- Solutions
-
-
Adaptive Applications

Get AI-ready with hyper-personalized apps!
Next level customer experiences require adaptive applications
Learn more
-
-
- Developers
-
-
Capella Playground
-
-
- Resources
-
-
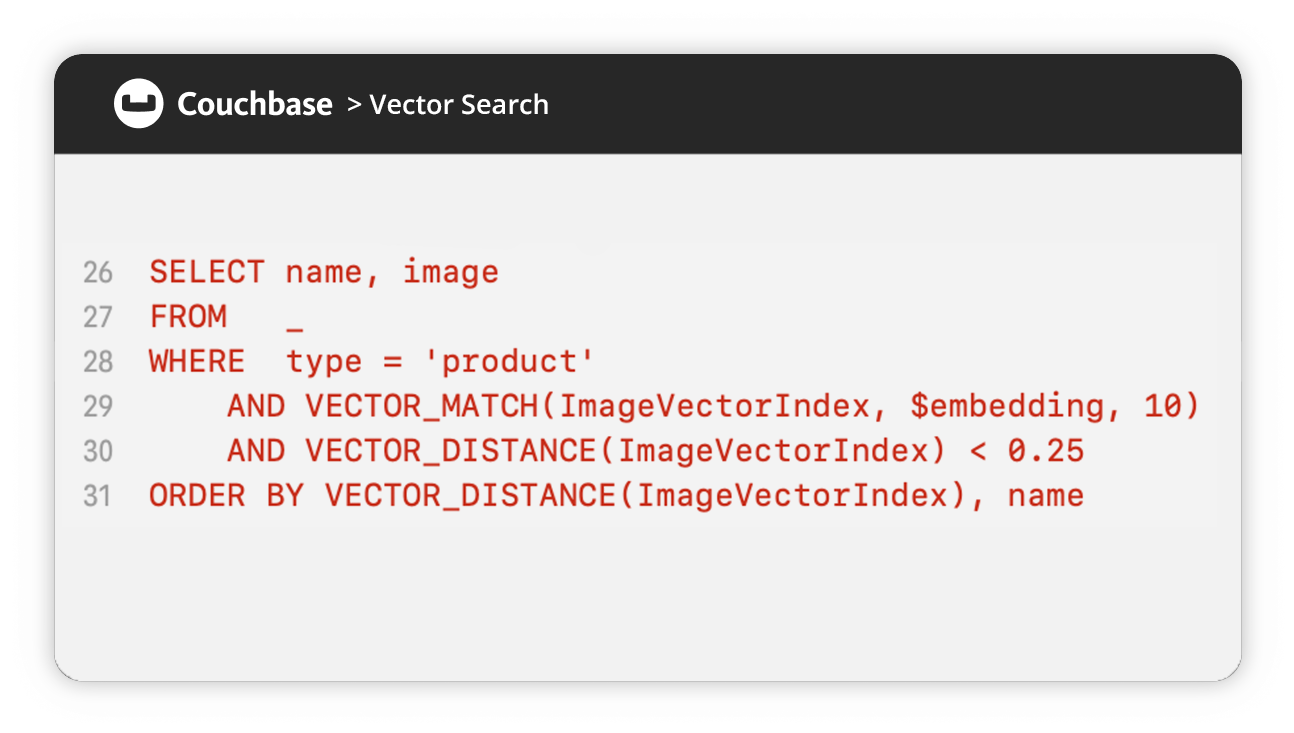
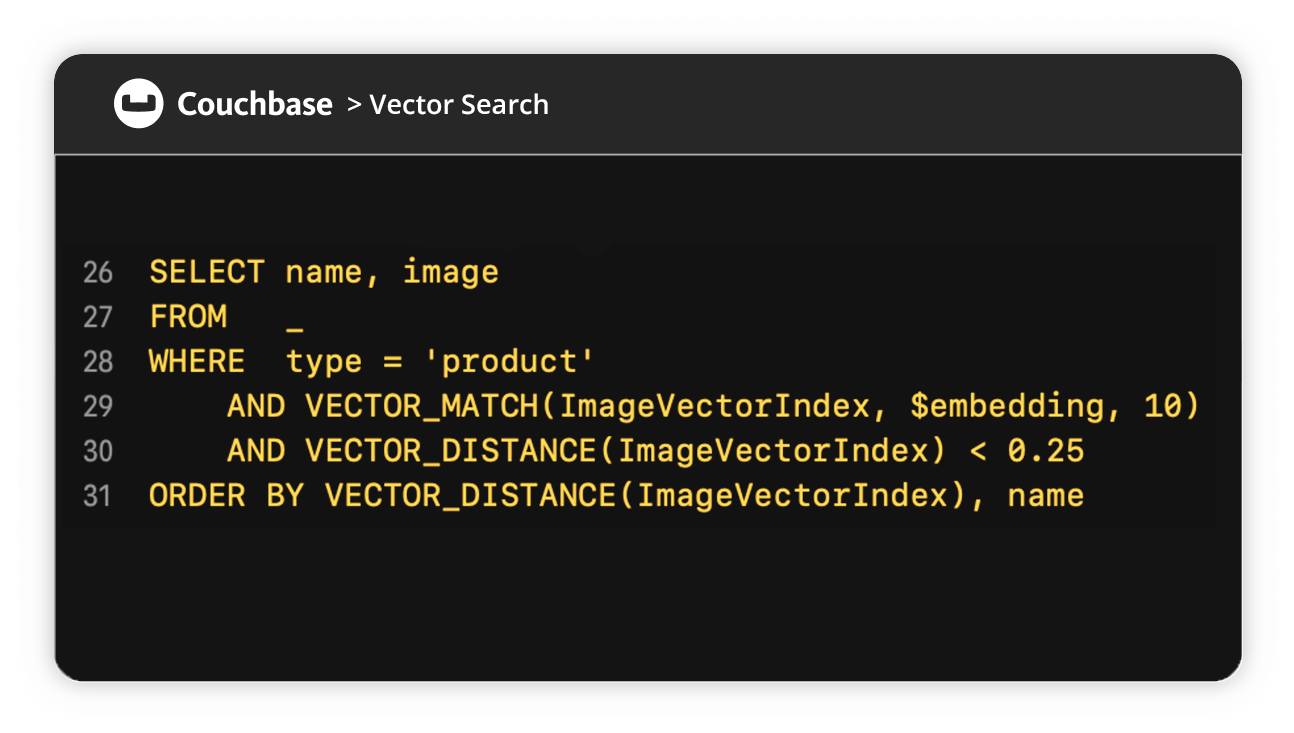
Vector Search
What's Vector Search and why is it important?
Get a quick overview of vectors, vector search, use cases, and key features.
Watch
-
-
AI-Powered Development for AI-Powered Applications
Build adaptive applications with Couchbase






































Why Couchbase?
Couchbase is an award-winning distributed NoSQL cloud database that delivers unmatched versatility, performance, scalability, and financial value for all of your cloud, mobile, AI, and edge computing applications. Couchbase embraces AI with coding assistance for developers, and vector search for their applications.
High performance to lower TCO
Couchbase offers impressive memory-first performance for your important applications. And, workloads can be performance-tuned for each application which can dramatically lower operating costs.
Read more about TCO
const bucket = cluster.bucket('travel.sample');
const collection = bucket.defaultCollection();
await collection.upsert('user_1024', {
'name' : 'Don Chamberlin',
'tags' : ['SQL', 'SQL++']
})
const result = await collection.get('user_1024');
console.log(result);
Developer-friendly
Couchbase Capella combines the schema flexibility of JSON documents with the ease of AI-assisted coding to help developers build distributed, transactional applications in their favorite languages.
Read more about Capella iQ
SELECT
a.name,
COUNT(r.airline) AS numberOfRoutes
FROM 'travel-sample'. inventory.route AS r
JOIN 'travel-sample'. inventory.route AS a ON KEYS r.airlineid
WHERE a.country = "United States"
GROUP BY a.name
ORDER BY numberOfRoutes DESC;
Versatility without complexity
Couchbase does the work of multiple databases, including key-value, JSON, SQL, text and vector search, graph, time-series, eventing, and analytics. This simplifies your data architecture without sacrificing features for your AI-powered adaptive application.
Read the AI blog
// key/value
await collection.upsert('destination:1000', { name: 'Paris' });
// full text search
const result = await cluster.searchQuery("travel-fts-index",
couchbase.SearchQuery.match('Eiffel Tower'), { limit: 10 }
);
// SQL++
const sqlQuery = 'SELECT name FROM `travel` WHERE country = "France"';
const sqlResult = await cluster.query(sqlQuery);
Distributed database architecture
User-centric, modern applications have unique requirements including the need for multiple data access patterns that reduce architectural complexity, offer mobility, and superior distributed performance across your favorite cloud.

AI-ready Couchbase Enterprise Server
Robust, high-performance, transactional NoSQL database with SQL for JSON.
Couchbase Capella with iQ
Fully managed DBaaS with AI-powered code assistance.
Couchbase Mobile with vector search
Mobile database with vector search and edge sync services.
Cloud deployment on your terms
Choose your cloud and choose who manages the database.
Development teams have special use cases to solve
Developers and architects hate complex, unscalable data architectures because they slow down applications, increase costs, and crush productivity. Couchbase helps developers address these use case issues from every angle.
Fix slow application performance
Increase application responsiveness to users and server-side systems.
Improve application flexibility
Use JSON to build your AI-powered application.
Create mobile, edge, and IoT apps
Save and modify data with or without an internet connection.
Reduce the cost of operations
Consolidate technology, optimize performance, and speed up development.
Enable distributed workloads
Global clustering to offer high availability and performance.
Boost productivity
Let developers choose from familiar and favorite tools and languages.
Integrate smoothly with our cloud partners
Easily deploy and manage your cloud strategy with the leading public cloud providers and services.










“We found that the replication technology across data centers for Couchbase was superior, especially for large workloads.”


“With less than half the servers, we can increase performance and gain a much better scalable architecture.”


“Couchbase is a highly scalable distributed data store that plays a critical role in our caching systems.”


“Enterprise-class boxes cost lots of money. We can scale and be highly available with commodity hardware.”
Start building
Check out our developer portal to explore NoSQL, browse resources, and take Couchbase for a spin in our playground.
Try Capella
Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.
Try Capella iQ
Use our generative AI-powered coding assistant to create sample data, refine it, and build queries on the datasets.