Esta es la Parte 2 de una serie centrada en el aprovechamiento de las capacidades arquitectónicas de alta disponibilidad y características de Couchbase Server en Google Cloud Platform (GCP). Los conceptos de Couchbase discutidos aquí se pueden aplicar universalmente a cualquier entorno de nube donde despliegues tu clúster, pero los pasos y comandos son específicos para GCP.
Parte 1 cubrió cómo lograr la resiliencia de nodos y servicios de Couchbase (Query, Index, Data, Search, Eventing, Analytics, Backup). Mostramos cómo hacerlo mediante la asignación de servicios a nodos específicos repartidos en zonas de disponibilidad de GCP específicas dentro de una región. Puede leer ese blog aquí.
En esta entrada del blog, habilitamos Cruz Replicación de centros de datos (XDCR) entre dos clústeres de Couchbase que se ejecutan en GCP a través de dos regiones diferentes. Esto implementa la base de datos Alta disponibilidad (HA)recuperación de desastres o aplicación de datos geolocalizados. XDCR no es nuevo en Couchbase y está disponible con cada cluster de Couchbase instalado. XDCR puede utilizarse entre dos versiones cualesquiera de Couchbase Server (desde la versión 2.5).
Los cinco escenarios de la prevención de la pérdida de datos
La arquitectura de Couchbase Server proporciona resiliencia de datos (por ejemplo, prevención de pérdida de datos) en varios niveles diferentes - desde el nivel de mutación de datos individuales hasta el nivel de cluster. Estos son cinco de esos niveles con más detalle:
Niveles de fallo y durabilidad de escritura
Datos Escriba a a los buckets de Couchbase se les pueden asignar requisitos de durabilidad. Por ejemplo, Couchbase puede ser instruido para actualizar el documento especificado en múltiples nodos (en memoria y/o ubicaciones de disco a través del cluster) antes de considerar que la escritura sea consignada. Cuanto mayor sea el número de ubicaciones de memoria/disco especificadas en los requisitos, mayor será el nivel de durabilidad alcanzado. Puede obtener más información sobre la configuración de estos distintos niveles en esta página de documentación del producto.
Fallo de nodo y conmutación por error
Couchbase Datos, Índice y Búsqueda de texto completo permiten crear réplicas en los niveles de documento e índice, de modo que cuando un nodo que ejecuta uno de estos servicios falla, se puede utilizar otra réplica. Por ejemplo, las réplicas existentes que viven en los nodos aún en ejecución para esos servicios pasan a estar disponibles para que tus aplicaciones puedan seguir funcionando plenamente. Puedes leer en detalle cómo la arquitectura subyacente de Couchbase soporta esta capacidad en este blog, Bases de datos distribuidas: Una visión general.
Disponibilidad en la nube y fallos en la zona del bastidor
Aprovechar Escala multidimensional (MDS) y Conocimiento del grupo de servidores protege sus aplicaciones de la pérdida de acceso a los datos debido a una estante o nube zona de disponibilidad fallo. La primera parte de esta serie de blogs trata sobre cómo separar los servicios de Couchbase en nodos independientes dentro de un clúster que se ejecuta en diferentes bastidores físicos de un centro de datos o en zonas de disponibilidad de un proveedor en la nube.
Fallos en la región de la nube y el centro de datos
La replicación es la clave para proporcionar alta disponibilidad y tolerancia a fallos a nivel de clúster. XDCR es una tecnología de replicación de memoria a memoria de alto rendimiento que se utiliza para replicar datos entre dos clústeres de Couchbase. Esto es complementario a la replicación intra-clúster detrás de nuestro auto sharding de datos que está integrado en la arquitectura de Couchbase. XDCR proporciona replicación asíncrona y mantiene la consistencia de los datos entre los sitios a través de la consistencia eventual. En este blog veremos cómo implementar esta capacidad entre dos clústeres de Couchbase separados en diferentes regiones de GCP.
"Fracaso de "Tu mundo
Copias de seguridad del clúster Los clientes a veces preguntan: "¿Por qué necesito hacer copias de seguridad si ya tengo disponibilidad 100%?". La mejor respuesta a esta pregunta es otra pregunta: "¿Qué harías si se introducen datos corruptos en tu clúster desde un sistema o aplicación aguas arriba?". Esta es una de las pocas desventajas de la replicación de memoria a memoria: los datos corruptos probablemente infestarán otros clústeres rápidamente, por lo que tendrás que restaurar una copia de seguridad de un punto en el tiempo que no esté corrupta. Este escenario es muy raro y esperamos que nunca sea encontrado por nuestros clientes, pero deberías evaluar tus prácticas actuales de copias de seguridad de Couchbase por si acaso. En Couchbase 7 introdujimos la función Servicio de copias de seguridad para facilitar aún más la automatización de su estrategia de copia de seguridad y restauración. Más información aquí.
Cinco pasos para implementar la replicación entre centros de datos (XDCR) con Couchbase en GCP
Estos son los pasos de alto nivel cubiertos en este blog para implementar XDCR entre clusters regionales GCP Couchbase:
- Configurar 2 clusters Couchbase separados en diferentes regiones de la CME
- Habilitar el viaje-muestra conjunto de datos en Cluster 1 que serán los datos de origen para una replicación unidireccional
- Crear un bucket vacío en el Cluster 2
- Crear un flujo XDCR del Cluster 1 al Cluster 2 para un escenario HA activo/pasivo
- Cree un flujo XDCR desde Cluster 2 a Cluster 1 para un escenario HA activo/activo o para reforzar la geolocalización de los datos.
Primer paso
Siga las instrucciones de Parte 1 para poner en marcha dos clústeres Couchbase separados en diferentes regiones de GCP, tales como us-este1 y us-central1. Esto es similar a desplegar Couchbase en dos centros de datos diferentes en distintas ubicaciones geográficas para proteger sus entornos de fallos geográficos de la infraestructura de red.
Paso 2
En la interfaz de usuario de Couchbase para GCP-WEST cluster, vaya al Ajustes y haga clic en el botón Cubos de muestra en la esquina superior derecha de la pantalla:
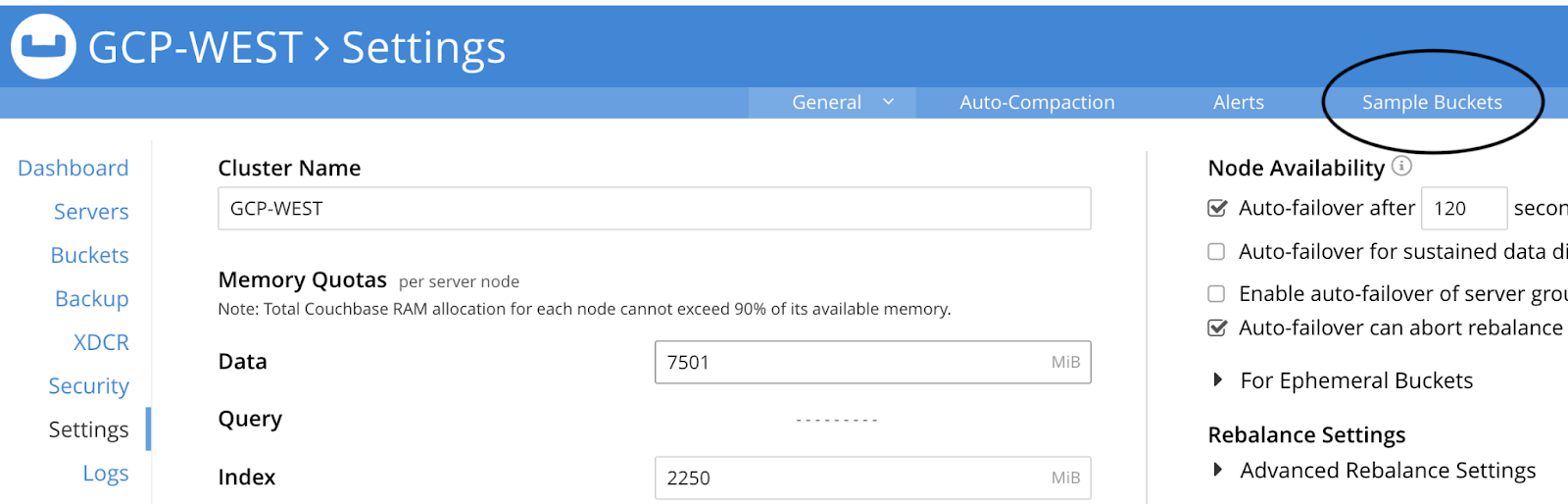
A continuación, marque la casilla situada junto a viaje-muestra y haga clic en Cargar datos de muestra:
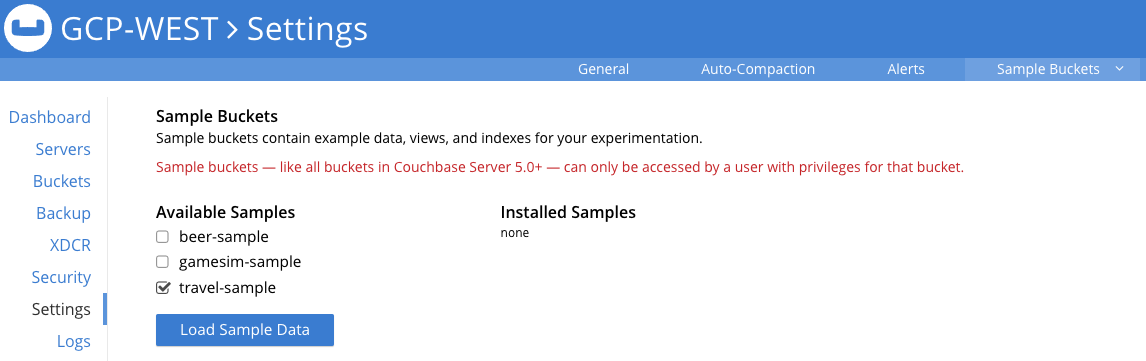
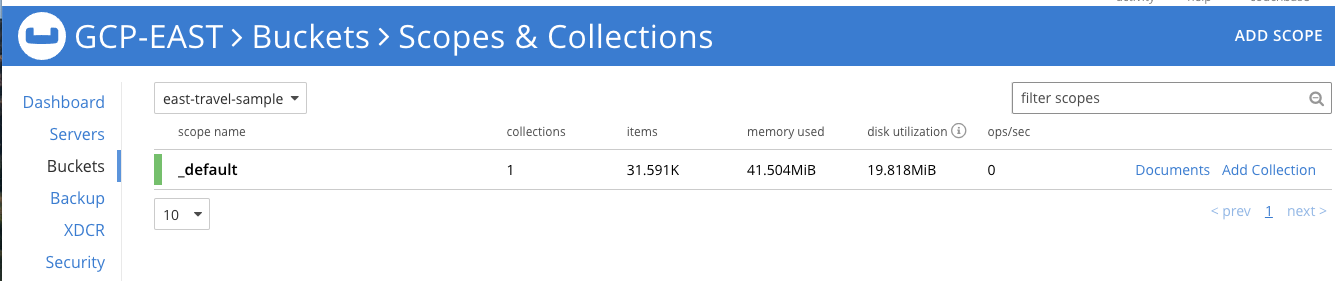
Espere un par de minutos para cargar el conjunto de datos y, a continuación, haga clic en el botón Cubos en la interfaz de usuario para ver el nuevo cubo llamado viaje-muestra. Todos los datos se cargan una vez que vea el recuento de elementos que se muestra a continuación (versión 7.x):

Este será el fuente para nuestro flujo XDCR entre el GCP Este y Oeste clusters regionales. Antes de definir y habilitar un flujo para replicar estos datos, debemos crear un bucket vacío de destino en el clúster de destino para recibir los datos.
Paso 3
En el segundo clúster, GCP-EAST, en la interfaz de administración, vaya a la sección Cubos y haga clic en AÑADIR CUBO en la esquina superior derecha:

Entonces verá esta ventana y podrá rellenar los valores necesarios para crear un cubo de destino vacío.
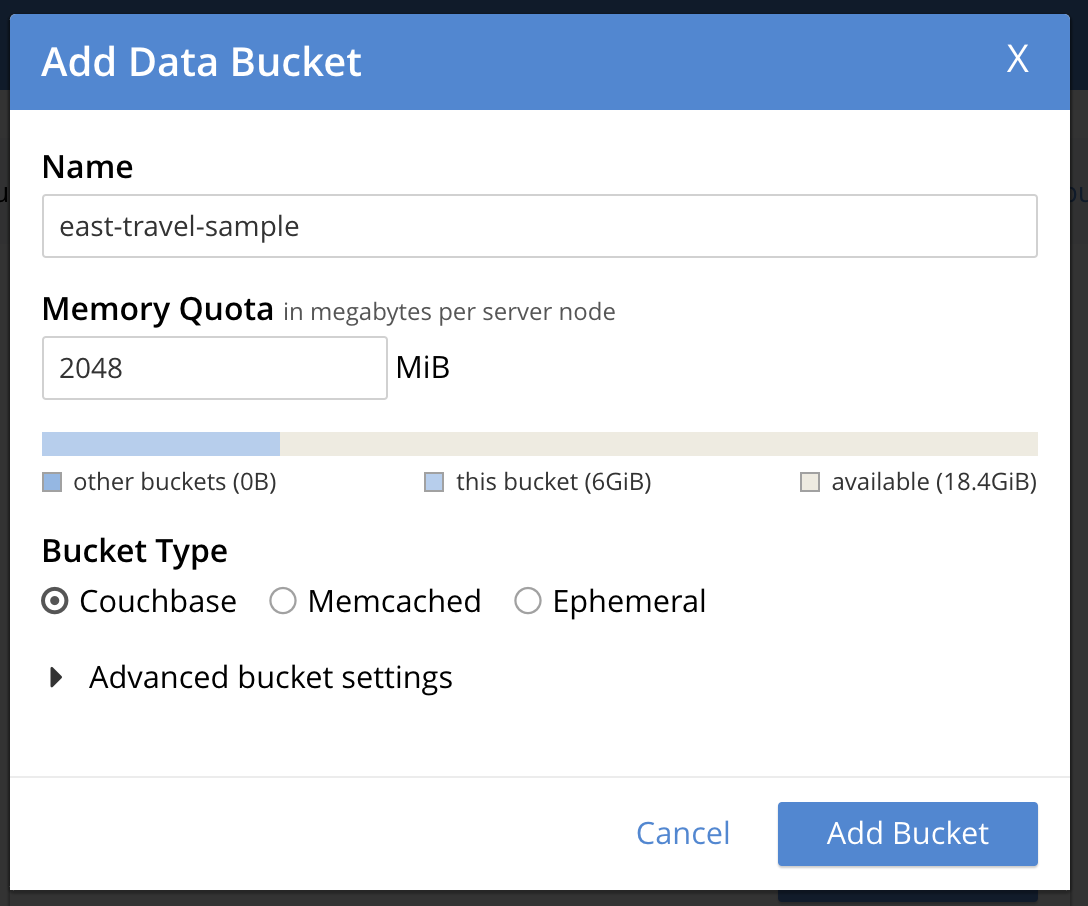
Una vez que haga clic en Añadir cubo debería verlo listado inmediatamente. He nombrado el bucket de forma diferente al bucket fuente para ayudar a saber de qué cluster son las capturas de pantalla. En la vida real, es probable que desee el mismo nombre para que los valores de cadena de su aplicación no tendrá que cambiar en el caso de que usted está cambiando de un clúster a otro.

Paso 4
Para aplicar una estrategia de clúster activo/pasivo, creamos un flujo XDCR unidireccional desde nuestro GCP-WEST grupo viaje-muestra cubo a nuestro GCP-EAST grupo este-viaje-muestra cubo. En la interfaz de administración de GCP-WEST en el XDCR haga clic en AÑADIR REMOTO en la esquina superior derecha. Se abrirá otra ventana emergente.
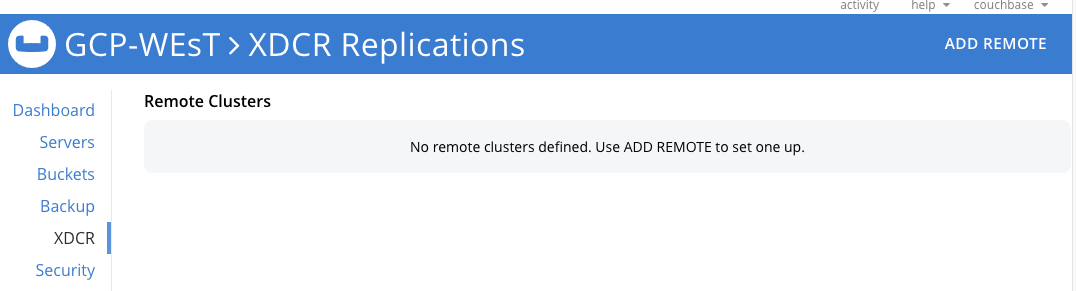
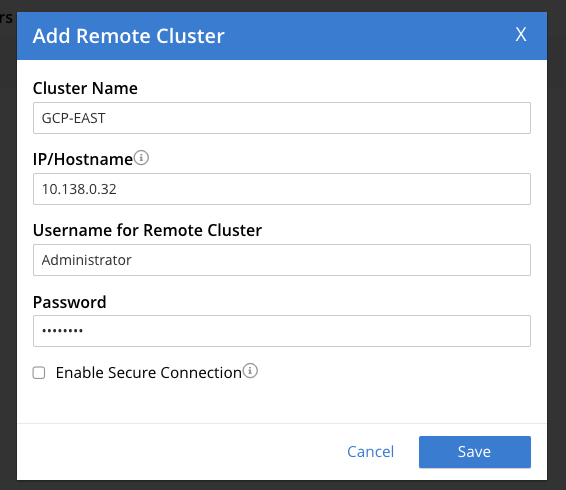
Haga clic en Guardar.
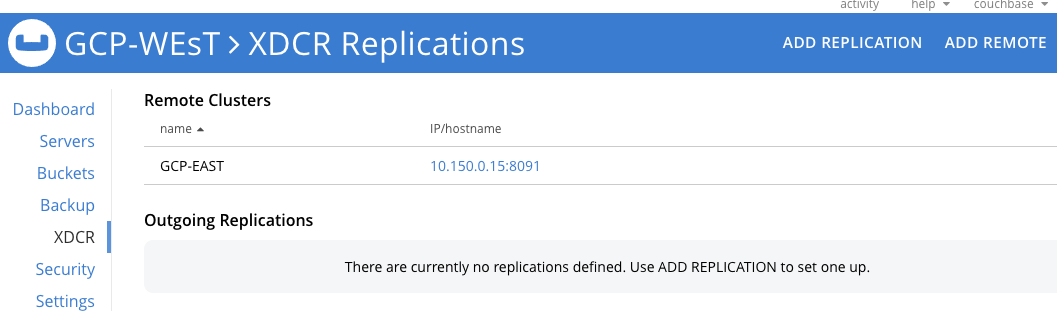
Ahora haga clic en AÑADIR REPLICACIÓN para llegar a la pantalla donde podemos crear un flujo unidireccional desde GCP-WEST a GCP-EAST.
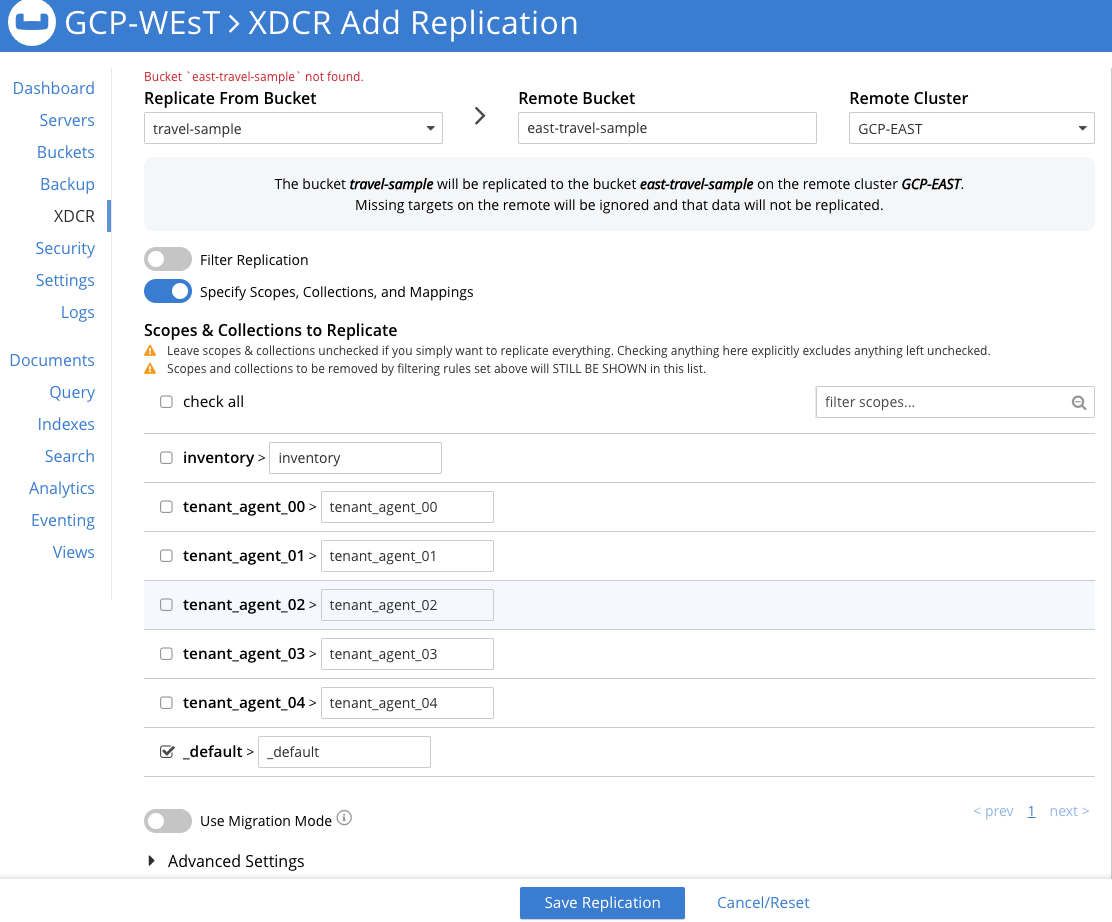
Una vez que haya introducido todas las personalizaciones del flujo, haga clic en Guardar Replicación y el flujo comenzará inmediatamente a mover datos al GCP-EAST racimo y continuará a medida que se produzcan mutaciones en el viaje-muestra cubo.
He optado por replicar únicamente el por defecto en este flujo para que pueda ver las diferentes opciones disponibles en la versión 7 para dividir o combinar ámbitos y colecciones como parte de un flujo de replicación. Puedes leer con más detalle sobre estas opciones en este post: Introduciendo soporte XDCR para Scopes y Colecciones en Couchbase 7.0.
Paso 5
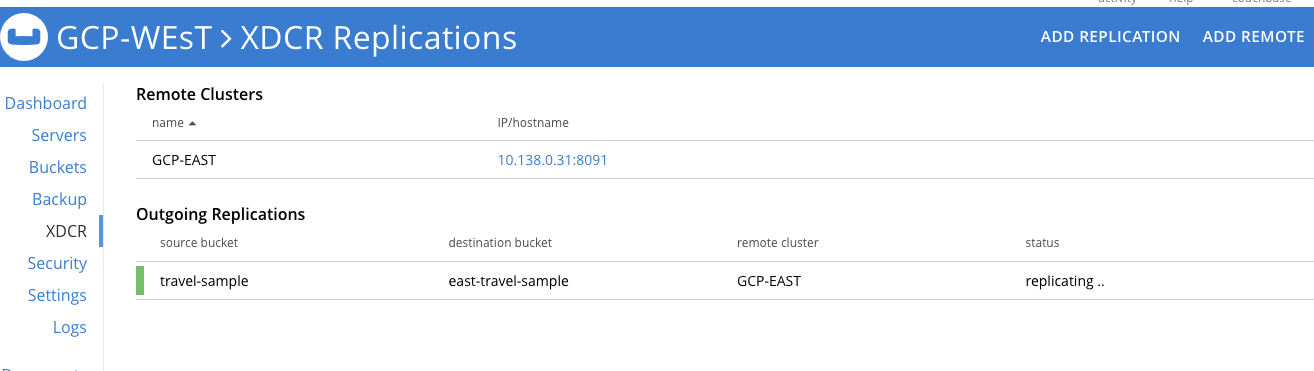
Si quieres configurar una estrategia de HA activa-activa para dos o más clusters de Couchbase necesitarás crear un stream XDCR unilateral que vaya del Cluster 1 al Cluster 2 y luego un stream inverso paralelo del Cluster 2 al Cluster 1 para el mismo conjunto de datos. Por ejemplo, como se muestra a continuación, hemos configurado un flujo unilateral en cada clúster para que cualquier mutación que afecte a un clúster se replique en el otro.
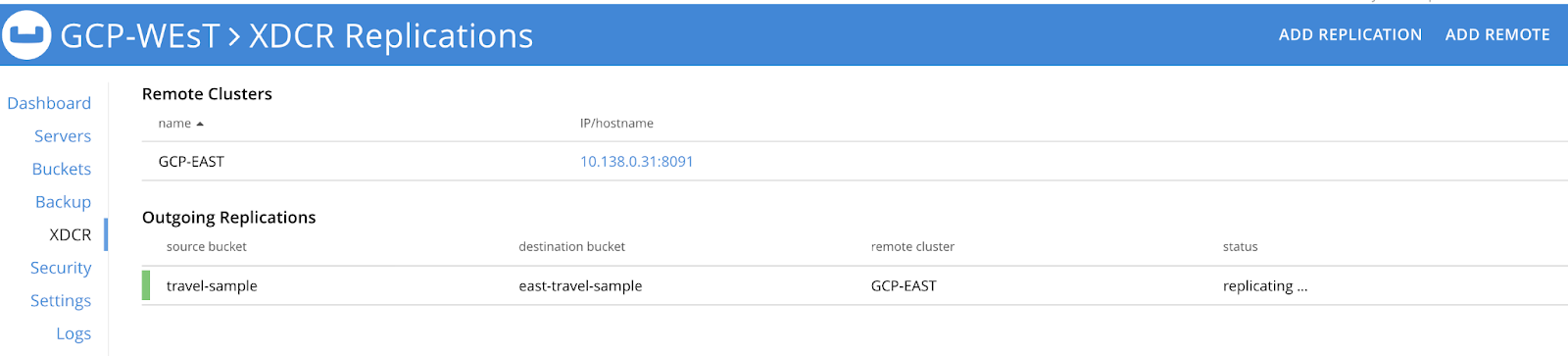
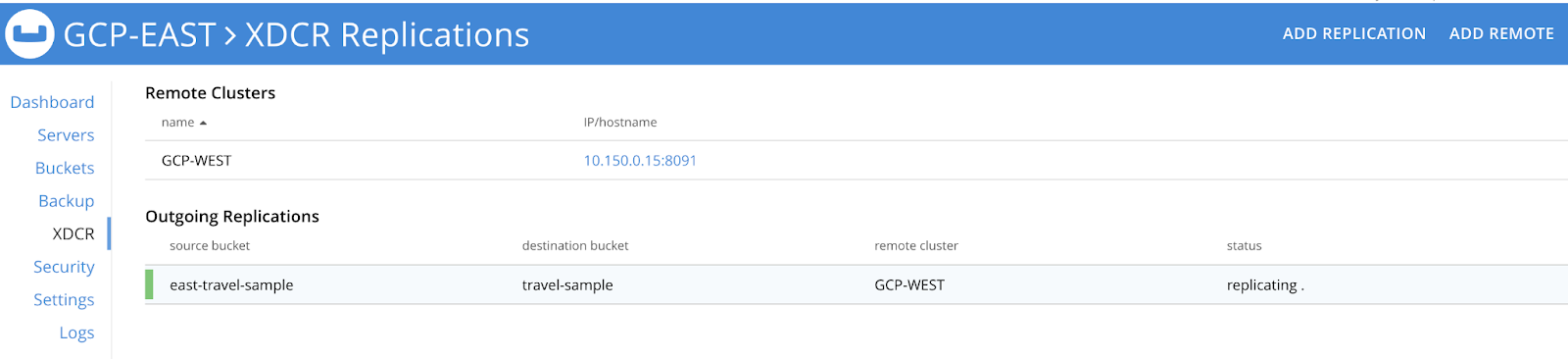
Si desea aplicar reglas de filtrado que respalden las políticas de localización de datos, puede consultar cómo implementar estas funciones. aquí en esta página de documentación.
Conclusión
Acabas de ver cómo puedes usar XDCR para implementar una pieza clave de tu estrategia de HA de Couchbase Cluster protegiendo las aplicaciones que usan Couchbase de un fallo regional del Centro de Datos o de la red en la nube.
Puede obtener más información sobre XDCR en estas fuentes:
- Descripción de la replicación entre centros de datos (XDCR) - Parte 1
- XDCR: Replicar en despliegues de nube híbrida con facilidad y control es de nuestro Conferencia de usuarios Couchbase Connect21En este artículo se cubren consejos y trucos (incluyendo nuevas características para Scopes y Collections) para sacar el máximo provecho de XDCR en la versión 7 de Couchbase Server, incluyendo nuevas características incluidas para Scopes & Collections.
Sigue leyendo estos recursos para empezar con Couchbase en GCP:
- Despliegue de Couchbase para alta disponibilidad en Google Cloud Platform - Parte 1 - Conocimiento del grupo de servidores
- Ofertas de Couchbase en GCP Marketplace
- Despliegue de Couchbase Server utilizando GCP Marketplace
- Prácticas recomendadas para ejecutar Couchbase en Google Compute Engine
