Prelude: What is Database Indexing?
Asynchronous Indexing: Global Secondary Indexes in databases — Couchbase, for example — can be created, updated and deleted without impacting the reads and writes on the JSON documents in Data nodes. This means that index-specific inserts/updates/deletes happen asynchronously and workloads are isolated from the rest of the system.
Understand query SLAs and create indexes suitably: Indexes are directly related to the N1QL queries that are run. N1QL and GSI tango together. Indexes are meant to be steroids for N1QL queries, reducing latency costs and increasing throughput. Indexes also demand their own storage, but the risk of losing business due to slow(/shoddy) customer engagement experience is higher than their associated cost. Also, indexes in most cases live outside the confines of an application, which helps in managing their lifecycle suitably.
Let’s look at some database index best practices for delivering the best customer experiences.
1. Run Index Service on its own set of nodes
Though all services — data, query, index, search, etc. — in Couchbase can be run on all nodes, we recommend that individual workloads run on their own set of nodes. This affords workload isolation and independent scaling. Also, hardware can be apportioned suitably based on the nature of the workload. For example, indexes are generally memory-intensive and queries are CPU-intensive. You can have different hardware for these different services. Independent scalability for best computational capacity per service is achieved by the architectural nicety that Multidimensional-Scaling (MDS) offers us.
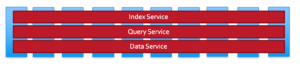
When all services are run on all available nodes
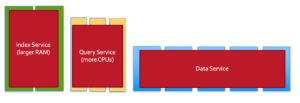
When individual Services are run on their own dedicated nodes
2. Understand MOI vs Standard GSI:
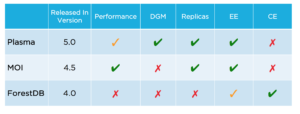
Couchbase 5.0 introduced Plasma as a new Storage Engine for GSI. Plasma is the underlined storage engine when ‘Standard Global Secondary’ is chosen at the time of the Setup. Both storage types have different characteristics. When the use-case demands that the entire index be memory resident(stricter SLAs, lower latencies + higher throughputs), then choose MOI. Standard GSI (Plasma) is extremely useful when the entire index cannot be memory resident, we call this as Data-Greater-Than-Memory (DGM) scenario; also, this is useful when memory costs are a factor in deciding the index type. While MOI might get into a pause mode when memory is completely used up (i.e, index updatations stop, though queries will be serviced), Plasma suitably spills over to disk and operates (and indexes in databases do get updated) with ease. In Couchbase 5.0, Plasma works well till 20% DGM scenarios (i.e, 20% of the index data is in memory); if the query accesses keys across both memory and disk, then there is suitable impact to query performance due to the obvious disk access while querying.
Due to the nature of being completely memory resident, MOI is generally much faster than Standard GSI (especially, the former ForestDB). As of now, it is not possible to have both types of indexing in the database reside in the same cluster.
The following schematic explains the different index storage engines available and their high level features
 3. Use Index Replicas : Replicas in GSI are active replicas, i.e. they serve the twin purpose of load balancing N1QL queries and also taking in the traffic if the other index replica fails.
3. Use Index Replicas : Replicas in GSI are active replicas, i.e. they serve the twin purpose of load balancing N1QL queries and also taking in the traffic if the other index replica fails.
|
1 |
create index idx on bucket(field1) with {“num_replica”: 2} |
(or)
|
1 |
create index idx on bucket(field1) with {“nodes”:[“1.2.3.1:8091”, “1.2.3.2:8091”, “1.2.3.3:8091”]} |
Both copies of the index are automatically updated asynchronously as the updates to documents happen on the data nodes. Always have at least one replica, which in turn means that there be two index nodes at the minimum for servicing N1QL queries. Due to the support of swap rebalance in 5.0, if an index node goes down, and a new node is added back, then the topology is maintained. This is extremely helpful for scale-up/down operations due to seasonalities in queries, when you want to move between larger nodes and smaller nodes.
If already using equivalent indexes, transition to replicas. Read more about this process here.
4. Indexes Variants
GSI has different variants based on different use cases. These different variants were purpose built for the nature of the queries and hence it is extremely important to understand the behaviour of the queries and properly leverage these index variants.
| Primary Index | Functional Index |
| Named Primary Index | Array Index |
| Composite Index | Covered Index |
| Partial Index | Adaptive Index |
Do check out this DZone Article and this documentation for more on the above.
For a database index example, let’s look at the Covered Index: this variant contains predicates and all attributes that were indexed in the definition, because of which additional hop to data nodes are avoided. Query latencies are significantly lowered.
For example, if we have the following:
|
1 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`); |
And use the query:
|
1 |
select iata from `travel-sample` where type="airline" and iata = "TQ" |
Then the Explain Plan will reveal that the query is being ‘covered’ by the index:
|
1 2 3 4 5 6 7 8 9 |
"~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`iata`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "idx_ts_type_iata", |
And if we try to select ‘all’(by using ‘select *’) attributes:
|
1 |
<span style="font-weight: 400">select * from `travel-sample` where type="airline" and iata = "TQ";</span> |
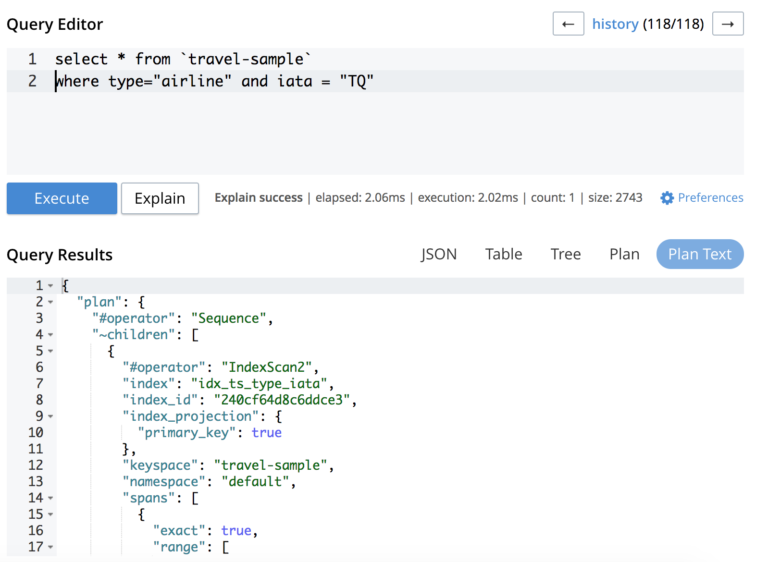
Then the EXPLAIN PLAN reveals that the query is not covered(missing ‘covers’ field) as the Query Service has to hop to Data Service to fetch all the attributes:
|
1 2 3 4 5 6 7 8 |
"~children": [ { "#operator": "IndexScan2", "index": "idx_ts_type_iata", "index_id": "240cf64d8c6ddce3", "index_projection": { "primary_key": true }, |
Similarly, Array Indexes were created mainly to help our customers query JSON data, wherein Arrays are very common. A detailed post on this coming soon!
5. Avoid Primary Keys in Production
Unexpected full primary scans are possible and any possibility of such occurrences should be removed by avoiding primary indexes altogether in Production. N1QL Index Selection is a rule based system for now that checks for a possible index that will satisfy the query, and if there is no such, then it resorts to using the Primary Index. Primary index has all the keys of the documents — hence, query will fetch all keys from the primary index and then hop to Data Service to fetch the documents and then apply filters. As you can see, this is a very expensive operation and should be avoided at all costs.
If there are no Primary Indexes created, and the query is not able to find a matching index to serve the query, then the Query Service errors with the following message, which should help you in creating the required Secondary index:
“No index available on keyspace travel-sample that matches your query. Use CREATE INDEX or CREATE PRIMARY INDEX to create an index, or check that your expected index is online.”
Also, as an inherent indexing best practice, partitioning of primary indexes is not supported by Couchbase. Unlike in many RDBMSes, primary keys are optional in Couchbase.
6. Use EXPLAIN Plans
To validate if the N1QL query is indeed using the indexes created, check the EXPLAIN PLAN results. In the Couchbase Admin Console, this can easily be obtained by pasting the query in the code editor and clicking on the ‘Explain’ button. Look out for the “#operator” and “index” attributes of the result to confirm the index usage. Documentation Link.
 7. Index by Predicate
7. Index by Predicate
The WHERE clause in a query is called as the Predicate and the fields/attributes selected in the SELECT clause is called as Projection. Indexes should always be created with the Predicate clause in mind. This is because Index Selection happens based on the leading key of the index present in the Predicate.
For example, if we have the following index on 4 attributes:
|
1 |
CREATE INDEX `idx_ts_type_iata_name_icao` ON `travel-sample`(`type`,`iata`, `name`,`icao`); |
And fire the following query that actually skps the icao attribute while querying, the query engine is smart enough to know to use the above index for best query performance.
|
1 |
select name from `travel-sample` where icao="MLA" and type="airline"; |
The index selected can be seen in the explain plan below. Note that the query becomes a Covering query, as ‘name’ despite not being in Predicate is in Projection, hence the hop to Data Service is avoided.
|
1 2 3 4 5 6 7 8 9 10 11 |
"~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`iata`))", "cover ((`travel-sample`.`name`))", "cover ((`travel-sample`.`icao`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "idx_ts_type_iata_name_icao", |
8. Use a Leading Key to Force Index Selection
An index is not automatically selected for a query if the predicate used in the query does not match the leading key of the index. If you happen to see that the EXPLAIN PLAN does not force any index to be selected then use ‘IS NOT MISSING’ or ‘IS NOT NULL’ clause to force the index to be selected.
For example, either of the following queries:
|
1 2 |
select count(1) from `travel-sample` where type IS NOT NULL; select count(1) from `travel-sample` where type IS NOT MISSING; |
will use the following index, as the leading key of the index is ‘type’:
|
1 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`); |
To choose only an already created INDEX, use the USE INDEX directive as part of the N1QL query. This is helpful in cases wherein you know that the index mentioned in USE INDEX has better selectivity than the one chosen by N1QL Rule Based Optimizer:
|
1 |
select count(1) from `travel-sample` USE INDEX (idx_ts_type_iata) where type="airline"; |
9. Use Partial Indexes
Sometimes, the predicate to be indexed on might not fit into one node due to size limitations. GSI in Couchbase are not automatically partitioned for now. This mandates that the administrator creates Partial Indexes; N1QL queries are smart enough to choose the appropriate index based on the kind of predicate used in the query when partial indexes are present.
For example, we create the following two indexes based on the name being in two different ranges:
|
1 2 |
CREATE INDEX `idx_ts_name_ak` ON `travel-sample`(`name`) WHERE name BETWEEN "A" AND "K"; CREATE INDEX `idx_ts_name_kz` ON `travel-sample`(`name`) WHERE name BETWEEN "K" AND "Z"; |
Now, following queries will automatically choose the suitable index as is evidenced in the respective EXPLAIN PLANS:
|
1 2 3 4 5 6 7 |
select * from `travel-sample` where name="Astraeus"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_ak", |
|
1 2 3 4 5 6 7 |
select * from `travel-sample` where name="Texas Wings"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_kz", |
Indexes are suitably chosen when using the LIKE clause in the predicate. For example, let’s say we want to get all names that sound like a French Name(starting with “L’”):
|
1 2 3 4 5 6 |
select * from `travel-sample` where name like "L'%"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_kz", |
10. Consistency Options
Due to its asynchronous nature, GSI in Couchbase are eventually consistent by default and as already mentioned, they are asynchronously updated. Though, using change feeds(DCP), we update indexes as quickly possible, it is very much possible that certain document mutations haven’t been updated in the indexes. If the query semantics demand stricter data consistency, then Couchbase offers tunable consistency models at the time of querying.
The three consistency options available in Couchbase are:
- scan_consistency=not_bounded
- scan_consistency=at_plus
- scan_consistency=request_plus
For more: Documentation Link
Though request_plus semantics enforce data integrity, there is an impact on performance as query latencies increase; query waits for the relevant index to catchup with the latest mutations before the data is returned. ‘not_bounded’ (the default consistency option) is the fastest of all 3 consistency options.
11. Monitor Index Catchup
Generally the index service catches up with document mutations very quickly so as to leave little to no user impact. But as an administrator, if you want to make sure that the document mutations (to be updated in the index) are as minimal as possible and do not keep increasing, then look at the ‘items remaining’ metric under the index name.
12. Use Defer builds
Defer builds offers a 2 stage process of creating indexes. It is recommended that Defer Builds be put to optimum use always, as the same change feed is used to create indexes on a node. If DEFER builds are not used, the change feed from the data nodes has to be accessed multiple times, leading to more data transfer across the network and a slightly increased load on the data nodes.
Example:
|
1 2 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`) WITH { "defer_build":true }; BUILD INDEX ON `travel-sample`(`idx_ts_type_iata`); |
For more on CREATE INDEX syntax, please refer to the Documentation.
13. Avoid large keys to index
Prior to 5.0, there was a limitation on the key size for indexes (maximum 4k). This limitation has been removed in 5.0. Note that indexes are meant for data access paths, hence the data model and query (with indexes) should be structured to get the necessary information in the shortest time. Though customers can have any number of fields in a composite index, the index key size also grows proportionally. Really large key sizes might impact performance. As a general rule of thumb, prefer to have 1kB as the combined size of all fields in a composite index; and if that is not possible, refactor the queries suitably.
14. USE KEYS, avoid indexes
It is not necessary that all N1QL queries require indexes. If your N1QL queries can work independently of indexes, by directly querying the documents using keys, then the directive USE KEYS is helpful.
For example:
|
1 |
SELECT * FROM `travel-sample` USE KEYS ["landmark_37588"]; |
The resulting explain plan will show a KeyScan being performed(without any mention of an IndexScan):
|
1 2 3 4 5 |
"~children": [ { "#operator": "KeyScan", "keys": "[\"landmark_37588\"]" } |
This is more of a thing to know than a best practice, as USE KEYS does not use indexes for returning results from the query service. Though highly unlikely that customers can have only queries that always use USE KEYS, this can be helpful in the edge cases which mandates such behaviour.
Long Post!! But, I hope this was helpful in understanding databases and indexes and how indexing in DBMS best practices can help you deliver superior customer experiences :)
PS: An Overview of GSI and What’s New in Couchbase Server 5.0 : https://www.youtube.com/watch?v=OrC2gkm2OFA