요약
지난 두 차례에 걸친 이 시리즈에서 마이크로서비스를 만드는 원동력에 대해 논의했습니다. 또한 Couchbase가 이러한 아키텍처에 사용하기에 완벽한 데이터 저장소인 이유도 살펴봤습니다. 또한 샘플 사용자 프로필 마이크로서비스의 세 가지 변형을 살펴봤습니다. 두 개는 Python으로 작성되었고, 하나는 비교를 위해 Node.js로 작성되었습니다. 이 시리즈의 마지막 부분에서는 마이크로서비스 스키마에 대한 테스트 데이터를 생성하는 한 가지 방법에 대해 알아보겠습니다.
테스트 데이터를 사용하는 이유는 무엇인가요?
안정적인 소프트웨어를 출시하려면 엄격한 테스트가 필수적입니다. 좋은 테스트 전략에는 많은 요소가 필요합니다. 지난 10년 동안 '데브옵스'라는 용어는 소프트웨어 개발 및 테스트에 사용되는 도구 세트와 신속하고 민첩한 개발을 달성하기 위해 갖춰야 하는 문화와 프로세스 및 절차를 모두 지칭하는 데 자주 사용되었습니다. 용어와 관계없이 자동화와 오케스트레이션이라는 한 가지 공통점이 있습니다. 이 두 가지는 별도의 블로그 시리즈가 될 수 있으므로 테스트 데이터 생성은 DevOps와 애자일 소프트웨어 개발 및 테스트의 필수 요소라는 점을 제외하고는 자세히 다루지 않겠습니다.
저는 개인적으로 좋은 개발 데이터 세트가 없다는 함정에 빠졌었습니다. 편의상 코드에 대한 단위 테스트를 할 수 있도록 원하는 스키마에 맞게 일부 데이터를 수동으로 만들었습니다. 하지만 다음 날, 작은 데이터 세트에서는 잘 작동하던 코드가 수천 개의 레코드와 보다 실제적인 데이터가 있는 테스트 데이터베이스에서 실행했을 때는 제대로 작동하지 않는다는 것을 깨달았습니다.
Python 마이크로서비스를 테스트하기 위한 JSON 데이터 생성하기
테스트 데이터를 테스트 또는 개발 데이터베이스로 가져오는 방법에는 여러 가지가 있습니다. 한 가지 방법은 가능하면 프로덕션 데이터를 복사하여 살균하는 것입니다. 사용 가능한 리소스에 따라 여러 개발 및 테스트 환경에 대한 전체 프로덕션 사본을 보유하는 것이 불가능할 수도 있습니다. 데이터베이스 플랫폼의 크기를 적절하게 조정하고 규정 준수 및 보안상의 이유로 민감한 데이터를 제거하도록 주의를 기울여야 합니다. 회귀 및 사전 프로덕션 테스트 환경에는 완전한 프로덕션 사본이 있어야 합니다. 단위 테스트 및 개발을 위해 최소한의 데이터 세트로 합성 및 무작위 데이터를 생성하는 것이 일반적으로 적합합니다.
관계형 데이터베이스에서는 일반적으로 모든 데이터 구조가 존재해야 하기 때문에 테이블의 하위 집합으로 데이터베이스 인스턴스를 만드는 것이 어려울 수 있습니다. 하지만 Couchbase의 JSON 문서 형식을 사용하면 훨씬 더 쉽게 만들 수 있습니다. 마이크로서비스 샘플을 살펴보면, 스키마는 Couchbase의 범위와 컬렉션을 중심으로 구축되었습니다. 이것들은 더 많은 컬렉션과 범위를 가진 더 큰 스키마의 일부가 될 수 있습니다. 하지만 이 서비스 예제에서는 키, 사용자 프로필 및 사용자 이미지에 액세스하는 데 필요한 컬렉션만 있으면 작동할 수 있습니다.
블로그 시리즈의 두 번째 파트에서는 JMeter를 사용하여 성능 테스트를 수행했습니다. 성능 테스트를 수행하려면 데이터베이스에 최소 수천 개의 레코드가 있어야 JMeter에 테스트 생성을 위한 합리적인 데이터 세트를 제공할 수 있습니다. 마이크로서비스는 단순히 프로필 요소를 가져와 REST API를 통해 반환합니다. 다른 애플리케이션 구성 요소가 데이터를 소비하고 결과를 사용하여 비즈니스 로직을 수행한다고 가정합니다.
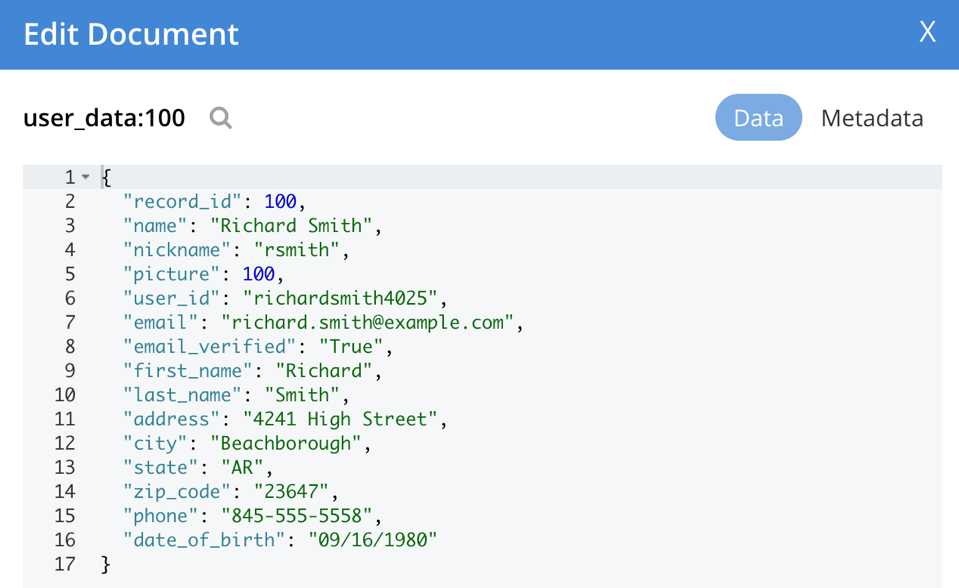
세 가지 프로필 컬렉션을 다시 살펴보자면 다음은 user_data 수집. 이 서비스는 사진 필드에 사진 레코드를 참조하는 ID가 있는지 여부를 강제하지 않습니다. 서비스는 프로필 데이터 또는 사진 데이터만 반환합니다. 업스트림에서 이를 소비하는 것이 무엇이든 해당 로직을 처리한다는 가정입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": 1, "name": "Michael Jones", "nickname": "mjones", "picture": "", "user_id": "michaeljones2104", "email": "michael.jones@example.com", "email_verified": "True", "first_name": "Michael", "last_name": "Jones", "address": "0208 River Parkway", "city": "Strongdol", "state": "IL", "zip_code": "29954", "phone": "363-555-9036", "date_of_birth": "10/27/1958" } |
user_images 컬렉션은 레코드 ID(사용자 프로필에서 참조할 수 있음), 여러 이미지 코덱을 지원할 수 있는 이미지 유형 필드, Base64로 인코딩된 이미지 자체로 간단합니다. 시리즈의 첫 번째 글에서 언급했듯이 Couchbase는 바이너리 문서를 지원하지만, 샘플 애플리케이션에서는 이식성과 확장성을 위해 JSON을 사용했습니다. 이 경우 데이터를 가져오는 데 필요한 네트워크 대역폭과 디코딩을 위한 프로세서 주기가 약간 추가됩니다.
|
1 2 3 4 5 |
{ "record_id": 1, "type": "jpeg", "image": "AAAAD…" } |
기본 서비스_인증 컬렉션에는 인증 토큰이 포함되어 있지만 다른 인증 필드를 포함하도록 쉽게 확장할 수 있습니다.
|
1 2 3 4 |
{ "record_id": 1, "token": "6j6nW3KD0ZXodBv1" } |
무작위 샘플 JSON 데이터 생성
라는 유틸리티를 작성했습니다. cb_perf 를 사용하여 무작위 데이터를 생성하고 이를 Couchbase에 삽입합니다. 이 유틸리티는 또한 플랫폼의 Python 기능을 측정하기 위해 몇 가지 성능 테스트를 수행합니다. YCSB와 같은 도구는 비현실적인 스키마를 사용하기 때문에 원시 성능을 측정하는 것이 유일한 목표입니다. 저는 임의의 JSON을 가져와서 무작위 합성 데이터와 함께 삽입할 수 있는 기능이 필요했습니다.
샘플 마이크로서비스를 테스트하기 위해 다음 스키마를 추가했습니다. cb_perf 를 사용하여 모든 Couchbase 클러스터에서 테스트 데이터 세트를 생성할 수 있었습니다. 그리고 cb_perf 유틸리티는 JSON 스키마 정의 파일을 사용합니다. 각 컬렉션에 대해 JSON 데이터 구조를 정의합니다.
각 JSON 값에 대해 랜덤라이저 데이터 유형에 매핑되는 변수를 사용하여 Jinja2 표현식을 지정할 수 있습니다. 이렇게 하면 각 레코드가 달라집니다. 생성할 인덱스를 정의할 수도 있습니다. 이 예에서는 몇 개의 필드에 기본 인덱스와 보조 인덱스를 생성합니다.
여기에는 다음을 지정합니다. RECORD_ID 는 ID 필드이며 요청된 전체 레코드 수를 덮어쓰지 않아야 합니다(원하는 만큼의 레코드를 생성할 수 있도록).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "name": "user_data", "schema": { "record_id": "record_id", "name": "{{ rand_first }} {{ rand_last }}", "nickname": "{{ rand_nickname }}", "picture": "", "user_id": "{{ rand_username }}", "email": "{{ rand_email }}", "email_verified": "{{ rand_bool }}", "first_name": "{{ rand_first }}", "last_name": "{{ rand_last }}", "address": "{{ rand_address }}", "city": "{{ rand_city }}", "state": "{{ rand_state }}", "zip_code": "{{ rand_zip_code }}", "phone": "{{ rand_phone }}", "date_of_birth": "{{ rand_dob_1 }}" }, "idkey": "record_id", "primary_index": true, "override_count": false, "indexes": [ "record_id", "nickname", "user_id" ] }, |
우리는 cb_perf 랜덤라이저 옵션을 사용하여 이미지 컬렉션에 임의의 JPEG 이미지를 생성합니다(RGB 값의 임의 맵을 생성하여 임의의 색상으로 이미지를 만듭니다). 다음과 같이 정의합니다:
-
- record_id 설정 를 이미지 ID로 설정합니다.
- ID 필드에 기본 및 보조 인덱스를 만듭니다.
- 요청된 레코드 수와 동일한 양의 이미지를 사용합니다.
- 유틸리티의 기본 배치 크기 비동기 작업의 경우(기본값은 100) 문서가 대용량(문서당 약 70KiB)이므로 10으로 설정합니다. 광역 네트워크나 인터넷을 통해 데이터를 로드하는 경우 병목 현상을 일으키고 싶지 않습니다. 기본값은 클라우드 VPC 또는 엔터프라이즈 데이터 센터와 같이 처리량이 많은 사설 네트워크에서 사용할 수 있습니다.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "name": "user_images", "schema": { "record_id": "record_id", "type": "jpeg", "image": "{{ rand_image }}" }, "idkey": "record_id", "primary_index": true, "override_count": false, "batch_size": 10, "indexes": [ "record_id" ] }, |
인증 레코드를 하나만 생성합니다. 서비스_인증 컬렉션만 있으면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "name": "service_auth", "schema": { "record_id": "record_id", "token": "{{ rand_hash }}" }, "idkey": "record_id", "primary_index": true, "override_count": true, "record_count": 1, "indexes": [ "record_id" ] } |
마지막 부분에서는 이미지 레코드를 프로필 레코드에 연결합니다. 스키마 정의의 일부로 "링크" 규칙을 사용합니다. 스키마 규칙은 데이터 로드 후에 실행됩니다. 이미지 레코드 키 목록을 가져오고 프로필 문서의 사진 필드를 업데이트하여 이미지 키에 대한 참조를 포함하기만 하면 됩니다.
|
1 2 3 4 5 6 7 8 |
"rules": [ { "name": "rule0", "type": "link", "foreign_key": "sample_app:profiles:user_data:picture", "primary_key": "sample_app:profiles:user_images:record_id" } ] |
생성된 데이터 로드
Cb_perf에는 데이터를 로드하기 위해 요청된 스키마에서 지정된 수의 레코드를 생성하는 로드 모드가 있습니다.
|
1 |
% ./cb_perf load --host db.example.com --schema profile_demo -u developer -p password --count 1000 |
완료되면 데이터가 로드되고 인덱스가 생성됩니다. 이제 마이크로서비스를 실행하고 테스트할 준비가 되었습니다. 이 유틸리티는 자동으로 문서 ID(문서의 레코드 ID가 아닌 문서 메타데이터의 Couchbase 문서 ID)와 콜론 및 레코드 ID를 컬렉션 이름으로 생성합니다. 아래에서 Couchbase UI에 로드된 예시를 볼 수 있습니다.
다음 단계
이것으로 카우치베이스로 파이썬 마이크로서비스 구축하기 시리즈가 끝났습니다. 하지만 앞으로 추가될 새로운 기능에 대한 업데이트를 기대해 주세요. cb_perf 및 기타 주제에 대해 알아보세요. 이 시리즈를 읽어주셔서 감사합니다. 유익한 시간이 되셨기를 바랍니다.
Python 리소스 및 블로그 시리즈 링크
-
- 내 GitHub에서 cb_perf 유틸리티를 다운로드하세요.
- 이 시리즈의 이전 포스팅을 읽어보세요:
- 1부 - Couchbase로 Python 마이크로서비스 구축하기
- 파트 2 그리고 파트 3 (최종)
- 카우치베이스 파이썬 SDK 문서 - 안녕하세요. Python SDK 시작하기
재미있는 사실
아주 먼 옛날, 다른 기술 시대에는 Perl이 널리 통용되던 언어였습니다. Perl은 텍스트 처리 언어(고전적인 UNIX AWK와 같은)에서 유비쿼터스 범용 언어로 성장했습니다. 1996년부터 2000년까지 Perl 커뮤니티는 오랫동안 이어져 온 난독화 C 대회를 차용하기로 결정하고 난독화 Perl 대회를 개최했습니다. Perl의 느슨하고 자유로운 형식의 구문은 해독하기 어려운 프로그램으로 이어질 수 있기 때문에 이러한 대회가 열린 것은 당연한 일입니다. 모든 프로그래머는 어느 순간 카페인과 수면 부족으로 인해 자신이 작성한 프로그램을 보고 어떤 기능을 하는지 궁금해합니다.
|
1 |
python3 -c "print(bytearray([ord(b'a')+b%26 for b in [19,7,0,13,10,18]]).decode('utf-8'))" |
