Google Cloud Platform (GCP) iba notablemente por detrás de AWS y Azure en la salida al mercado de una plataforma de computación en nube. A pesar de ello, los porcentajes de crecimiento de GCP han sido mayores que los de AWS, ya que las empresas están empezando a considerar algunas de las ventajas que ofrece GCP sobre AWS y Azure. Por ejemplo, sólo GCP permite ejecutar recursos en diferentes regiones del mundo en la misma red privada por defecto. Esto significa no tener que enlazar regiones a través de VPN y que su tráfico global nunca toque la Internet pública.
Estamos viendo más prospectos y clientes de Couchbase explorando y usando GCP. Tenemos una gran documentación de Couchbase sobre cómo empezar con Couchbase en GCP para ayudarte:
- Ofertas de Couchbase en GCP Marketplace
- Despliegue de Couchbase Server utilizando GCP Marketplace
- Prácticas recomendadas para ejecutar Couchbase en Google Compute Engine
Mejores prácticas de alta disponibilidad
Mientras que las referencias anteriores te ayudarán a poner un clúster en marcha, pensé que sería útil cubrir algunos conceptos básicos sobre el empleo de algunas de las mejores prácticas de alta disponibilidad para tu clúster Couchbase en GCP aprovechando nuestra función Server Group Awareness y las capacidades de Cross Data Center (XDCR) que están disponibles fuera de la caja con cada instalación de Couchbase Server.
Conocimiento del grupo de servidores proporciona una mayor disponibilidad al proporcionar redundancia de servicios Couchbase para asegurar que tienes nodos para un servicio específico repartidos en grupos de servidores. Específicamente, esto protege un cluster de fallos de infraestructura a gran escala, a través de la definición de grupos. Más información aquí.
XDCR replica datos entre un bucket de origen y un bucket de destino. Los buckets pueden estar ubicados en clusters diferentes y en centros de datos distintos; esto protege contra fallos del centro de datos y también proporciona un acceso a los datos de alto rendimiento para aplicaciones de misión crítica distribuidas globalmente. Más información sobre XDCR aquí.
Pasos para implantar la alta disponibilidad
En esta Parte 1 de un blog de dos partes, cubriremos la implementación de Server Group Awareness en un clúster GCE que se crea a través de GCP Marketplace. La Parte 2 cubrirá el Despliegue de Couchbase para Alta Disponibilidad en Google Cloud Platform GCE- XDCR para HA Activa/Pasiva.
Estas son las etapas principales, que se detallan a continuación:
- Despliegue un cluster de siete nodos alterando la plantilla por defecto para una opción BYOL de Couchbase Server cubierta en "Despliegue de Couchbase Server utilizando GCP Marketplace"
- Captura de las zonas asignadas a cada uno de los siete nodos
- Cree una matriz para asegurarse de que los nodos de cada servicio se reparten entre las zonas de GCP disponibles para su clúster regional.
- Quitar y volver a añadir cada uno de los nodos para que sólo un servicio Couchbase se ejecute en cada nodo, ya que la plantilla pone todos nuestros servicios en cada nodo según la matriz creada en el paso anterior.
- Crear grupos de servidores en la interfaz de administración de Couchbase Server que correspondan a cada una de las zonas GCP y asignar el grupo a cada nodo según nuestra matriz en el paso 3.
Primer paso
Siga las instrucciones de Despliegue de Couchbase Server utilizando GCP Marketplacepero en el lugar que se muestra en la captura de pantalla siguiente, cambiará "Recuento de nodos del servidor Couchbase" de "3" a "7" y el Couchbase Sync Gateway Número de nodos de "2" a "0".
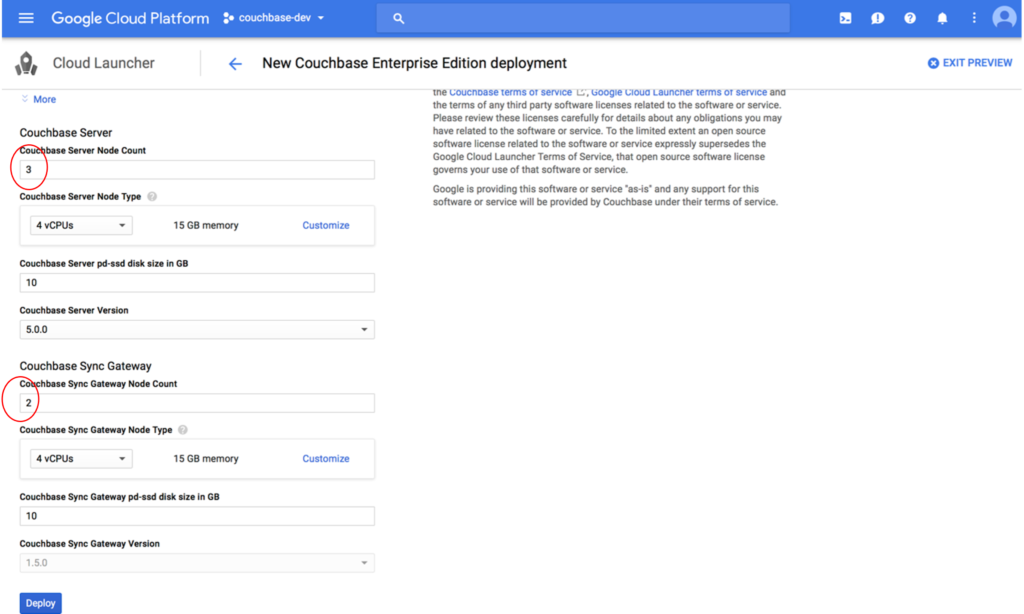
Aunque estamos haciendo cambios a la plantilla de lanzamiento por defecto, su uso ahorrará mucho tiempo en la puesta en marcha de un motor Couchbase GCE. Para casos de uso específicos con requisitos de carga de trabajo, lo mejor es trabajar con un ingeniero de soluciones de Couchbase para asegurarse de que su clúster Couchbase tiene el tamaño adecuado para sus requisitos y SLA.
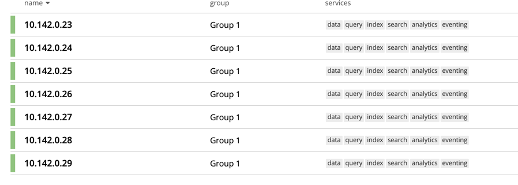
Después de lanzar un cluster con la plantilla GCP Couchbase marketplace, observa que todos los nodos están en un Server Group y todos están ejecutando los seis servicios de Couchbase como se muestra en el ejemplo de abajo. Para este ejercicio reconfiguraremos los nodos para que cada uno ejecute únicamente los servicios Data, Query o Index.
Paso 2
Antes de empezar a eliminar y volver a añadir nodos con un servicio asignado, tenemos que identificar a qué zonas CME se asignó cada uno de los nodos en el lanzamiento. Puede hacerlo en la consola de GCP, en la sección "Instancias VM"como se muestra a continuación:
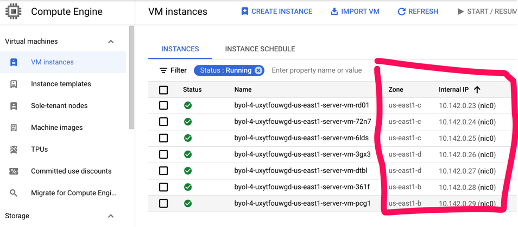
Paso 3
A continuación, planificaremos la asignación de cada nodo a un servicio específico, tal y como se muestra en la siguiente tabla:
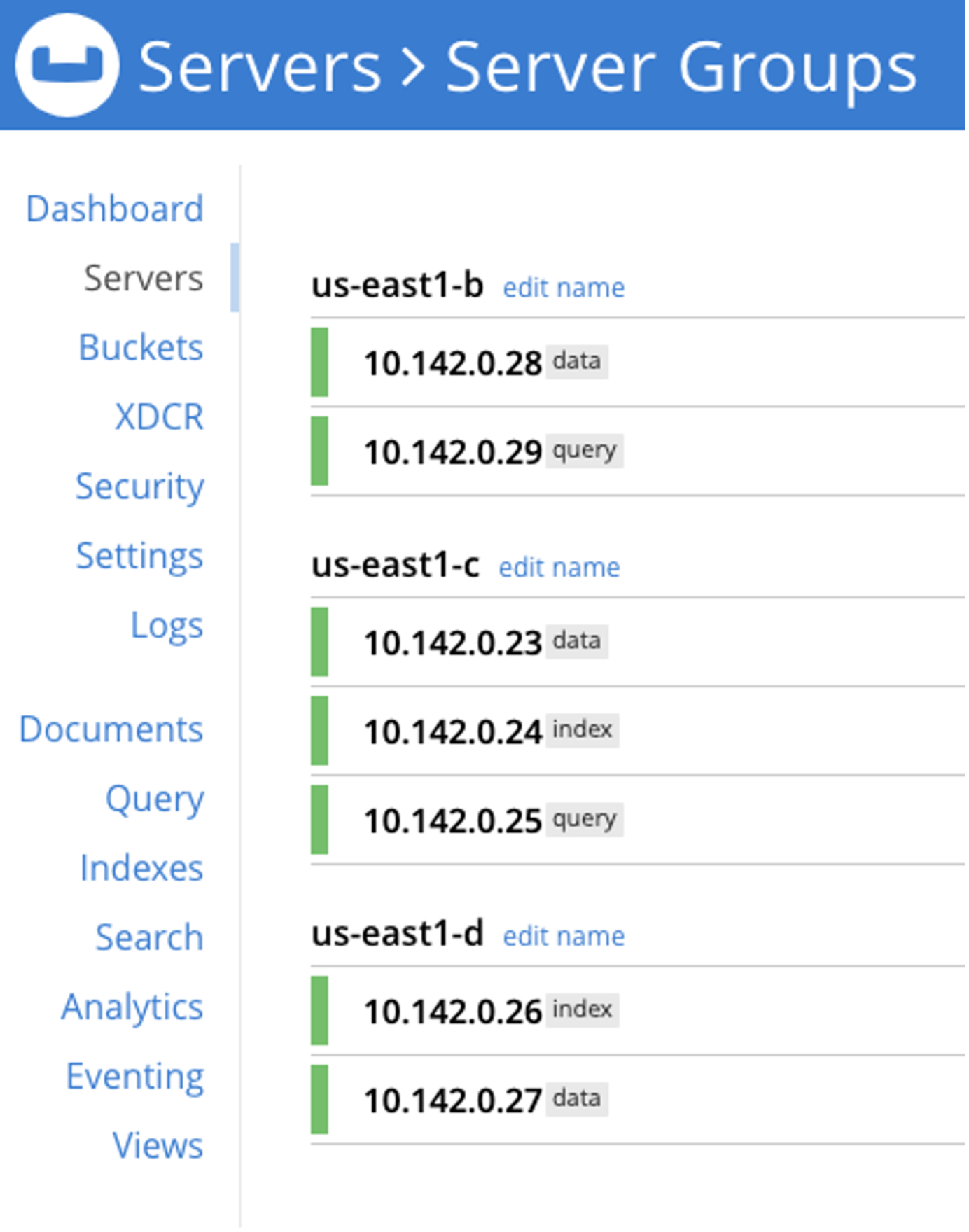
| Dirección IP | Zona | Servicio |
| 10.142.0.23 | us-east-c | Datos |
| 10.142.0.24 | us-east-c | Índice |
| 10.142.0.25 | us-east-c | Consulta |
| 10.142.0.26 | us-east-d | Índice |
| 10.142.0.27 | us-east-d | Datos |
| 10.142.0.28 | us-east-b | Datos |
| 10.142.0.29 | us-east-b | Consulta |
Paso 4
Las instrucciones para eliminar un nodo de un clúster son las siguientes aquí. Para volver a añadir el nodo a un clúster en ejecución, haga clic en aquí. Después de quitar y volver a añadir nodos con un servicio por nodo, debería tener este aspecto en el "Servidores" Vista de la IU:
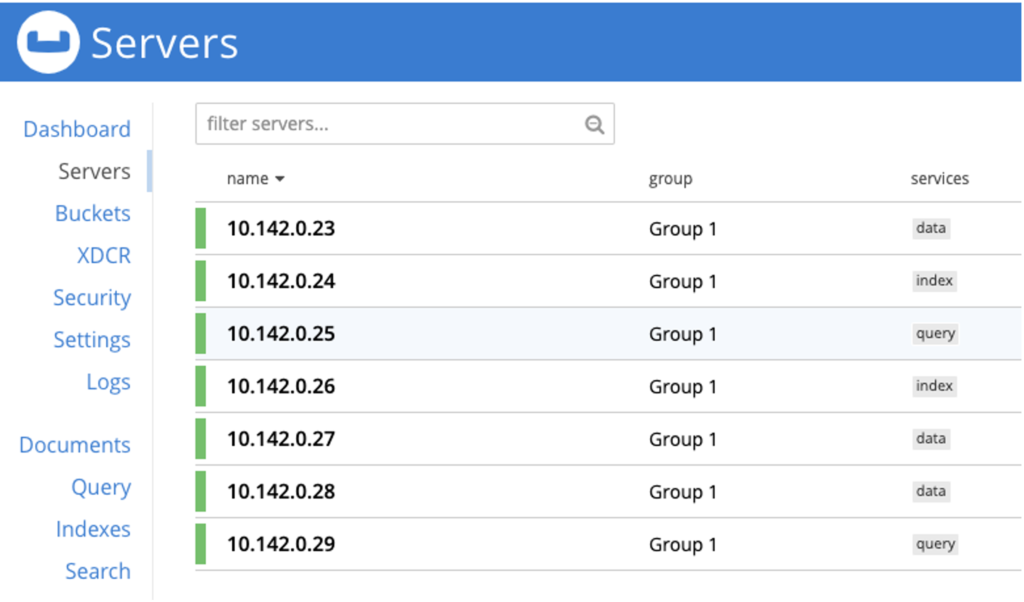
Observa que todos los nodos están en el grupo "Grupo 1" por defecto.
Paso 5
Ahora asignaremos los nodos del clúster Couchbase a los grupos que corresponden a las zonas GCP.
En la pantalla Servicios, pulse "GRUPOS“

A continuación, haga clic en "AÑADIR GRUPO". Añade un "us-east1-b" y un "us-east1-c".

Divide los nodos de cada servicio en grupos iguales según la matriz que creamos en el paso 3. Index y Query sólo estarán en dos grupos haciendo clic en "Mover a" en el extremo derecho de cada nodo y eligiendo el grupo. Después de elegir el nuevo grupo de destino para cada uno de los nodos que queremos mover, haga clic en "Aplicar cambios". A continuación, puede cambiar el nombre del Grupo 1 a "us-east1-d".
Tras la reasignación de grupos, tenemos tres grupos, como se muestra a continuación, que corresponden a la ubicación de la zona GCP de los nodos:
Conclusión
Ya has implementado completamente Server Group Awareness para tu clúster de Couchbase en GCE y has aprovechado las capacidades de Multi-Dimensional Scaling de Couchbase separando servicios entre nodos y asignándolos a zonas de disponibilidad de GCP separadas, haciendo que tu clúster sea tolerante a fallos a nivel de nodo y servicio. Esto, junto con la implementación de réplicas para sus datos, índices secundarios globales y FTS le permitirá tener una redundancia de servicio completa en caso de que una zona de disponibilidad de GCP tenga una interrupción.
En la Parte 2 de este blog cubriremos cómo proteger tu cluster de Couchbase Server de un fallo en la región de la nube o en el centro de datos. También puedes echar un vistazo a las siguientes sesiones de nuestra conferencia de usuarios Connect, Preparación para la replicación: lo que se debe y no se debe hacer con XDCR.
Sigue leyendo estos recursos para empezar con Couchbase en GCP:
- Ofertas de Couchbase en GCP Marketplace
- Despliegue de Couchbase Server utilizando GCP Marketplace
- Prácticas recomendadas para ejecutar Couchbase en Google Compute Engine
