs.couchbase.com/server/6.0/fts/fts-creating-indexes.html#specifying-type-identifiers
-
Choose the optimum field indexing options
While specifying a field for indexing, there are few important indexing options to reckon with.
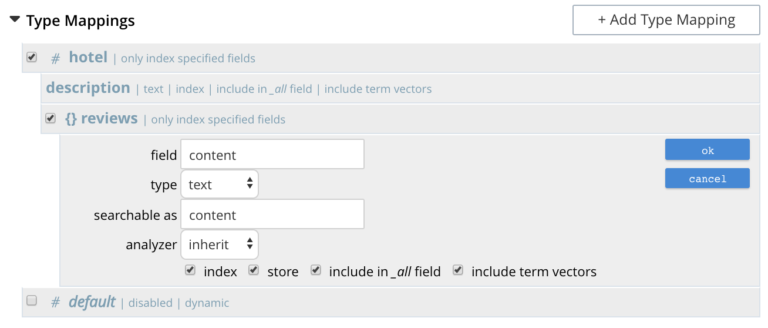
- index: When checked, the field is indexed; when unchecked, the field is not indexed. This may be used, therefore, to explicitly remove an already-defined field from the index.
- store: When checked, the field-content is included in the set of values returned from a search; when unchecked, the field-content is not so included. Note that inclusion of field-content specifically permits highlighting of results, so that matched expressions can be easily seen. However, it also results in larger indexes and longer processing-times. So please disable this option, if you are not interested in features like highlighting on the search results.
- include in _all field: When checked, the field is included in the definition of _all, which is the field specified by default in the Advanced panel. When unchecked, the field is not so included. Inclusion means that when _query strings are used to specify searches, the text in the current field is searchable without the field-name requiring a prefix (thus, a search on description:modern can be accomplished simply by specifying modern). Enabling this option results in larger indexes, so disable this option if you want to use field scoped search requests.
- include term vectors: When checked, term vectors are included. When unchecked, term vectors are not included. Term vectors are the locations of terms in a particular field. Certain kinds of functionality (such as highlighting, and phrase search) require term vectors. The inclusion of term vectors results in larger indexes and correspondingly slower index build-times. Hence please disable this option, if you are not interested in phrase searches or highlighting on search results.
-
Caution with numeric fields.
Often, documents will have all sorts of ID fields and users tend to index them as number types. But indexing as a number is only recommended when you have a real numeric use case, like range searches,
eg: “search for all the product docs that are about ‘iphone’ and whose price < 1000”.
Many use cases usually don’t have range searches on such ID fields but only do exact keyword equality searches on ID fields, Hence it is recommended to use text type and keyword* analyzer instead of number for these kinds of ID field situations.
As of now, FTS internally stores numbers in a lesser space-optimized format and the above approach can help you reduce the index size further. And smaller indexes are ought to result in better RAM occupancy.
We are adding more configurability to the index creation process, allowing further fine-tuning at the storage level.
Part 2…
keyword* analyzer – Creates a single token representing the entire input, and skips any text stemming or curation downstream.
> Caution with numeric fields
Is it possible to use the text type and keyword analyzer on numeric fields or you have to convert the field to string?
The field has to be converted to a string type as of today to work around this. But we are evaluating other native solutions as well.