Introduction
There are three things important in database systems: performance, performance, performance. For NoSQL database systems, there are three important things: performance at scale, performance at scale, performance at scale.
Understanding the index options, creating the right index, with the right keys, right order, and right expression is critical to query performance and performance at scale on Couchbase. We’ve discussed data modeling for JSON and querying on JSON earlier. In this article, we’ll discuss indexing options for JSON in Couchbase.
Couchbase 5.0 has three types of index categories. Each Couchbase cluster can only have one category of index, either standard global secondary index or memory-optimized global secondary index.
| Standard Secondary: Release 4.0 and above |
|
| Memory-Optimized Index: 4.5 and above |
|
| Standard Secondary: Release 5.0 |
|
The standard secondary index (from 4.0 to 4.6.x) stores uses the ForestDB storage engine to store the B-Tree index and keeps the optimal working set of data in the buffer. That means, the total size of the index can be much bigger than the amount of memory available in each index node.
A memory-optimized index uses a novel lock-free skiplist to maintain the index and keeps 100% of the index data in memory. A memory-optimized index (MOI) has better latency for index scans and can also process the mutations of the data much faster.
The standard secondary index in 5.0 uses the plasma storage engine in our enterprise edition, which uses the lock-free skip list like MOI, but supports large indexes that don’t fit in memory.
All three types of indexes implement multi-version concurrency control (MVCC) to provide consistent index scan results and high throughput. During cluster installation, choose the type of index.
The goal is to give you an overview of various indices you create in each of these services so that your queries can execute efficiently. The goal of this article is not to describe or compare and contrast these two types of index services. It does not cover the Full-Text Search Index (FTS), released in Couchbase 5.0.
Let’s take the travel-sample dataset and try out these indices.
In the web console, go to Settings->Sample Buckets to install travel-sample.
Here are the various indices you can create.
- Primary Index
- Named primary index
- Secondary index
- Composite Secondary Index
- Functional index
- Array Index
- ALL array
- ALL DISTINCT array
- Partial Index
- Adaptive Index
- Duplicate Indices
- Covering Index
Background
Couchbase is a distributed database. It supports a flexible data model using JSON. Each document in a bucket will have a user-generated unique document key. This uniqueness is enforced during the insertion of the data.
Here’s an example document.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT meta().id, travel FROM `travel-sample` travel WHERE type = 'airline' limit 1; [ { "id": "airline_10", "travel": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" } } ] |
Type of Indexes
1. Primary Index
creates the primary index on ‘travel-sample’:
The primary index is simply the index on the document key on the whole bucket. The Couchbase data layer enforces the uniqueness constraint on the document key. The primary index, like every other index in Couchbase, is maintained asynchronously. You set the recency of the data by setting the consistency level for your query.
Here is the metadata for this index:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM system:indexes WHERE name = ‘#primary’; "indexes": { "datastore_id": "https://127.0.0.1:8091", "id": "f6e3c75d6f396e7d", "index_key": [], "is_primary": true, "keyspace_id": "travel-sample", "name": "#primary", "namespace_id": "default", "state": "online", "using": "gsi" } |
The metadata gives you additional information on the index: Where the index resides (datastore_id), its state (state), and the indexing method (using).
The primary index is used for full bucket scans (primary scans) when the query does not have any filters (predicates) or another index or access path can be used. In Couchbase, you store multiple keyspaces (documents of a different type, customer, orders, inventory, etc) in a single bucket. So, when you do the primary scan, the query will use the index to get the document-keys and fetch all the documents in the bucket and then apply the filter. This is VERY EXPENSIVE.
The document key design is somewhat like a primary key design with multiple parts.
Lastname:firstname:customerid
Example: smith:john:X1A1849
In Couchbase, it’s a best practice to prefix the key with the type of the document. Since this is a customer document, let’s prefix with CX. Now, the key becomes:
|
1 |
Example: CX:smith:john:X1A1849 |
So, in the same bucket, there will be other types of documents.
|
1 |
ORDERS type: OD:US:CA:294829 |
|
1 |
ITEMS type: IT:KD93823 |
These are simply best practices. There are no restrictions on the format or structure of the document key in Couchbase, except that they need to be unique within a bucket.
Now, if you have documents with various keys and have a primary index, you can use the following queries efficiently.
Example 1: Looking for a specific document key.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT * FROM sales WHERE META().id = “CX:smith:john:X1A1849”; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX:smith:john:X1A1849\"", "inclusion": 3, "low": "\"CX:smith:john:X1A1849\"" } ] } ], } |
If you do know the full document key, you can use the following statement and avoid the index access altogether.
SELECT * FROM sales USE KEYS [“CX:smith:john:X1A1849”]
You can get more than one document in a statement.
|
1 |
SELECT * FROM sales USE KEYS [“CX:smith:john:X1A1849”, “CX:smithjr:john:X2A1492”] |
Example 2: Look for a pattern. Get ALL the customer documents.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT * FROM sales WHERE META().id LIKE “CX:%”; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX;\"", "inclusion": 1, "low": "\"CX:\"" }" ] } ], } |
Example 3: Get all the customers with “smith” as their last name.
The following query uses the primary index efficiently, only fetching the customers with a particular range. Note: This scan is case sensitive. To do a case insensitive scan, you can create a secondary index with UPPER() or LOWER() of the document key.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT * FROM sales WHERE META().id LIKE "CX:smith%"; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX:smiti\"", "inclusion": 1, "low": "\"CX:smith\"" } ] } ], } |
Example 4: It’s common for some applications to use an email address as part of the document as they are unique values. In that case, you need to find out all of the customers with “@gmail.com”. If this is a typical requirement, then, store the REVERSE of the email address as the key and simply do the scan of the leading string pattern.
Email:johnsmith@gmail.com; key: reverse("johnsmith@gmail.com") => moc.liamg@htimsnhoj
Email: janesnow@yahoo.com key: reverse("janesnow@yahoo.com") => moc.oohay@wonsenaj
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT * FROM sales WHERE meta().id LIKE (reverse("@yahoo.com") || "%"); { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "range": [ { "high": "\"moc.oohayA\"", "inclusion": 1, "low": "\"moc.oohay@\"" } ] } ], } |
2. Named Primary Index
In Couchbase 5.0, you can create multiple replicas of any index with a simple parameter to CREATE INDEX. The following will create 3 copies of the index and there has to be a minimum of 3 index nodes in the cluster.
|
1 2 |
CREATE PRIMARY INDEX ON 'travel-sample' WITH {"num_replica":2}; CREATE PRIMARY INDEX `def_primary` ON `travel-sample` ; |
You can also name the primary index. The rest of the features of the primary index are the same, except the index is named. A good side effect of this is that you can have multiple primary indices in Couchbase versions before 5.0 using different names. Duplicate indices help with high availability as well as query load distribution throughout them. This is true for both primary indices and secondary indices.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT meta().id as documentkey, `travel-sample` airline FROM `travel-sample` WHERE type = 'airline' limit 1; { "airline": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" }, "documentkey": "airline_10" } |
3. Secondary Index
The secondary index is an index on any key-value or document-key. This index can be any key within the document. The key can be of any time: scalar, object, or array. The query has to use the same type of object for the query engine to exploit the index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE INDEX travel_name ON `travel-sample`(name); name is a simple scalar value. { "name": "Air France" } CREATE INDEX travel_geo on `travel-sample`(geo); geo is an object embedded within the document. Example: "geo": { "alt": 12, "lat": 50.962097, "lon": 1.954764 } Creating indexes on keys from nested objects is straightforward. CREATE INDEX travel_geo on `travel-sample`(geo.alt); CREATE INDEX travel_geo on `travel-sample`(geo.lat); |
The schedule field is an array of objects with flight details. This indexes on the complete array. Not exactly useful unless you’re looking for the whole array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE INDEX travel_schedule ON `travel-sample`(schedule); Example: "schedule": [ { "day": 0, "flight": "AF198", "utc": "10:13:00" }, { "day": 0, "flight": "AF547", "utc": "19:14:00" }, { "day": 0, "flight": "AF943", "utc": "01:31:00" }, { "day": 1, "flight": "AF356", "utc": "12:40:00" }, { "day": 1, "flight": "AF480", "utc": "08:58:00" }, { "day": 1, "flight": "AF250", "utc": "12:59:00" } ] |
4. Composite Secondary Index
It’s common to have queries with multiple filters (predicates). So, you want the indices with multiple keys so the indices can return only the qualified document keys. Additionally, if a query is referencing only the keys in the index, the query engine will simply answer the query from the index scan result without going to the data nodes. This is a commonly exploited performance optimization.
|
1 |
CREATE INDEX idx_stctln ON `travel-sample` (state, city, name.lastname) |
Each of the keys can be a simple scalar field, object, or an array. For the index filtering to be exploited, the filters have to use the respective object type in the query filter. The keys to the secondary indices can include document keys (meta().id) explicitly if you need to filter on it in the index.
Let’s look at the queries that exploit and cannot exploit the index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
1.SELECT * FROM `travel-sample` WHERE state = 'CA'; The predicate matches the leading key of the index. So, this query uses the index to fully evaluate the predicate (state = ‘CA’). 2.SELECT * FROM `travel-sample` WHERE state = 'CA' AND city = 'Windsor'; The predicates match the leading two keys. So this is good fit as well. 3.SELECT * FROM `travel-sample` WHERE state = 'CA' AND city = 'Windsor' AND name.lastname = 'smith'; The three predicates in this query matches the three index keys perfectly. So, this is a good match. 4.SELECT * FROM `travel-sample` WHERE city = 'Windsor' AND name.lastname = 'smith'; In this query, although predicates match two of the index keys, the leading key isn’t matched. So, the index cannot and is not used for this query plans. 5.SELECT * FROM `travel-sample` WHERE name.lastname = 'smith'; Similar to previous query, this query has the predicate on the third key of the index. So, this index cannot be used. 6.SELECT * FROM `travel-sample` WHERE state = 'CA' AND name.lastname = 'smith'; This query has predicate on first and the third key. While this index is and can be chosen, we cannot push down the predicate after skipping an index key (second key in this case). So, only the first predicate (state = "CA") will be pushed down to index scan. "#operator": "IndexScan2", "index": "idx_stctln", "index_id": "dadbb12da565ed28", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" } ] } 7.SELECT * FROM `travel-sample` WHERE state IS NOT MISSING AND city = 'Windsor' AND name.lastname = 'smith'; This is a modified version of query 4 above. To use this index, the query needs to have an additional predicate (state IS NOT MISSING) assuming that represents your application requirement. |
5. Functional (Expression) Index
It’s common to have names in the database with a mix of upper and lower cases. When you need to search, “John,” you want it to search for any combination of “John,” “john,” etc. Here’s how you do it.
CREATE INDEX travel_cxname ON `travel-sample`(LOWER(name));
Provide the search string in lowercase and the index will efficiently search for already lowercased values in the index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
EXPLAIN SELECT * FROM `travel-sample` WHERE LOWER(name) = "john"; { "#operator": "IndexScan", "index": "travel_cxname", "index_id": "2f39d3b7aac6bbfe", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ "\"john\"" ], "Inclusion": 3, "Low": [ "\"john\"" ] } } ] } |
You can use complex expressions in this functional index.
CREATE INDEX travel_cx1 ON `travel-sample`(LOWER(name), length*width, round(salary));
You’ll also see that array indexes can be created on an expression that returns an array in the next section.
6. Array Index
JSON is hierarchical. At the top level, it can have scalar fields, objects, or arrays. Each object can nest other objects and arrays. Each array can have other objects and arrays. And so on. The nesting continues.
When you have this rich structure, here’s how you index a particular array or a field within the sub-object.
Consider the array, schedule:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
schedule: [ { "day" : 0, "special_flights" : [ { "flight" : "AI111", "utc" : ”1:11:11" }, { "flight" : "AI222", "utc" : ”2:22:22" } ] }, { "day": 1, "flight": "AF552", "utc": "14:41:00” } ] CREATE INDEX travel_sched ON `travel-sample` (ALL DISTINCT ARRAY v.day FOR v IN schedule END) |
This index key is an expression on the array to clearly reference only the elements needed to be indexed. schedule the array we’re dereferencing into. v is the variable we’ve implicitly declared to reference each element/object within the array: schedule v.day refers to the element within each object of the array schedule.
The query below will exploit the array index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
EXPLAIN SELECT * FROM `travel-sample` WHERE ANY v IN SCHEDULE SATISFIES v.day = 2 END; { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan", "index": "travel_sched", "index_id": "db7018bff5f10f17", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ "2" ], "Inclusion": 3, "Low": [ "2" ] } } ], "using": "gsi" } |
Because the key is a generalized expression, you get the flexibility to apply additional logic and processing on the data before indexing. For example, you can create functional indexing on elements of each array. Because you’re referencing individual fields of the object or element within the array, the index creation, size, and search are efficient. The index above stores only the distinct values within an array. To store all elements of an array in an index, use the DISTINCT modifier to the expression.
CREATE INDEX travel_sched ON `travel-sample` (ALL DISTINCT ARRAY v.day FOR v IN schedule END)
Array Index can be created on static values (like above) or an expression that returns an array. TOKENS() are one such expression, returning an array of tokens from an object. You can create an index on this array and search using the index.
Couchbase 5.0 makes it simpler to create and match the array indexes. Providing ALL ( or ALL DISTINCT) prefix to the key will make it an array key.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx_cx6 ON `travel-sample`(ALL TOKENS(public_likes)) WHERE type = ‘hotel’; SELECT t.name, t.country, t.public_likes FROM `travel-sample` t WHERE t.type = 'hotel’ AND ANY p IN TOKENS(public_likes) SATISFIES p = 'Vallie' END; |
Array indexes can be created on elements within arrays of arrays as well. There is no limit to the nested level of the array expression. The query expression does have to match the index expression.
7. Partial Index
So far, the indices we’ve created will create indices on the whole bucket. Because the Couchbase data model is JSON and JSON schema are flexible, an index may not contain entries to documents with absent index keys. That’s expected. Unlike relational systems, where each type of row is in a distinct table, Couchbase buckets can have documents of various types. Typically, customers include a type field to differentiate distinct types.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "airline": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" }, "documentkey": "airline_10" } |
When you want to create an index of airline documents, you can simply add the type field for the WHERE clause of the index.
CREATE INDEX travel_info ON `travel-sample`(name, id, icoo, iata) WHERE type = 'airline';
This will create an index only on the documents that have (type = ‘airline’). In your queries, you’d need to include the filter (type = ‘airline’) in addition to other filters so this index qualifies.
You can use complex predicates in the WHERE clause of the index. Various use cases to exploit partial indexes are:
- Partitioning a large index into multiple indices using the mod function.
- Partitioning a large index into multiple indices and placing each index into distinct indexer nodes.
- Partitioning the index based on a list of values. For example, you can have an index for each state.
- Simulating index range partitioning via a range filter in the WHERE clause. One thing to remember is Couchbase N1QL queries will use one partitioned index per query block. Use UNION ALL to have a query exploit multiple partitioned indices in a single query.
8. Adaptive Index
An adaptive index creates a single index on the whole document or set of fields in a document. This is a form or array index using {“key”: value} pair as the single index key. The purpose is to avoid the bane of a query having to match the leading keys of the index in traditional indexes.
There are two advantages with Adaptive index:
- Multiple predicates on the keyspace can be evaluated using different sections of the same index.
- Avoid creating multiple indexes just to reorder the index keys.
- Avoid the index key-order.
Example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE INDEX `ai_self` ON `travel-sample`(DISTINCT PAIRS(ai_self)) WHERE type = "airport"; EXPLAIN SELECT * FROM `travel-sample` WHERE faa = "SFO" AND `type` = "airport"; { "#operator": "IntersectScan", "scans": [ { "#operator": "IndexScan2", "index": "ai_self", "index_id": "c564a55225d9244c", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "[\"faa\", \"SFO\"]", "inclusion": 3, "low": "[\"faa\", \"SFO\"]" } ] } ], "using": "gsi" } ... ] } |
The same index can be used for queries with other predicates as well. This reduces the number of indexes you’d need to create as the document grows.
|
1 2 3 4 |
EXPLAIN SELECT * FROM `travel-sample` WHERE city = "Seattle" AND `type` = "airport"; |
Considerations for usage:
- Since each attribute field has an index entry, the size of the indexes can be huge.
- The adaptive index is an array index. It’s bound by the restriction of the array indexes.
Please see the detailed documentation on adaptive index at Couchbase documentation.
9. Duplicate Index
This isn’t really a special type of index, but a feature of Couchbase indexing. You can create duplicate indexes with distinct names.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX i1 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; CREATE INDEX i2 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; CREATE INDEX i3 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; |
All three indices have identical keys, identical WHERE clause; the only difference is the name of the indices. You can choose their physical location using the WITH clause of the CREATE INDEX. During query optimization, the query will choose one of the names. You see that in your plan. During query runtime, these indices are used in a round-robin fashion to distribute the load. This gives you scale-out, multi-dimensional scaling, performance, and high availability. Not bad!
Couchbase 5.0 makes the duplicate index SIMPLER. Instead of creating multiple indexes with distinct names, you can simply specify the number of replica indexes you require.
|
1 2 3 4 |
CREATE INDEX i1 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’ WITH {"num_replica" : 2 }; |
This will create 2 additional copies of the index in addition to the index i1. Load balancing and HA features are the same as an equivalent index.
10. Covering Index
Index selection for a query solely depends on the filters in the WHERE clause of your query. After the index selection is made, the engine analyzes the query to see if it can be answered using only the data in the index. If it does, the query engine skips retrieving the whole document. This is a performance optimization to consider while designing the indices.
All Together Now!
Let’s put together a partitioned composite functional array index now!
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX travel_all ON `travel-sample`( iata, LOWER(name), UPPER(callsign), ALL DISTINCT ARRAY p.model FOR p IN jets END), TO_NUMBER(rating), meta().id ) WHERE LOWER(country) = "united states" AND type = "airline" WITH {"num_replica" : 2} |
Rules for Creating the Indexes.
So far, we looked at the types of indexes. Let’s now look at how we go about designing the indexes for your workload.
Rule #1: USE KEYs
In Couchbase, each document in a bucket has a user-generated unique key. The documents are distributed among different nodes by hashing this key (we use consistent hashing). When you have the document key, you can fetch the documents directly from the Applications (via SDKs). Even when you have the document keys, you may want to do fetch and do some post-processing via N1QL. That’s when you use the USE KEYS method.

Example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT name, address FROM `travel-sample` h USE KEYS [ "hotel_10025", "hotel_10026", "hotel_10063", "hotel_10064", "hotel_10138", "hotel_10142", "hotel_10158", "hotel_10159", "hotel_10160", "hotel_10161", "hotel_10180", "hotel_10289", "hotel_10290", "hotel_10291", "hotel_1072", "hotel_10848", "hotel_10849", "hotel_10850", "hotel_10851", "hotel_10904" ] WHERE h.country = "United Kingdom" AND ARRAY_LENGTH(public_likes) > 3; |
The USE KEYS access method can be used even when you do joins. Here’s an example:
SELECT * FROM ORDERS o USE KEYS ["ord::382"] INNER JOIN CUSTOMER c ON KEYS o.id;
In Couchbsae 5.0, indexes are used only to process the first keyspace (bucket) of each FROM clause. Subsequent keyspaces are processed via direct fetch of the document.
SELECT * FROM ORDERS o INNER JOIN CUSTOMER c ON KEYS o.id WHERE o.state = "CA";
In this statement, we process the ORDERS keyspace via an index on (state) if it’s available. Otherwise, we use the primary index to scan ORDERS. We then fetch the CUSTOMER documents matching the id in the ORDERS document.
Rule #2: USE COVERING INDEX
We discussed the types of index earlier in the article. The right index serves two purposes:
- Reduce the working set for the query to speed up query performance
- Store and provide additional data even.
When a query can be answered completely by the data stored in the index, the query said to be covered by the covering index. You should try to have most, if not all, of your queries to be covered. This will reduce the processing burden on the query service, reduce additional fetch from the data service.
The index selection is still done based on the predicates in the query. Once the index selection is done, the optimizer will evaluate to see if the index contains all the required attributes for the query and creates a covered index path access.
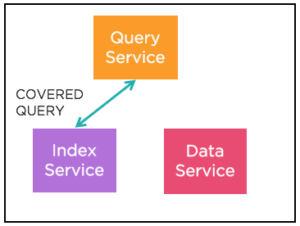
Examples:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE INDEX idx_cx3 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; /* The query below won’t be covered since you said: SELECT * */ SELECT * FROM CUSTOMER WHERE state = 'CA’ AND status = 'premium'; /* The index has all three fields required by the query. */ /* Query will be covered, as shown in the explain plan. */ SELECT status, state, city FROM CUSTOMER WHERE state = 'CA' AND status = 'premium'; { "#operator": "IndexScan2", "covers": [ "cover ((`CUSTOMER`.`state`))", "cover ((`CUSTOMER`.`city`))", "cover (((`CUSTOMER`.`name`).`lastname`))", "cover ((meta(`CUSTOMER`).`id`))" ], "filter_covers": { "cover ((`CUSTOMER`.`status`))": "premium" }, "index": "idx_cx3", "index_id": "18f8209144215971", "index_projection": { "entry_keys": [ 0, 1 ] } |
Note that the status field in the WHERE clause of the index (status = ‘premium’) is also covered. We know every document in the index has a field called status with a value ‘premium’. We can simply project this value. “Filter_covers” field in the explain shows this information.
As long as the index has the field, a query can do additional filtering, joins, aggregation, pagination after fetching the data from the indexer without fetching the full document.
Rule #3: USE THE INDEX REPLICATION
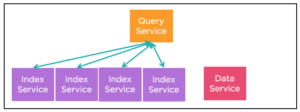
In a Couchbase cluster, you have multiple index services. Prior to Couchbase 5.0, you can manually create replica (equivale) indexes to improve throughput, load balancing, and high availability.
Prior to 5.0:
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx1 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; CREATE INDEX idx2 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; CREATE INDEX idx3 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; |
We recognize the equivalency of these three indexes because the key expressions and the WHERE clause are exactly the same.
During the query optimization phase, the N1QL engine picks up one of the three indexes for index scan (assuming other requirements are met) to create the query plan. During query execution, the query prepares the scan package and sends an index scan-request. During this process, based on the load statistics, we send the request to one of them. The idea is, over time, each of them will have a similar load.
This process of creating replica indexes (equivalent indexes) is made easier with a simple parameter.
|
1 2 3 4 |
CREATE INDEX idx1 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium' WITH { "num_replica":2 }; |
This is the same as creating three distinct, but equivalent indexes.
Rule #4: INDEX BY WORKLOAD, NOT BY BUCKET/KEYSPACE
Consider the whole application workload and service level agreements (SLAs) for each of the queries. The queries that have millisecond latency requirements with high throughput will require customized and replica indexes, whereas others could share indexes.
There may be keyspaces on which you simply do set & get operations or can issue queries with USE KEYS. These keyspaces won’t need any indexes.
Analyze the queries to find the common predicates, projections from a keyspace. You can optimize the number of indexes based on common predicates. If one of your queries does not have a predicate on the leading key or keys, see if adding (field IS NOT MISSING) makes sense to that the index can be shared.
It’s fine to have a primary index while developing your application or queries. But, before you test, create the right indexes and drop the primary index from your system, unless your application uses cases described in the “Primary Index” section. If you do have a primary index in production and queries end up doing a full primary scan with a full span on the index, you’re asking for trouble. In Couchbase, the primary index indexes all the documents in the bucket.
Every secondary index in Couchbase should have a WHERE clause, with at least a condition on the document type. This isn’t enforced by the system, but it’s good design.
|
1 2 3 |
CREATE INDEX def_route_src_dst ON `travel-sample` (`sourceairport`, `destinationairport`) WHERE (`type` = "route"); |
Creating the right indexes is one of the best practices for performance optimization. This isn’t the only thing you’d need to do to get the best performance. Cluster configuration, tuning, SDK configuration, use of prepared statements all play a significant role.
Rule #5: INDEX BY PREDICATE, NOT BY PROJECTION
This seems like an obvious rule. But, I come across folks making this mistake every now and then.
Consider the query:
|
1 2 3 4 |
SELECT city, state, status FROM CUSTOMER WHERE state = 'CA' AND status = 'premium'; |
Any of the following indexes can be used by the query:
|
1 2 3 4 5 6 |
Create index i1 on CUSTOMER(state); Create index i2 on CUSTOMER(status); Create index i3 on CUSTOMER(state, status); Create index i4 on CUSTOMER(status, state); Create index i5 on CUSTOMER(state) WHERE status = “premium”; Create index i6 on CUSTOMER(status) WHERE status = “CA”; |
To make the index completely cover the query, simply add the city field to index 3-6.
However, if you have an index that has the city as the leading key, the optimizer won’t pick up the index.
|
1 2 3 |
Create index i7 O ON CUSTOMER(city, state) WHERE status = “premium”; |
See the detailed article on how the index scan works in various scenarios to optimize the index: https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
Rule #6: ADD INDEXES TO MEET THE SLAs
For relational databases, three things were most important: performance, performance, performance.
For NoSQL databases, three things matter most: performance at scale, performance at scale, performance at scale.
Your queries running basic performance test on your laptop is one thing, running the high throughput, low latency queries on the cluster is another thing. Fortunately, in Couchbase, it’s easy to identify and scale the bottleneck resources independently, thanks to the multi-dimensional scaling. Each of the services in Couchbase is abstracted into distinct service: data, index, query. Couchbase console has statistics on each of the services independently.
After you’ve created indexes for your queries, optimized the indexes for the workload, you can add additional replica (equivalent) indexes to improve the latency because we load balance the scans among the replica indexes.
Rule #7: INDEX TO AVOID SORTING
The index already has the data in the sorted order of the index keys. After the scan, the index returns the results in the index key order.
|
1 2 3 |
CREATE INDEX idx3 ON `travel-sample`(state, city, name.lastname) WHERE status = 'premium'; |
The data is stored and returned in the order: state, city, name.lastname. So, if you have a query, that expects the data in the order of state, city, name.lastname, an index will help you to avoid the sort.
In this example below, the results are ordered by name.lastname, the third key of the index. Therefore, it’s necessary to sort the resultset on name.lastname. Explain will tell you if the plan requires this sort.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
EXPLAIN SELECT state, city, name.lastname FROM `travel-sample` WHERE status = ‘premium’ AND state = ‘CA’ AND city LIKE ‘san%’ ORDER BY name.lastname; { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "index": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "(((cover ((`travel-sample`.`status`)) = \"premium\") and (cover ((`travel-sample`.`state`)) = \"CA\")) and (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] } ] } } ] }, { "#operator": "Order", "sort_terms": [ { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" } ] }, "text": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY name.lastname;" } |
The query below has the perfect match for the index keys. So, the sort is unnecessary. In the explain output, the order operator is missing.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
EXPLAIN SELECT state, city, name.lastname FROM `travel-sample` WHERE status = ‘premium’ AND state = ‘CA’ AND city LIKE ‘san%’ ORDER BY state, city, name.lastname; { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "index": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "maxParallelism": 1, "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "(((cover ((`travel-sample`.`status`)) = \"premium\") and (cover ((`travel-sample`.`state`)) = \"CA\")) and (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" } ] } } ] } ] }, "text": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY state, city, name.lastname;" } |
Exploiting the index sort order may not seem important until you see the pagination use case. When the query has specified OFFSET and LIMIT, an index can be used for efficiently eliminating the documents which the application does not care or need. See the article on pagination for details on this.
N1QL optimizer first selects the index based on predicates in the query (filters) and then verifies if the index can cover all the query references in projection and order by. After that, the optimizer tries to eliminate the sorting and decide on the OFFSET and LIMIT pushdown. The explain shows if the OFFSET and LIMIT were pushed to the index scan.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
"keyspace": "travel-sample", "limit": "20", "namespace": "default", "offset": "100", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ] |
Rule #8: Number of indexes
There’s no artificial limit on the number of indexes you can have in the system. If you’re creating a large number of indexes on a bucket that has the data, use the deferred build option so the data transfer between the data service and index service is efficient.
Rule #9: Index during INSERT, DELETE, UPDATE
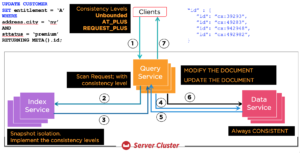
The index is maintained asynchronously. Your data updates via key-value API or any N1QL statements only update the documents in the bucket. The index receives the notification of changes via the stream and applies the changes to the index. Here is the sequence of operations for an UPDATE statement. The statement uses the index to qualify the documents to update; fetch the documents and update them; then write the documents back and return any data requested from the UPDATE statement.
Rule #11: INDEX KEY ORDER AND PREDICATE TYPES
Index scan requests created by the query users’ first N consecutive keys of the index. So, the order of the index key is important.
Consider a query with various predicates:
|
1 2 3 4 5 |
SELECT cid, address FROM CUSTOMER WHERE state = ‘CA’ AND type = ‘premium’ AND zipcode IN [29482, 29284, 29482, 28472] AND salary < 50000 AND age > 45; |
These are general rules for the order of keys in the index. Keys can be simpler scalar attributes or expressions which return scalar values: e.g. UPPER(name.lastname).
- First priority is keys with equality predicates. In this query, it’s on state and type. When there are multiple predicates of the same type, choose any combination.
- Second priority is keys with IN predicates. In this query, it’s on zipcode.
- Third priority is the less than (<) predicates. In this case, it’s on salary.
- Fourth priority is the between predicates. This query does not have a between predicate.
- Fifth priority is the greater-than (>) predicates. In this query, it’s on age.
- Sixth priority is the array predicates: ANY, or EVERY AND ANY, predicates after UNNEST.
- Look to add additional fields for the index to cover the query.
- After doing this analysis, look for any expressions that can be moved to WHERE clause. For example, in this case, type = “premium” can be moved because the type field is designated by the users to identify the type of customers.
With this, we come up with the following index.
|
1 2 3 4 5 |
CREATE INDEX idx_order ON CUSTOMER ( state, zipcode, salary, age, address, cid ) WHERE type = "premium"; |
Rule #12: Understand how to read EXPLAIN and PROFILING
No matter how many rules you follow, you’ll have to understand query plans and profile, monitor the system under load, and tune it. The ability to understand and analyze the query plan and profiling information is the key to tuning a query and a workload. There are two fine articles on those topics. Go through and try out the examples.
- https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
- https://www.couchbase.com/blog/profiling-monitoring-update-2/
References
- Nitro: A Fast, Scalable In-Memory Storage Engine for NoSQL Global Secondary Index: https://vldb2016.persistent.com/industrial_track_papers.php
- Couchbase: https://www.couchbase.com
- Couchbase Documentation: https://docs.couchbase.com
- N1QL: A Practical Guide: https://www.couchbase.com/blog/n1ql-practical-guide-second-edition/
- Index Advisor: Rules for Creating Indexes: https://www.slideshare.net/journalofinformix/couchbase-n1ql-index-advisor
Hi Keshav,
I am new to CB, so pls pardon my understanding.
The foll. is mentioned in this blog
“So, when you do the primary scan, the query will use the index to get the document-keys and fetch all the documents in the bucket and then apply the filter. So, this is VERY EXPENSIVE.”
I have read this at many places and same is what I was told i.e. a primary index should be avoided. I am unable to understand why? In Oracle or any other RDBMS, Primary/Unique key based lookup is the fastest/best. I understand that if the N1QL query has no predicate then it will scan the entire bucket i.e. it will scan all keys using the Primary index and that would be expensive. But if the key is specified in the predicate then wouldn’t it be the fastest?
In example 1, the specific key is mentioned in the predicate. So that should be almost as good getid(‘key’), isnt it?
Thanks
Hello pccb,
If you have the document key (this is the unique key within the bucket), you have a builtin access method and is the most efficient one from N1QL.
SELECT * FROM mybucket USE KEYS “cx:482:gn:284”;
You can also use primary index for this by issuing:
SELECT * FROM mybucket WHERE meta().id = “cx:482:gn:284”;
You can do smart range scans on the meta().id using primary index:
SELECT * FROM mybucket WHERE meta().id LIKE “cx:482:gn:%”;
Here are the things you do need to be aware of:
1. Couchbase bucket can documents all different types: customer, order, item,etc. Primary index will be across all these document types.
2. If developer/user carefully constructs the query to perform equality or limited range scan, using primary index is fine.
3. But, if someone issues a query without these guidelines or issues a query without any other qualifying index in production, we endup using primary scan and scan & fetch the whole index and all the documents in the bucket. Typically, that’s a bad thing in production.
Hello,
Is there a way to avoid an index i.e. make CB NOT use the index?
What we are trying to achieve is as follows:
There will be the Primary index, so that developers can try out their queries. However, once they have finalized the queries including the index that is needed, we would like to them to execute it while making sure that it is not using the Primary Index. Reason being, even after creating the appropriate secondary index, it might be that the query is still using the Primary index and the developer has not realized it. So if there is a way to avoid the usage of Primary Index then they would run the query using that option.
Thanks
Thanks for the feedback. I’ve opened an improvement to add this: https://issues.couchbase.com/browse/MB-32109
Is there a typo or am I missing something:
CREATE INDEX travel_sched ON
travel-sample(ALL DISTINCT ARRAY v.day FOR v IN schedule END)
Is “ALL DISTINCT” valid syntax and what does it mean? I could not find it in the documentation!
Thanks