Microservices require a scalable and sustainable set of components. This post introduces how to build microservices using Python and Couchbase to provide a fully-scalable solution.
Monolithic applications present many challenges. They were born in an age when everything ran on one system, usually a mainframe or minicomputer. Service-Oriented Architecture unleashed applications, allowing them to use scale-out shared-nothing collections of commodity servers. It allowed parts of an application landscape to be discretely scaled as needed. Today, we have similar patterns, except the servers have been replaced with virtual machines or cloud instances.
Some Service-Oriented Architectures are collections of small to large applications that need to interoperate. This allows for some disaggregation and horizontal scaling but does not solve all the challenges of achieving global cloud scalability because each service is often a monolithic application. Large applications are not only difficult to scale but also a challenge to develop. They require a lot of coding and maintenance. Simple code updates can require complete regression testing, which needs considerable effort.
Enter the Microservices Architecture. This architectural pattern splits each application component into small pieces that can be independently scaled. They are usually stateless so that they can be spun up and shut down as needed. The main challenge becomes network latency, but this usually isn’t a problem since high-speed networks are ubiquitous today.
Microservice design
A good microservice should be lightweight and stateless. The goal of a Microservices Architecture is to break application functionality into discrete, independently operating components. Each microservice should serve one functional area of the overall application. What is most important is that each microservice should be able to evolve independently from the rest of the application landscape. This works well with an Agile development methodology, enabling teams to rapidly deliver new functionality without impacting the overall application.
It has been said that microservices should be designed for failure. This might sound odd at first, but it makes perfect sense if you consider the nature and lifecycle of a microservice. A good microservice should be ephemeral. Since they are stateless, you should be able to add and remove microservice instances without impacting the application.
Since the microservices will be in perpetual flux, all interaction with them should be via an API style that works well in this environment. As such, RESTful interfaces are a good choice for the API design. REST calls are ephemeral, and they function well behind a network load-balancer (which is one method to make REST-based microservices highly available and scalable).
Finally, they should be easy to deploy and automate with popular DevOps tools. Each service should be able to run either on a system with other services or in a container. Kubernetes, a container orchestration technology, was essentially created for microservices.
Building a user profile microservice
It is difficult to make an entire application out of microservices. Core business logic often needs to be provided by some application that just can’t be rewritten with microservices. For example, you may need to interact with an off-the-shelf ERP or CRM application stack. But for Web and Mobile applications, it is a common pattern to front-end such large systems with microservices to control the end-user experience.
Technology consumers want a fast and personalized experience when they interact with a web or mobile application. With microservices, you can globally distribute the most frequently used elements of the presentation layer to be geographically close to the end-user. You can also independently scale these components based on usage patterns.
One frequent component of a web or mobile application is the concept of user profiles. This is usually the “silhouette of a person” icon in the upper righthand portion of a user interface. User profiles can be either simplistic with basic demographic information or highly detailed with rich information about preferences and history to drive personalized changes to a user’s experience.
This series of blog posts discusses using Python to provide a RESTful interface to user profile data hosted in a Couchbase database. We will use a simple example with a basic schema for illustrative purposes. However, you can enhance this example as much as needed for a “real world” application.
Why use Couchbase for microservices?
Couchbase combines multiple data processing elements into a unified data platform. Couchbase includes a key-value engine, support for relational schemas, a full SQL query engine, a complete text search engine, an eventing engine and an analytics engine. It provides microsecond response times and eliminates the need for organizations to choose different systems for different workloads.
A user profile service is typically a frequently accessed service. At a minimum, along with authorization and authentication, it is accessed every time a user logs into an application. However, the more likely scenario is it will need to be accessed many times while someone interacts with an application. As such, performance and latency will be essential characteristics of the design.
The memory-first architecture of Couchbase allows it to deliver blazingly fast performance. Couchbase performance is near-linear with its scale-out, shared-nothing architecture that enables it to maintain throughput and latencies as the cluster is scaled. Couchbase can scale in conjunction with the microservice elements because the microservice architecture is also scale-out, shared-nothing.
Couchbase is designed to eliminate many traditional administrative tasks. Couchbase leverages a dynamic data containment model with auto-sharding and rebalancing of data, and by separating index management from data management. With the Capella Couchbase Cloud offering, or on-prem with tools such as Terraform or Kubernetes and the Couchbase Autonomous Operator, database changes and microservice changes can be automated and orchestrated across private and public clouds.
Why Python?
This may be the biggest question on your mind as you read this post. Something like Node.js might be the first language that comes to mind. Indeed, per Berkeley JavaScript is the most in-demand language, however, Python is the second. Python is very accessible as it is part of the software distribution for Linux and macOS and you can easily install it on Windows. You can have multiple versions of the language installed, and the virtual environment feature makes it easy to have multiple customized environments using different versions of the language. While Python supports multithreading, its threads are not as performant as a language such as Java. Still, Python is lightweight, so it scales nicely with multiprocessing and has packages that make dispatching threads or processes easy. The best part of Python is it is easy to learn and easy to code.
Sample application walkthrough
To demonstrate the concept, I created a sample Python Microservice (code is on GitHub) that provides a very simple RESTful interface to access user profile information. Couchbase supports JSON, UTF-8 (string), or binary (raw) document types. The JSON format is considered the native format and enables many rich features in the platform, so that is the document format that we will use.
Our very simple user profile contains the user’s name and other basic details regarding their account. The profile includes a picture that references a separate record containing the Base64 encoded image file. We could have used the RAW document type, but we put the image into a JSON value for this example.
We also leverage the scopes and collections feature that was introduced with Couchbase Server 7. User profile documents are stored in the user_data collection, and images are stored in the user_images collection as illustrated here:
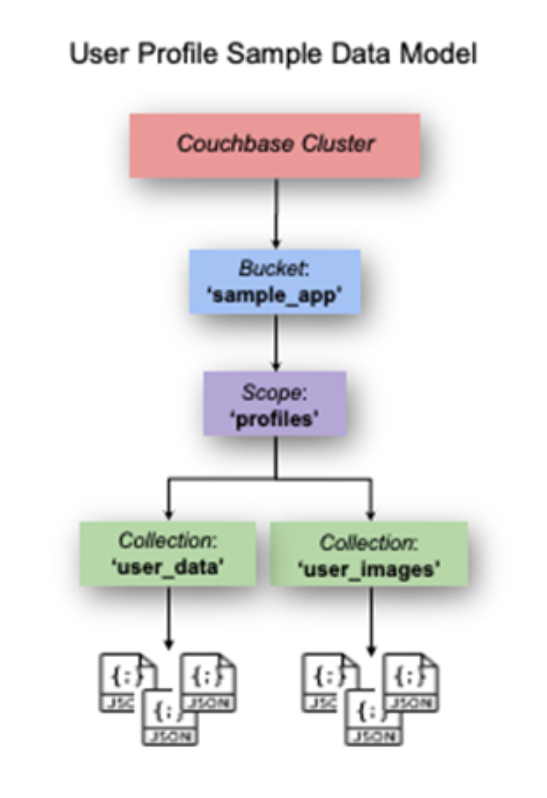
User profile document format:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": "1", "name": "Jessica Lopez", "nickname": "jlopez", "picture": "1", "user_id": "jessicalopez9483", "email": "jessica.lopez@example.com", "email_verified": "False", "first_name": "Jessica", "last_name": "Lopez", "address": "6699 West Road", "city": "Weirton", "state": "OR", "zip_code": "21243", "phone": "306-402-6984", "date_of_birth": "03/05/1961" } |
User picture document format:
|
1 2 3 4 5 |
{ "record_id": "1", "type": "jpeg", "image": " AAAADGpQICANC…=" } |
The Python microservice has the option of running either in the foreground where output is echoed to the screen (terminal), or the background as a “daemon” where output is sent to a log file. The code uses the Python object-oriented class feature to do most of the work.
The dbConnection class is designed to hold pointers to objects related to the Couchbase database connection. This just makes it easy to pass these around to other classes and functions.
The couchbaseDriver class handles the interaction with the database. The connect function initiates a connection to the Couchbase cluster. It creates objects for accessing the bucket, scope, and collections passed to the function. It stores those objects into a dbConnection object which is stored in the class. The get function does a key-value retrieval of the key passed to the function from the referenced collection leveraging the established connection. The query function does a SQL SELECT on the JSON field from the referenced collection searching for a JSON key that is equal to the specified value.
The restServer class is a handler class designed to be passed to the Python http.server module. It implements the RESTful interface. There are GET endpoints to find user profile data based on the nickname, username, or ID. It also has endpoints to get profile pictures, either by retrieving the JSON document or by returning the image itself. This has an advantage over other REST development frameworks that often only support responding to REST endpoints with JSON content.
Finally, the microService class starts and stops the HTTP server. It is called from main which uses the couchbaseDriver to connect to the database and start the microservice. The whole microservice is only a few hundred lines of code, and it can be easily deployed anywhere, and attached to any Couchbase cluster.
Up next
In the next part of this series, we will talk about generating random test data for the microservice schema and performance testing.
Refer to these resources as your research further on these topics:
