In the first installment of this series, we discussed the drivers behind creating microservices, and why Couchbase is the perfect datastore to use with a microservice architecture. With their stateless nature, they can be deployed anywhere and horizontally scaled as needed. While you could write a microservice in any language, to fit into an agile workflow where you need to deliver functionality fast, you should choose a language known by most developers and allow for rapid development. Since Python and JavaScript are two popular languages, either would be a good fit. In this blog series, we are focusing on Python.
Distributed performance considerations
Application performance requirements are important, but they are sometimes difficult to quantify. A simple example is a report that runs in X hours; however, it should run in Y minutes due to business requirements. That example is easy to quantify and provides a clear target for improvement. When you have a geographically distributed architecture, if a component can support X requests per second, that does not mean anything. Considering the number of variables in a geographically distributed application, you need to take a step back and start with something you can quantify; for example, you want a smartphone app to fully load in X seconds, or you want a web page to fully load in Y seconds. Then work backward to see what is needed to make that happen.
Python microservice performance considerations
When you create a microservice in Python, you have some options to consider before you start coding. You can either write all your own Python code to create the service or use a Python API framework such as Flask or FastAPI. In the first installment of this series, I provided an example of the first option. I will call this the “full code” option. In this second part of the series, I will introduce an implementation of the simple User Profile service using FastAPI. I chose FastAPI over Flask for this Blog because most consider it faster, and I thought it would be fun to give it a try.
But first, let’s focus on our original “full code” example. We used Python’s HTTPServer class to create a basic Web Server to respond to our API calls. For our API, we decided to use paths (as opposed to parameters or posting a JSON body) as it is fast and easy to parse. Our simple User Profile API does not need to provide much – just a few methods to look up a user profile and get the data. I included options for lookup by ID, Nickname or Username. In real life, requirements will vary based on how the upstream application is designed.
The full code program has two logical areas – code that is executed once and the code executed for each request – namely the do_GET function. For expedience, we won’t focus on the limited execution code, but we will focus on the do_GET function and its satellite functions. With Python’s HTTPServer class, this function will be called with each request. The request path will be in the class and accessible via self.path and the headers are in self.headers. If you are just getting started with Python, self is like this in Java – it references the calling instance of the class.
The service will need to iterate on the contents of the path string so it can do the appropriate lookup and return the data. Thanks to the beauty of Couchbase’s JSON native design, we don’t have to do much, if anything, to the data before we send it. So, we will focus on how to inspect the path. Python has a lot of built-in options for string processing which enable you to write pretty code, but not necessarily the fastest code. Python is an interpreted language (it runs directly from the source) so statements make a difference.
Let’s look at two options for path string processing – the startswith and split methods.
|
1 2 3 4 5 6 7 |
% python3 -m timeit -s 'text="/api/v1/id/4"' 'text.startswith("/api/v1/id/")' 2000000 loops, best of 5: 111 nsec per loop % python3 -m timeit -s 'text="/api/v1/id/4"' 'text.split("/")[-1]' 1000000 loops, best of 5: 205 nsec per loop |
The split is more expensive, but we are going to have to do it, so it would be best to do it only once. We can then avoid calling anything else by using the array returned from the split as opposed to startswith.
|
1 2 3 |
% python3 -m timeit -s 'True if 1 == 5 else False' 50000000 loops, best of 5: 6.07 nsec per loop |
Conditional statements are fast, so while it may not look pretty, we will do a single split and then build an if…elif…else structure to iterate through the path. We will write short helper functions to do a query or key-value get and return the JSON data to the requestor with minimal processing.
Also, to make our microservice secure, we will add a Bearer Token. We would use something like OAuth with Bearer and JWT tokens in a real environment. For our example, we will greatly simplify this and add a collection to our schema with a fixed token. The service will query this token on startup and only respond to requests that provide this token as a Bearer token. Finally, if needed, we will add a health check path that responds with an HTTP 200 so we know our service is healthy.
|
1 2 3 4 5 6 7 8 9 10 |
def do_GET(self): path_vector = self.path.split('/') path_vector_length = len(path_vector) if path_vector_length == 5 and path_vector[3] == 'id': if not self.v1_check_auth_token(self.headers): self.unauthorized() return request_parameter = path_vector[4] records = self.v1_get_by_id('user_data', request_parameter) self.v1_responder(records) |
Containerizing the Python microservice
I decided to use Kubernetes to test the service, so I had to build containers with the various implementations of the API. There is a published Python container that can be used as a base. Some OS prerequisites will have to be installed before the required Python packages. The Python container is based on Debian so the prerequisite packages can be installed with APT. Then pip can be called to install the required Python packages. The service port will need to be exposed, and finally, the service can be run as it would be run from the command line. To containerize the service, it will need an additional modification to support environment variables as this is the preferred method for passing parameters into a container.
This is an example of the Dockerfile for the full code service:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
FROM python:3.9-bullseye RUN apt update RUN apt install elpa-magit -y RUN apt install git-all python3-dev python3-pip python3-setuptools cmake build-essential libssl-dev -y WORKDIR /usr/src/app ADD . /usr/src/app RUN pip install --no-cache-dir -r requirements.txt EXPOSE 8080 CMD ./micro-svc-demo.py The service can then be run passing the parameters through the environment: docker run -d --name microservice \ -p 8080:8080 \ -e COUCHBASE_HOST=$COUCHBASE_HOST \ -e COUCHBASE_USER=$COUCHBASE_USER \ -e COUCHBASE_PASSWORD=$COUCHBASE_PASS \ -e COUCHBASE_BUCKET=$COUCHBASE_BUCKET \ testsvc |
FastAPI
Some time ago, WSGI (Web Server Gateway Interface) was created for Python web frameworks. It enabled a developer to only focus on building web applications instead of all the other lower-level tasks required with a web server. That standard was extended into ASGI (Asynchronous Server Gateway Interface), which supports asynchronous Python programming and therefore is well suited for stateless applications such as REST APIs.
Uvicorn is an ASGI web server implementation for Python, and FastAPI integrates with Uvicron to create a rapid API development platform. I decided to use this to create a second API implementation to compare to the entire code version. Since it fully supports asynchronous Python, it also plays well with the Couchbase Python SDK, which fully supports asynchronous programming.
Using this framework accelerates development because much less code is needed than the full code version. Some functions to connect to Couchbase are required, but beyond that, decorated app methods are used to interact with the FastAPI instance calling minimal code segments to fetch and return data. As with the full code version, the service connects to Couchbase once and uses the resulting collection methods to get data. The on_event method is used on startup to connect to Couchbase, retrieve the auth token, and set all the needed variables.
|
1 2 3 4 5 6 7 8 9 10 |
@app.on_event("startup") async def service_init(): key_id = '1' cluster[1] = await get_cluster() collections['service_auth'] = await get_collection(cluster[1], 'service_auth') doc_id = f"service_auth:{key_id}" result = await collections['service_auth'].lookup_in(doc_id, [SD.get('token')]) auth_token[1] = result.content_as[str](0) collections['user_data'] = await get_collection(cluster[1], 'user_data') collections['user_images'] = await get_collection(cluster[1], 'user_images') |
Once the startup actions are complete, short functions for each possible request path are invoked through app method calls. The path parameter is extracted from the path and passed to the function, along with a dependency on the function to check the auth token. With this implementation, only environment variables are used to pass connection parameters.
|
1 2 3 4 5 |
@app.get("/api/v1/id/{document}", response_model=Profile) async def get_by_id(document: str, authorized: bool = Depends(verify_token)): if authorized: profile = await get_profile(collection=collections['user_data'], collection_name='user_data', document=document) return profile |
The container for this implementation can use the same base as the full code version and install the same dependencies; however, it will have a few extra Python package requirements and the service is invoked through Uvicorn.
|
1 2 3 4 5 6 7 8 9 |
FROM python:3.9-bullseye RUN apt update RUN apt install elpa-magit -y RUN apt install git-all python3-dev python3-pip python3-setuptools cmake build-essential libssl-dev -y WORKDIR /usr/src/app ADD . /usr/src/app RUN pip install --no-cache-dir -r requirements.txt EXPOSE 8080 CMD uvicorn service:app --host 0.0.0.0 --port 8080 |
Setting up Node.js to test endpoints
The blog post is about Python, but it would be helpful to have a non-Python comparison for the API so for this I decided to use Node.js; it is asynchronous and works well with APIs. The Node.js implementation uses the Express module to create a Web Server, and in a similar fashion to FastAPI it uses the app.get method for all supported paths. It calls a function to check the auth token first, and if successful it calls a function to get the requested data.
|
1 2 3 4 5 6 |
app.get('/api/v1/nickname/:nickname', checkToken, getRESTAPINickname); app.get('/api/v1/username/:username', checkToken, getRESTAPIUsername); app.get('/api/v1/id/:id', checkToken, getRESTAPIId); app.get('/api/v1/picture/record/:id', checkToken, getRESTAPIPictureId); app.get('/api/v1/picture/raw/:id', checkToken, getRESTAPIImageData); app.get('/healthz', getHealthCheckPage); |
There is a module for the Couchbase functions located in a JavaScript file, and the functions for the supported API calls are also in modules in separate JavaScript files. Like with Python, there is a Node container that is used as a base and the NPM utility maintains the dependencies and starts the service.
|
1 2 3 4 5 6 7 8 |
FROM node:16.14.2 WORKDIR /app ADD . /app RUN rm -rf /app/node_modules RUN npm install -g npm@latest RUN npm install EXPOSE 8080 CMD npm start |
Kubernetes to spinup Couchbase autonomously
As mentioned earlier, Kubernetes was chosen to test the service implementations. This enabled accelerated testing due to the ability to rapidly deploy and scale the services for different test scenarios. There are two options for using Couchbase with Kubernetes. The Couchbase Autonomous Operator can be used to deploy Couchbase into the Kubernetes environment, or the service can connect to an external cluster. The service was tested with an external cluster that was deployed in the same cloud VPC. All nodes were in the same cloud region, and both the Couchbase cluster nodes and Kubernetes nodes were deployed across availability zones to simulate what would likely be seen in a real-world deployment.
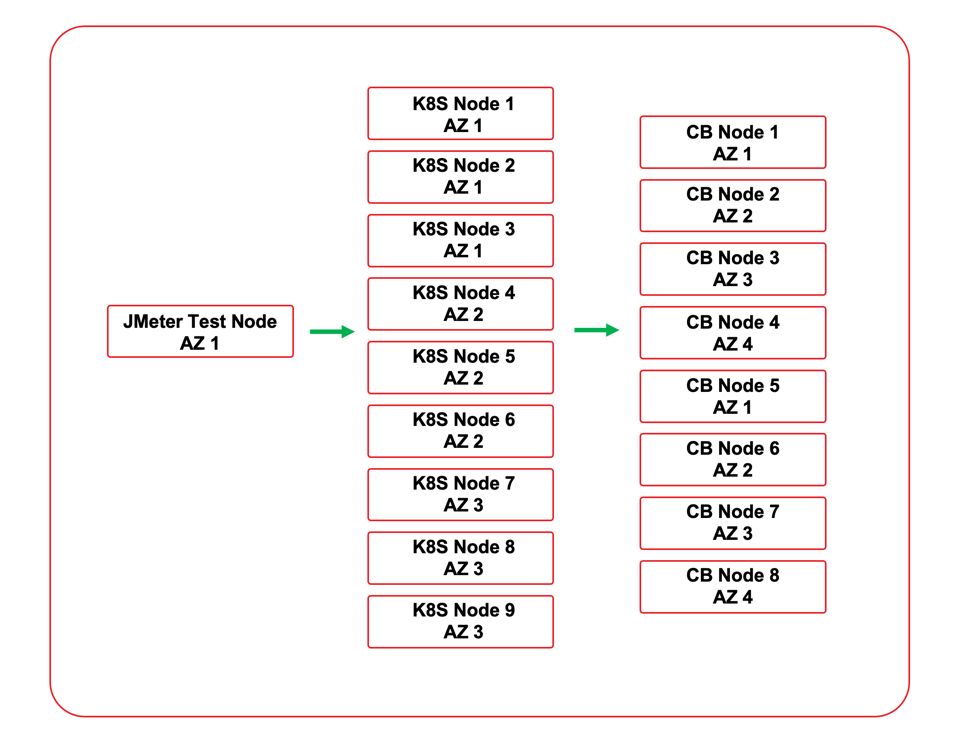
Three deployment YAML files were created to deploy the three implementations. Each deployment YAML creates a namespace for the service. It uses a secret for the Couchbase password. The service is deployed with 4 replicas initially. As it is a stateless microservice, it can scale up and down as needed. Traffic is directed to the service with a load balancer. As the Kubernetes environment used was integrated with a cloud provider, each deployment also provisioned a cloud load balancer for the service.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
apiVersion: v1 kind: Namespace metadata: name: demopy --- apiVersion: v1 kind: Secret metadata: name: demopy-secrets namespace: demopy type: Opaque data: adminPassword: aBcDeFgH= --- apiVersion: apps/v1 kind: Deployment metadata: name: demopy namespace: demopy spec: replicas: 4 selector: matchLabels: app: demopy strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 25% maxSurge: 1 template: metadata: labels: app: demopy spec: containers: - name: demopy image: mminichino/demopy:1.0.5 imagePullPolicy: Always ports: - name: app-port containerPort: 8080 env: - name: COUCHBASE_HOST value: 1.2.3.4 - name: COUCHBASE_USER value: Administrator - name: COUCHBASE_PASSWORD valueFrom: secretKeyRef: name: demopy-secrets key: adminPassword - name: COUCHBASE_BUCKET value: sample_app --- apiVersion: v1 kind: Service metadata: name: demopy-service namespace: demopy labels: app: demopy spec: selector: app: demopy ports: - name: http port: 8080 targetPort: 8080 type: LoadBalancer |
Using the deployment YAML files, the service can be deployed and scaled as needed with the Kubernetes CLI. Optionally if this was an actual production environment, tools such as autoscaling and advanced load balancing could be used to control and access the deployment.
|
1 2 |
$ kubectl apply -f demopy.yaml $ kubectl scale deployment --replicas=8 demopy -n demopy |
Cluster performance results
Before testing the services, the Couchbase cluster was tested from the Kubernetes cluster to create a baseline. YCSB workload B was used (which is primarily key-value get operations) and it yielded 156,094 ops/s. API testing was done with Apache JMeter. The ID API call was used to keep it simple, and the JMeter random number generator was leveraged to create test runs against random user profiles. The test scenario was time bound with a run time of three minutes where it would generate unrestrained load against the load balancer service requesting random user profiles with no ramp-up (the load was constant for the whole test duration).
For the first set of tests, the JMeter test parameters were unchanged, and what varied was the scale of the three API implementations. Testing started with 4 Pods for each implementation deployment and scaled up to 8 and finally 16 Pods. All the implementations scaled throughput as the Pods scaled in the deployment.
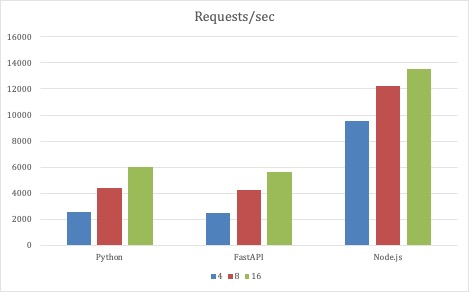
Node.js fared the best with this test strategy as it had the lowest average latency. One millisecond is not a lot of latency, nor is 12 milliseconds. But with a fixed number of generator threads creating over 1 million requests in three minutes, milliseconds have a cumulative effect. However, please bear in mind that this is an extreme test. These are just data points. What was surprising was that the full code Python service kept pace with the FastAPI implementation.
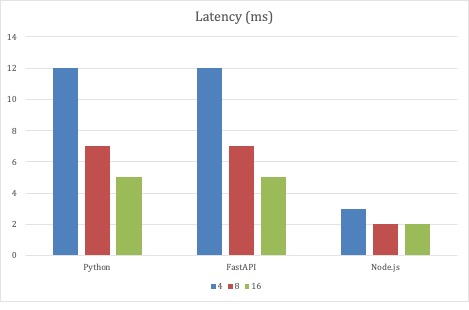
Since the first test scenario demonstrated that both the full code Python and FastAPI implementations were scalable, the second round of tests scaled the number of request threads with a fixed number of 32 service Pods. With this test scenario, the Python-based services could scale near 10,000 requests per second.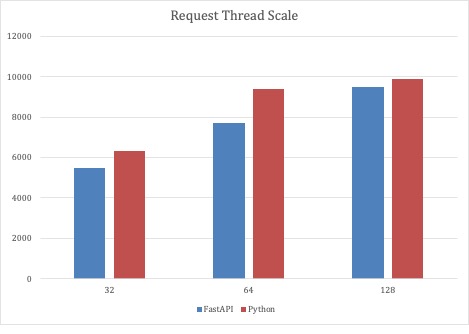
Conclusions
I think that Python is an excellent option for moderate load services. With all the testing done, the Kubernetes cluster nodes had ample available CPU and memory, so there was plenty of headroom to scale the service as needed. For implementations that require massive scale at the lowest latency, then Node.js may be a better option. Couchbase supports all the prevalent languages, so just as I was able to easily code three microservice implementations, anyone can use multiple languages and frameworks and integrate Couchbase with ease.
Up Next
In the next post in this blog series, I will talk about generating random test data for the microservice schema. Here are links to the resources mentioned in this post:
- Build A Python Microservice With Couchbase – Part 1
- Part 2 – Microservice source code for user profile
- Capella Couchbase Cloud offering
- Couchbase Autonomous Operator
Random fun fact
HTTP response codes are defined per the protocol specification. The 400 range is reserved for situations where the error seems to have been caused by the client. HTTP 418 is the “I’m a teapot” error and the spec states the “I’m a teapot client error response code indicates that the server refuses to brew coffee because it is, permanently, a teapot. A combined coffee/teapot that is temporarily out of coffee should instead return 503.”

Cool post!
I think fastapi suffers a lot from the default serializer, also pydantic while it is fairly fast it is doing validation of output data and probably taking a lot of timing there.