Vimos en un entrada anterior lo fácil que es configurar una réplica entre centros de datos (XDCR), hoy vamos a profundizar un poco más para entender por qué XDCR es una función tan estupenda.
En primer lugar, XDCR permite replicar datos entre clusters de distintos tamaños, lo que lo convierte en una excelente opción para catástrofe y recuperación plan. Aparte de eso, es una forma sencilla pero potente de acercar los datos a sus usuarios.
La replicación se realiza de memoria a memoria. Así, todas las escrituras se guardan primero en la memoria y luego se ponen en una cola de replicación, que las envía por la red a través de múltiples hilos. Por lo tanto, el rendimiento total sólo está limitado por la velocidad de la red.
También tiene en cuenta la topología, por lo que cuando se añaden o eliminan nodos del clúster de origen, no es necesario realizar ninguna acción en el clúster de destino. Restablecerá la conexión y se encargará de todo automáticamente.
Además, permite conocer las zonas de los bastidores, lo que ayuda a protegerse frente a fallos de varios nodos separando los datos activos y sus réplicas en "grupos" que pueden asignarse de forma que ocupen diferentes bastidores, zonas o hosts de máquinas virtuales.
Las réplicas se realizan a nivel de bucket (entre buckets de dos o más clusters), y pueden configurarse de la siguiente manera.
- Unidireccional: Sólo se replican los datos escritos en uno de los clusters, se utiliza cuando se quiere configurar un cluster standby por ejemplo.
- Bidireccional: (también conocido como despliegue activo-a-activo) donde ambos clusters pueden escribir datos y todos los cambios se sincronizan entre ellos. En resumen, un mapeo bidireccional no es más que dos réplicas unidireccionales que apuntan la una a la otra.
- Híbrido: Una combinación de topologías bidireccional y unidireccional.
Gracias a DCP, también puede pausar la replicación en cualquier momento y, una vez reanudada, la recuperación comienza en el punto de control más reciente.
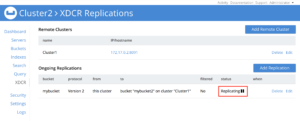
Protocolo de cambio de base de datos
Database Change Protocol (DCP) es un protocolo de flujo de alto rendimiento que utilizamos internamente para comunicar el estado de los datos mediante un registro de cambios ordenado. Es robusto y resistente ante errores transitorios, por ejemplo, si se interrumpe la comunicación, DCP es capaz de reanudarla desde el punto exacto de la última actualización realizada con éxito una vez recuperada la conectividad.
También está optimizado para enviar sólo los datos necesarios. Por ejemplo, si hay varios cambios en un documento, solo se marca la versión más reciente para replicarla.
XDCR se basa en DCP para propagar los cambios. De esta forma garantiza que el mismo documento se replicará entre todos los clusters independientemente de los problemas de conectividad.
Destaquemos también otras dos interesantes funciones de XDCR: la resolución de conflictos y el filtrado de datos:
Resolución de conflictos
Un conflicto se produce cuando el mismo documento se modifica en dos ubicaciones distintas antes de que se haya sincronizado entre ellas. Para mantener la coherencia, hay que elegir una versión como la "correcta". La resolución de conflictos proporciona un método para seleccionar de forma coherente y determinista qué versión del documento debe utilizarse.
La resolución de conflictos de Couchbase se establece durante la creación del cubo y no se puede cambiar más tarde. Actualmente, se soportan dos tipos de resolución de conflictos: Timestamp y Sequence Number.
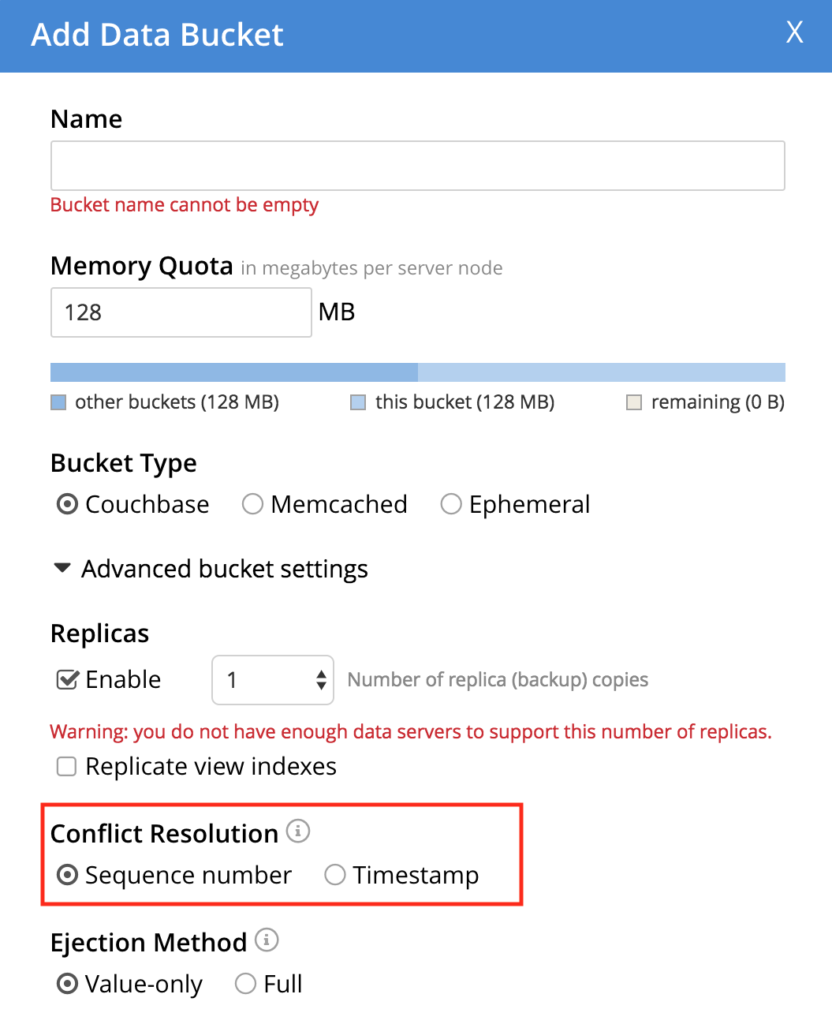
Número de secuencia
Después de cada mutación en un documento incrementamos un contador llamado número de revisiónde modo que cuando haya un conflicto entre dos documentos, el que tenga el número de revisión más alto tendrá prioridad en ambos clústeres.
Marca de tiempo
La resolución de conflictos basada en marcas de tiempo (TCR) es el mecanismo de resolución de conflictos más utilizado en las bases de datos. La TCR resuelve los conflictos seleccionando el documento con la marca de tiempo más reciente. Para que esto sea posible, es esencial que las marcas de tiempo creadas por cada servidor estén estrechamente alineadas.
Sin embargo, TCR puede aumentar la pérdida de datos, ya que ignora cuántas veces se ha actualizado un documento, y si uno de los relojes del servidor es rápido/lento acabarás con una resolución de conflictos desordenada. Por eso la opción por defecto en Couchbase es "Número de Secuencia".
Filtrado de datos
Por defecto, se replicarán todos los documentos de un bucket de destino, pero desde Couchbase 6.5 se puede utilizar Expresiones de filtrado para filtrar los datos que desea replicar.
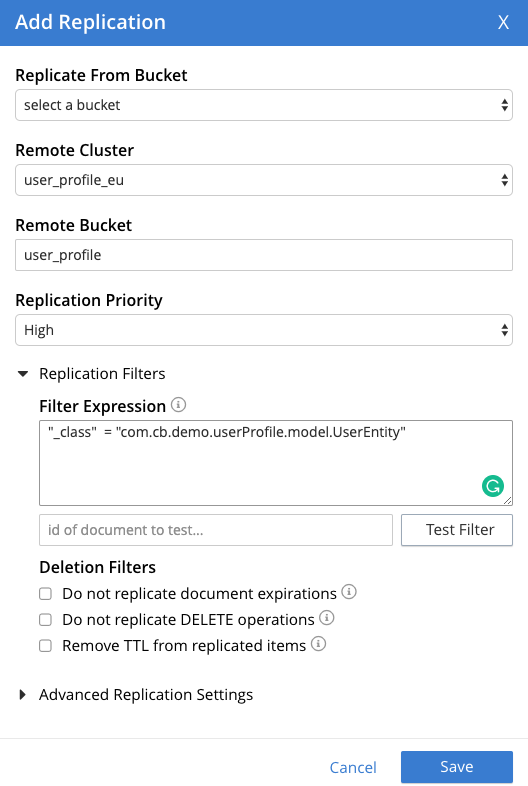
El filtrado avanzado admite varias construcciones lingüísticas para crear filtros, como regex, operadores aritméticos, lógicos y relacionales, palabras clave, expresiones, funciones numéricas, funciones de fecha, lookahead negativo, etc. Puede aplicar esas funciones a las claves, valores, metadatos y CAS del documento. Al igual que los predicados de las consultas N1QL, las expresiones pueden construirse utilizando las construcciones de lenguaje soportadas.
En el Filtros de supresión también puede optar por no replicar las operaciones de borrado, las caducidades de documentos o eliminar TTL y almacenarlo con fines de archivo.
Los filtros también pueden editarse sobre la marcha y la replicación continuará sin pausa/reanudación.
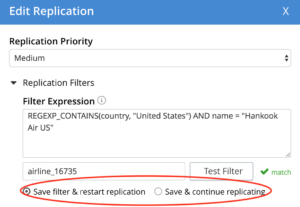
XDCR, por defecto, no vaciará ningún cubo cuando se modifiquen los filtros. Este paso debe ser ejecutado manualmente por el administrador si es necesario.
Conclusión
Si necesita un plan de recuperación ante desastres o simplemente le gustaría acercar sus datos al usuario, la replicación entre centros de datos (XDCR) es una función que debería considerar. Es fácil de configurar, casi no requiere mantenimiento y se ha probado a fondo en varios casos de uso de alta carga, como Amadeus, eBay y Viber.
Para obtener más información sobre XDCR con Couchbase, consulte la página Portal para desarrolladores de Couchbase o tuitéame a @deniswsrosa
Actualizado el 08/08/19 - Añadir nuevas funciones XDCR para Couchbase 6.5