Recap
In the previous two installments of this series, we discussed the drivers behind creating microservices. We also looked at why Couchbase is the perfect datastore to use with such an architecture. We also looked at three variants of a sample user profile microservice. Two were written in Python, and one was written in Node.js for comparison. In this last part of the series, we will discuss one method for generating test data for the microservice schema.
Why use test data?
Rigorous testing is critical to releasing stable software. Many elements go into a good test strategy. In the past decade, the term “DevOps” is often used to reference both the toolsets used in software development and testing and the culture and processes and procedures that must be in place to achieve rapid, agile development. Regardless of the terminology, there is one common thread – automation and orchestration. These two things can easily be their own blog series, so we won’t dwell too much on them except to say that test data generation is an essential aspect of DevOps and agile software development and testing.
I personally have fallen into the trap of not having a good development data set. For expedience, I manually created some data to fit the desired schema so that I could do unit tests on code. But the next day, I realized that the code that worked fine with my small data set didn’t work too well when it was run against a test database with thousands of records and more realistic data.
Generating JSON data to test the Python microservice
There are many ways to get test data into a test or development database. One method is to copy and sanitize production data if possible. It may not be feasible to have full production copies for multiple development and test environments depending on available resources. Database platforms must be sized appropriately, and care must be taken to remove sensitive data for compliance and security reasons. Complete production copies should be a requirement for regression and pre-prod test environments. Generating synthetic and randomized data with a minimal dataset for unit testing and development is usually suitable.
With a relational database, it can be challenging to create a database instance with a subset of tables because relational models typically require all the data structures to be present. However, with Couchbase’s JSON document format, it is much easier to do. Looking at the microservice sample, the schema was built around Couchbase’s Scopes and Collections. These could easily be part of a larger schema with more collections and scopes. But all we need are the collections to access keys, user profiles, and the user images, as that is all our service example needs to access to function.
In the second part of the blog series, we used JMeter to do performance testing. To accomplish performance testing, the database should have at least thousands of records to give JMeter a reasonable dataset for test generation. The microservice simply gets profile elements and returns them via the REST API. The assumption is other application components consume the data and perform business logic using the results.
Revisiting the three profile collections, the following is an example of a document in the user_data collection. The service does not enforce whether the picture field has an ID referencing a picture record. The service just returns the profile data or picture data. The assumption is that whatever consumes it upstream will handle that logic.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": 1, "name": "Michael Jones", "nickname": "mjones", "picture": "", "user_id": "michaeljones2104", "email": "michael.jones@example.com", "email_verified": "True", "first_name": "Michael", "last_name": "Jones", "address": "0208 River Parkway", "city": "Strongdol", "state": "IL", "zip_code": "29954", "phone": "363-555-9036", "date_of_birth": "10/27/1958" } |
The user_images collection is straightforward with a record ID (that can be referenced by a user profile), an image type field so multiple image codecs can be supported and the Base64 encoded image itself. As noted in the first post in the series, Couchbase supports binary documents, but we used JSON for its portability and extensibility in the sample application. This comes at the expense of some extra network bandwidth to get the data and processor cycles to do the decoding.
|
1 2 3 4 5 |
{ "record_id": 1, "type": "jpeg", "image": "AAAAD…" } |
The basic service_auth collection contains the auth token but can be easily extended to include other authentication fields.
|
1 2 3 4 |
{ "record_id": 1, "token": "6j6nW3KD0ZXodBv1" } |
Generating randomized sample JSON data
I wrote a utility called cb_perf to generate randomized data and insert it into Couchbase. The utility also does some performance tests to gauge the Python capabilities on a platform. Tools like YCSB use an unrealistic schema as the only goal is to gauge raw performance. I wanted the ability to take arbitrary JSON and insert it with randomized synthetic data.
To test the sample microservice, I added the schema to cb_perf so that I could generate test data sets in any Couchbase cluster. The cb_perf utility uses a JSON schema definition file. For each collection, you define the JSON data structure.
You can specify Jinja2 expressions with variables that map to randomizer data types for each JSON value. That way, each record will be different. You can also define which indexes to create. In this case, we create a primary index and secondary indexes on a few fields.
It specifies that record_id is an ID field and that the overall record count requested should not be overwritten (so we can create as many records as we want).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "name": "user_data", "schema": { "record_id": "record_id", "name": "{{ rand_first }} {{ rand_last }}", "nickname": "{{ rand_nickname }}", "picture": "", "user_id": "{{ rand_username }}", "email": "{{ rand_email }}", "email_verified": "{{ rand_bool }}", "first_name": "{{ rand_first }}", "last_name": "{{ rand_last }}", "address": "{{ rand_address }}", "city": "{{ rand_city }}", "state": "{{ rand_state }}", "zip_code": "{{ rand_zip_code }}", "phone": "{{ rand_phone }}", "date_of_birth": "{{ rand_dob_1 }}" }, "idkey": "record_id", "primary_index": true, "override_count": false, "indexes": [ "record_id", "nickname", "user_id" ] }, |
We leverage the cb_perf randomizer option for the images collection to create a random JPEG image (it creates a random map of RGB values to make an image of random colors). We define the following:
-
- Set record_id to be the image ID.
- Create a primary and secondary index on the ID field.
- Use an equal amount of images as the requested record count.
- Override the utility’s default batch size for asynchronous operations (the default is 100) to set it to 10 as these documents are large (approximately 70KiB per document). We don’t want to create a bottleneck if we load data across a wide area network or the Internet. The default can be used on a private, high-throughput network, such as a cloud VPC or an enterprise data center.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "name": "user_images", "schema": { "record_id": "record_id", "type": "jpeg", "image": "{{ rand_image }}" }, "idkey": "record_id", "primary_index": true, "override_count": false, "batch_size": 10, "indexes": [ "record_id" ] }, |
We create only a single auth record in the service_auth collection as that is all that is needed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "name": "service_auth", "schema": { "record_id": "record_id", "token": "{{ rand_hash }}" }, "idkey": "record_id", "primary_index": true, "override_count": true, "record_count": 1, "indexes": [ "record_id" ] } |
The final piece sees us connect image records to profile records. We use the “link” rule as part of the schema definition. The schema rules are run after a data load. We are simply pulling the list of image record keys and updating the picture field in the profile documents to include a reference to the image key.
|
1 2 3 4 5 6 7 8 |
"rules": [ { "name": "rule0", "type": "link", "foreign_key": "sample_app:profiles:user_data:picture", "primary_key": "sample_app:profiles:user_images:record_id" } ] |
Loading the generated data
Cb_perf has a load mode that creates the specified number of records from the requested schema to load the data.
|
1 |
% ./cb_perf load --host db.example.com --schema profile_demo -u developer -p password --count 1000 |
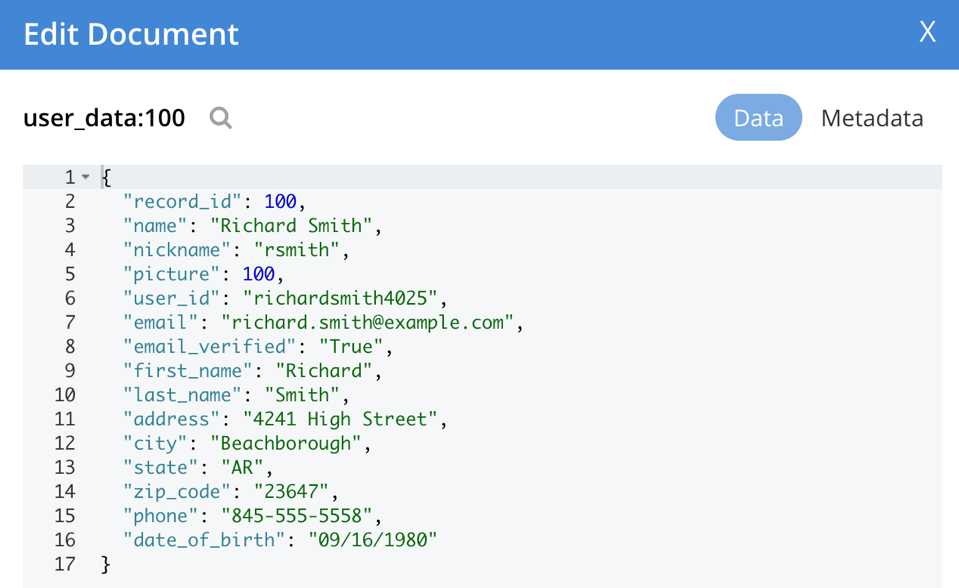
When complete, the data will be loaded and the indexes created. You are ready to run and test the microservices. The utility automatically generates document IDs (the Couchbase document ID in the document metadata, as opposed to the record ID in the document) to be the collection name, plus a colon and the record ID. Here, we can see an example of what was loaded in the Couchbase UI.
Up next
This completes the Building a Python Microservice with Couchbase series. However, look for future updates on new features being added to cb_perf and other topics. Thank you for reading this series. I hope you found it informative.
Python resources and blog series links
-
- Download the cb_perf utility from my GitHub
- Read the earlier posts in this series:
- Couchbase Python SDK docs – Getting Started with the Python SDK
Random fun fact
In a universe far, far away in a different technological time, Perl was the popular interpreted language. It grew from a text-processing language (like the classic UNIX AWK) to a ubiquitous general-purpose language. Between 1996 and 2000, the Perl community decided to borrow from the long-standing Obfuscated C competition and held Obfuscated Perl competitions. Perl’s loose, free-form syntax can certainly lead to difficult-to-decipher programs, so it is only natural to have had such a competition. Every programmer at some point looks at something they wrote, perhaps fueled by caffeine and sleep deprivation, and wonders what it does.
|
1 |
python3 -c "print(bytearray([ord(b'a')+b%26 for b in [19,7,0,13,10,18]]).decode('utf-8'))" |
