Replicación entre centros de datos (XDCR) es una base de datos esencial.
XDCR garantiza la alta disponibilidad (HA) de la base de datos, la recuperación ante desastres y la geolocalización. Con la versión 7.0 de Couchbase Server, XDCR también admite nuevos espacios de nombres individuales llamados Ámbitos y Colecciones dentro de cada Bucket de base de datos. La compatibilidad con ámbitos y colecciones incluye también importantes mejoras arquitectónicas para la replicación entre centros de datos.
Con Scopes y Collections, ahora puede utilizar XDCR para la replicación de datos para microservicios específicos o la replicación de datos específicos de inquilinos para aplicaciones multiinquilino. En este artículo se presenta una nueva función de gestión de la replicación de colecciones y se describe una mejora de la arquitectura de XDCR entre bastidores.
Estas mejoras de XDCR permiten una nueva dimensión de casos de uso de la replicación. Posiciones de XDCR Servidor Couchbase 7.0 para admitir muchos más casos de uso de microservicios o aplicaciones multiinquilino, tanto hoy como en el futuro.
Antes de entrar en detalles, si no está familiarizado con la replicación entre centros de datos o las funciones relacionadas con ella, le recomendamos que lea esta información básica:
-
- Un rápido repaso a Conceptos básicos de la arquitectura XDCR
- Una inmersión profunda en Filtrado avanzado XDCR que tocaré a continuación
- Un artículo informativo sobre Prioridad de replicación XDCR - una característica de 6.5 que mencionaré brevemente a continuación
Bueno, vamos a sumergirnos.
Asignación de replicación de datos entre ámbitos y colecciones para XDCR
Si sólo tiene un clúster, la gestión de ámbitos y colecciones es relativamente sencilla. Sin embargo, dado que XDCR implica un escalado multidimensional, la asignación y gestión de estos nuevos espacios de nombres se vuelve más compleja.
Todavía puede existir una única replicación entre un cubo de origen y uno de destino. Este requisito no va a cambiar.
Pero con la introducción de Ámbitos y Colecciones, hay dos tipos de mapeos a soportar
la gestión de colecciones en el marco de una replicación cubo a cubo. Estos dos tipos son mapeo implícito y asignación explícita.
Un mapeo es un enlace entre dos espacios de nombres del mismo nivel, y existe en el contexto de una replicación de Cubo a Cubo. Un mapeo puede ser entre Ámbitos, o puede ser entre Colecciones.
Cada réplica de cubo a cubo utiliza una asignación implícita o explícita para realizar la réplica entre las colecciones de origen y de destino. Las réplicas utilizan una asignación implícita a menos que se especifique explícitamente lo contrario.
Asignación implícita entre colecciones
El mapeo implícito es el concepto según el cual debe establecerse un vínculo si existe el mismo espacio de nombres con nombre tanto en el Bucket de origen como en el de destino.
Si tanto el cubo de origen como el de destino contienen idénticamente llamados Ámbitos y/o Colecciones, entonces se mapean implícitamente. Por ejemplo, bajo mapeo implícito, si un Bucket fuente contiene un namespace Ámbito1.Colección1entonces la replicación tendrá lugar si el Bucket de destino también contiene Ámbito1.Colección1.
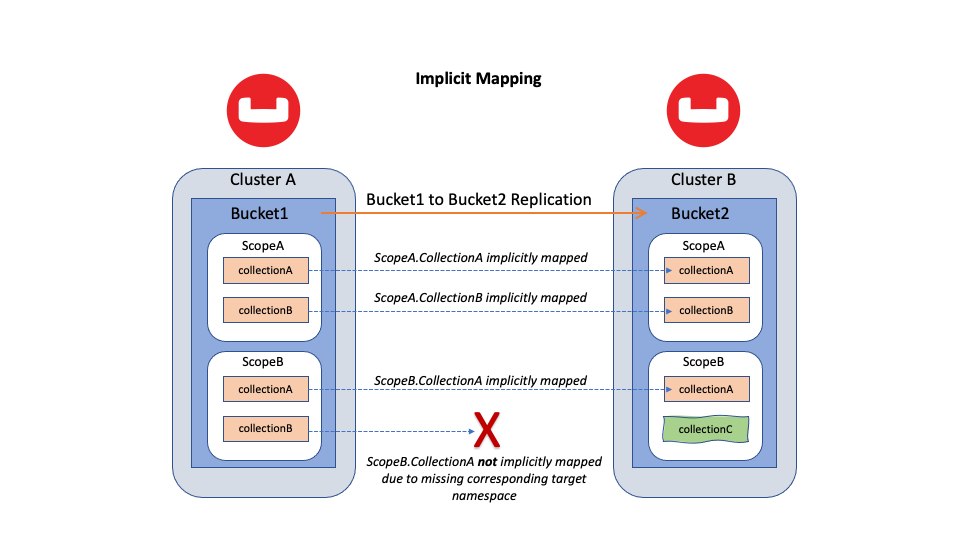
Figura 1: Replicación cruzada de centros de datos (XDCR) entre dos cubos dada la asignación implícita
La figura 1 muestra una replicación de cubo a cubo utilizando una asignación implícita. Tenga en cuenta que las colecciones predeterminadas de origen y las colecciones predeterminadas de destino se asignan juntas (no se muestra en la figura).
Los espacios de nombres no asignados no replicarse. Si los espacios de nombres no mapeados se crean más tarde, entonces XDCR recupera los datos que faltan usando una replicación de relleno. (Explicaré el backfill pipeline en una sección posterior).
Asignación explícita entre colecciones
Si necesita un control más granular de la replicación de datos, pruebe con la asignación explícita.
La asignación explícita requiere que los usuarios explícitamente definen las relaciones entre espacios de nombres. La asignación de un ámbito a otro ámbito implica la asignación implícita de todas las colecciones de ese ámbito. Sin embargo, la asignación de una colección a otra no afecta a ningún otro espacio de nombres.
La asignación explícita se realiza mediante el uso de normas de asignación a través de la interfaz de línea de comandos (CLI). La interfaz de usuario de la consola XDCR proporciona una abstracción para que no tengas que introducir reglas de asignación manualmente.
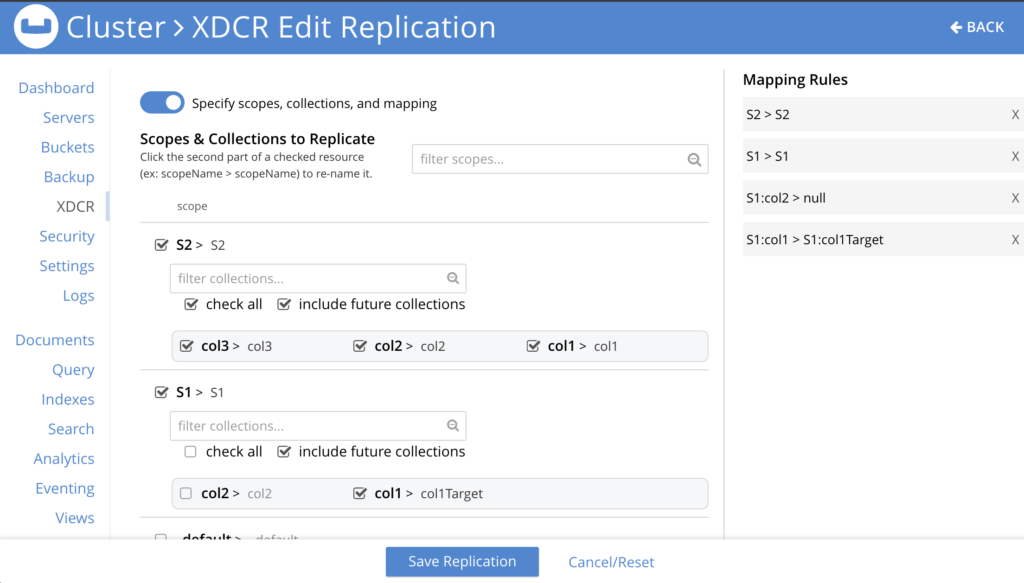
Figura 3: XDCR UI proporciona una experiencia fácil de usar para configurar la asignación explícita y oculta la necesidad de introducir manualmente las reglas de asignación.
La documentación de Couchbase Server incluye una explicación detallada de las reglas de asignación y cómo utilizarlas. Las reglas de mapeo le indican a XDCR mediante programación cómo hacer coincidir los espacios de nombres por nombre.
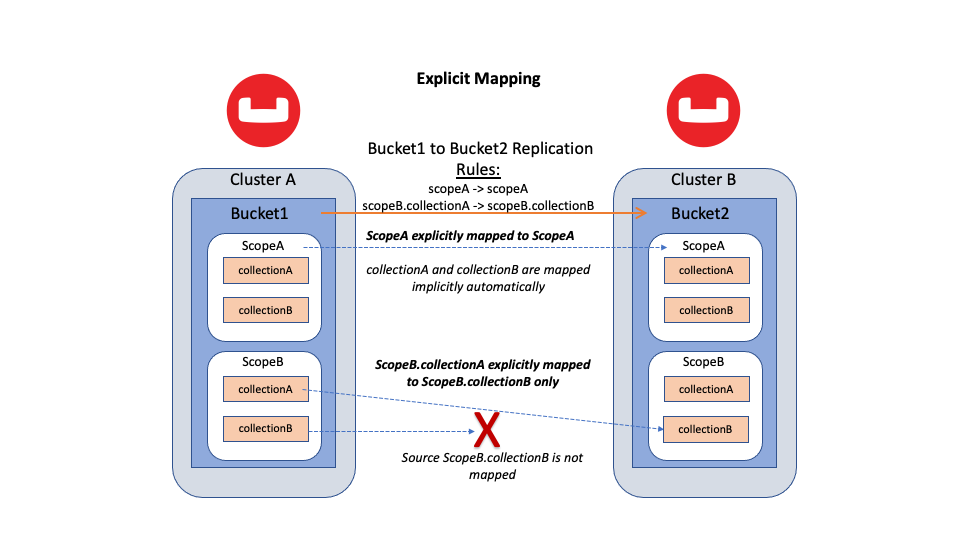
Figura 2: Replicación entre dos cubos mediante asignación explícita con dos reglas especificadas: una regla de asignación de ámbito a ámbito y una regla de asignación de colección a colección.
Las reglas de asignación explícitas le ofrecen un nuevo nivel de flexibilidad en la asignación de colecciones. También puede cambiar las reglas sobre la marcha. XDCR toma cualquier regla nueva y se asegura de forma inteligente de que todos los datos se repliquen. Se
Uso del modo migración para migrar a colecciones
Cuando actualizas a Couchbase Server 7.0, todos tus datos residen en la (nueva) Colección por defecto dentro de tu(s) Bucket(s) existente(s).
Utilizando modo de migración En la replicación entre centros de datos (XDCR), puede migrar datos a colecciones individuales de un bucket de destino. sin tiempo de inactividad de la aplicación. El modo de migración es una versión especializada de la asignación explícita. Utiliza el motor de filtrado avanzado de XDCR para realizar un filtrado basado en flujos a medida que los documentos se transmiten desde el Bucket de origen. En función de las reglas de migración que especifique, el documento se replicará en la colección de destino especificada.
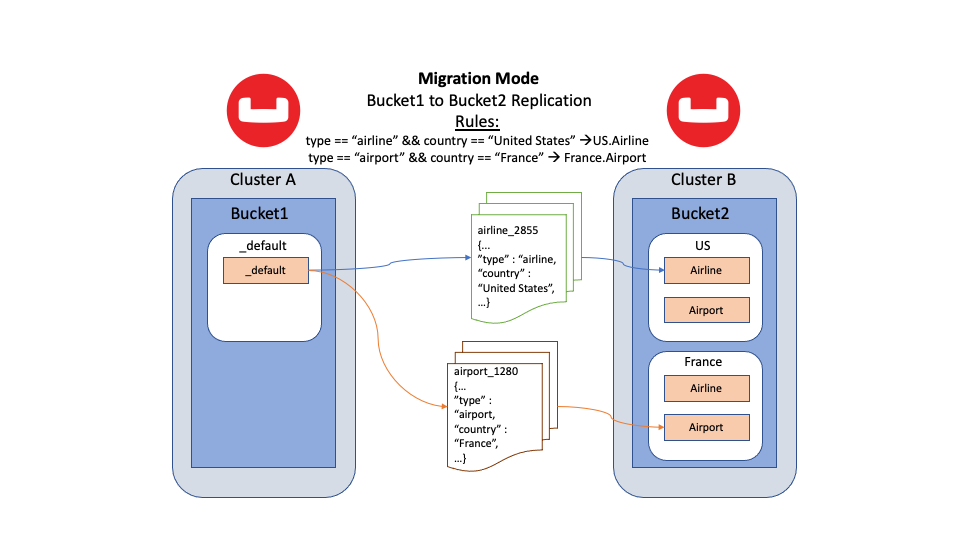
Figura 4: Modo de migración que utiliza distintas reglas de migración para encaminar los documentos a sus ubicaciones respectivas
La documentación de Couchbase Server tiene más detalles y ejemplos sobre el modo de migración.
Entre bastidores de XDCR con Scopes & Collections
Gasoducto principal
Cuando se crea una réplica, se traduce en un especificación de replicación y se almacena internamente. XDCR lee la especificación de replicación (y su configuración) y crea un archivo tubería que solicita datos del Bucket de origen. La canalización replica fielmente cada documento en el bucket de destino (salvo que se aplique algún filtro avanzado).
El proceso anterior sigue siendo el mismo en Couchbase Server 7.0. Así que si uno de tus Buckets fuente contiene múltiples Colecciones fuente, XDCR las solicita todas. Este comportamiento se llama tubería principal. El proceso principal replica un documento de origen en el destino utilizando una asignación implícita o explícita. Si el clúster de destino no contiene el espacio de nombres mapeado, XDCR deja el documento "en el suelo". A continuación, continúa replicando la siguiente mutación.
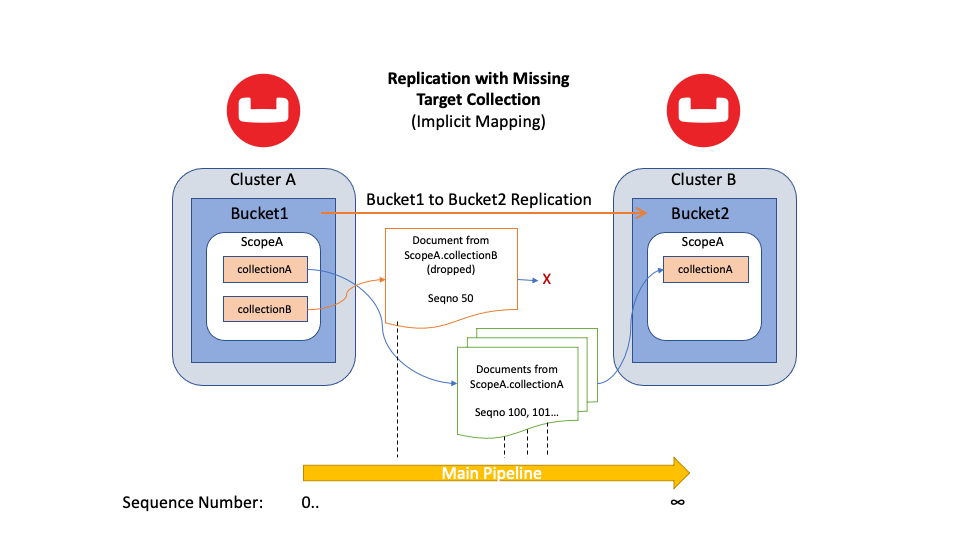
Figura 5: Replicación de todos los documentos del cubo de origen con una colección de destino que falta
Durante la replicación, XDCR busca continuamente colecciones de destino nuevas o eliminadas. Cuando XDCR detecta una nueva colección de destino, comprueba si se puede establecer una nueva asignación. Si es posible establecer una nueva correspondencia, el canal principal replica correctamente los datos en el espacio de nombres de destino.
Es importante entender que un flujo de replicación es secuencial. Si XDCR omitió previamente un documento, un flujo de secuencia no puede "rebobinar" a un punto anterior para el documento omitido. XDCR necesita replicar cualquier mutación omitida; de lo contrario, faltarán datos.
Una nota al margen: Esta incapacidad de rebobinar (sin Collections) es exactamente la razón por la que hay una opción llamada "Guardar y Reiniciar Replicación" cuando se edita la Expresión de Filtrado Avanzado en Couchbase Server 6.5. Cuando usas "Save and Restart Replication", el pipeline empieza de nuevo y hace el stream desde la secuencia 0 para asegurar que todos los documentos son replicados. Esta solución no funcionará para Colecciones.
Tubería de relleno
En Couchbase Server 7.0, XDCR ahora incluye el concepto de backfill pipeline.
El objetivo de la canalización de relleno es transmitir los datos que la canalización principal dejó caer anteriormente. Este enfoque garantiza que se repliquen todos los datos de un espacio de nombres.
Cuando se detecta una nueva colección de destino, XDCR crea automáticamente un canal de relleno y transmite los datos que faltan. Mientras tanto, el canal principal sigue siendo responsable de transmitir las mutaciones en curso a la nueva colección de destino.
Las canalizaciones de relleno se inician siempre en modo de baja prioridad para minimizar el impacto en el rendimiento de las canalizaciones principales. Una vez que el canal de relleno ha terminado de transmitir los datos que faltan -basándose en un número de secuencia final definido-, el canal de relleno se cierra automáticamente.
Todo el proceso de construcción y desmantelamiento de la replicación de backfill está completamente automatizado, por lo que ocurre entre bastidores sin alertar a los usuarios. Sin embargo, es importante que entienda la arquitectura, ya que sus usuarios podrían notar que algunos documentos creados más tarde en el tiempo en los Buckets de origen llegan antes que las mutaciones anteriores.
La figura 6 ilustra el funcionamiento del canal de replicación de backfill.
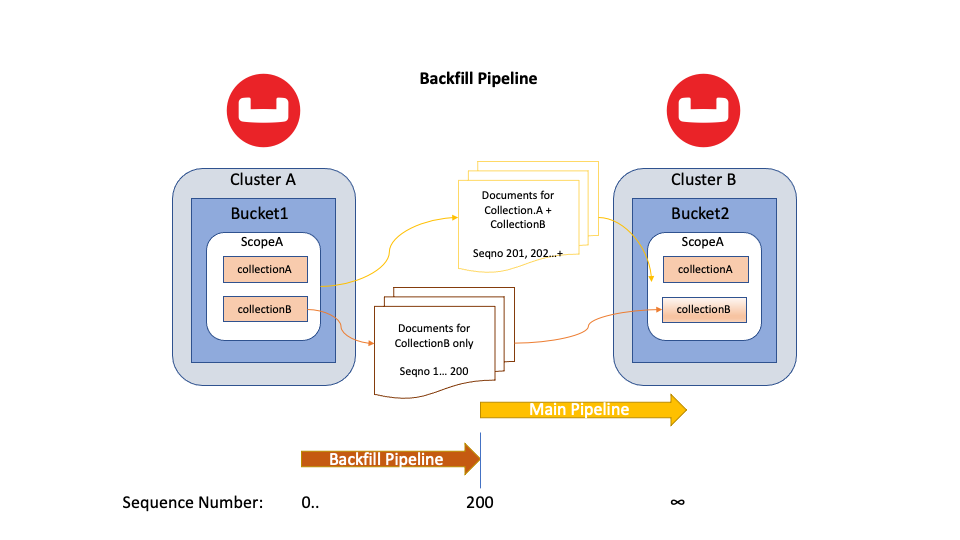
Figura 6: Datos de flujo de Backfill Pipeline para colecciónB sólo para los números de secuencia omitidos previamente
En el diagrama anterior, un nuevo colecciónB en el cubo de destino. XDCR en el clúster A detectó la nueva colección cuando su canalización principal estaba emitiendo mutaciones en el número de secuencia 200. A continuación, creó una canalización de relleno que se encarga de procesar las mutaciones. A continuación, creó una canalización de relleno, que es responsable de colecciónB mutaciones del número de secuencia 0 al 200. Todas las colecciónB mutaciones (201+) pasarán por la tubería principal.
En resumen, el canal principal permite a XDCR seguir replicando las últimas mutaciones de forma continua; el canal de relleno permite que un flujo de replicación de menor prioridad replique cualquier dato omitido previamente.
Conclusión
En resumen, la replicación de colecciones XDCR supervisa de forma inteligente los cambios en la gestión de colecciones tanto de origen como de destino. Puede replicar tanto dinámicamente (vía mapeo implícito) como programáticamente (vía mapeo explícito). XDCR Collections le permite cambiar dinámicamente los modos entre mapeo implícito y explícito, así como modificar las reglas de mapeo explícito sobre la marcha sin necesidad de reiniciar la replicación desde la secuencia 0.
Scopes y Collections en Couchbase Server 7.0 abren todo un nuevo mundo de casos de uso para los usuarios y clientes de Couchbase. Con el soporte de XDCR de Scopes y Collections - y la flexibilidad que proporciona - Couchbase Server responde a más necesidades de los clientes que cualquier versión anterior.