In Part 1 of this series, Monitor Stellar Assets Using Couchbase & Python, we introduced the basic concepts of the Stellar Decentralized (Blockchain) Exchange and showed how to store a copy of an account asset list in Couchbase. In this post, we load and query asset trades. We then look at these in a chart in the Couchbase web console to see trends and investments-all easily done within the Couchbase web console.
The do this we take three steps:
- Access an account’s list of trades
- Load the trades into Couchbase
- Run a query
One word of warning before we dive in – I’m not a crypto-financial guru and I will be abusing common trading lingo, with the goal of making the topic at hand as accessible as possible for readers who are new to the technology.
Understanding Stellar assets
On Stellar, the native asset is Stellar Lumens, or XLM. When talk about asset values we are going to always boil it down to an asset’s value in XLM units. For example, someone may trade a Bitcoin or Ether, with both pegged to a specific XLM value. XLM is like the USD of the trading networks you may use elsewhere.
In the previous post, we grabbed the base account data, in this one we are going to grab the trades done on that account. Previously, we created a single document in Couchbase that had all the account info, including balances as embedded objects.
With this endpoint we can get a list of all the trades for the same account. We randomly pick an account ID and use in the URL:
|
1 |
https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/trades |
This will list up to 200 entries and also has pagination URLs using a cursor variable in the results, but we are not going to use those here. Instead, we will enter in very specific parameters so we can look at particular types of trades.
Here are the salient parts of one trade returned from the above GET request:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
... "id": "171637003501543425-2", "paging_token": "171637003501543425-2", "ledger_close_time": "2022-03-10T04:38:43Z", "trade_type": "orderbook", "base_offer_id": "949268568", "base_account": "GBP4XRX3EBSZHLVKQFNZZFMQZZV2ZZ6PFV346RMUQGNTNWNNGOA5EE7U", "base_amount": "0.0578957", "base_asset_type": "native", "counter_offer_id": "4783323021928931329", "counter_account": "GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ", "counter_amount": "0.0105768", "counter_asset_type": "credit_alphanum4", "counter_asset_code": "USDC", "counter_asset_issuer": "GA5ZSEJYB37JRC5AVCIA5MOP4RHTM335X2KGX3IHOJAPP5RE34K4KZVN", "base_is_seller": true, "price": { "n": "10000000", "d": "54738433" }... |
This trade sold 0.057 of the native base asset (XLM) for 0.0105 USDC asset/digital currency.
The response has a date/time field and also entities for the issuer of each base/counter asset. This is another core Stellar concept. Each asset has a code (e.g., USDC, XLM, BTC, ETH, etc.) and an issuer of that asset (e.g., GA5ZSE…). This is designed so that, for example, anyone create new assets on the network but you can trust the issuers/providers of assets from particular addresses that you know are legitimate.
We can tweak the REST API request to include specific pairs we are interested in using parameters, for example, XLM and USDC trades only.
|
1 2 3 |
https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/trades ?base_asset_type=native&counter_asset_type=credit_alphanum4 &counter_asset_code=USDC&counter_asset_issuer=GA5ZSEJYB37JRC5AVCIA5MOP4RHTM335X2KGX3IHOJAPP5RE34K4KZVN |
While the results give us all we need to know, it can be helpful to have separate records for trades going both ways. We can run the reverse query, showing the trades of USDC to XLM:
|
1 2 3 |
https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/trades ?base_asset_type=credit_alphanum4&counter_asset_type=native &base_asset_code=USDC&base_asset_issuer=GA5ZSEJYB37JRC5AVCIA5MOP4RHTM335X2KGX3IHOJAPP5RE34K4KZVN |
Obviously, we can download way more than just a simple pair of transactions and load them into the database, but we focus on just a couple use cases to make this example simple.
Python loading Stellar trades into Couchbase
We pick up where we left off last time, but we’ll change the main URL to match the above examples. This is overly verbose and can be achieved much more efficiently with the Stellar SDK but it does add some async complexity that we will avoid for now.
The example code below connects to Couchbase, queries the Stellar Horizon service and that parses out each trade and stores it into its own document. The document keys are set to the trade ID plus a timestamp which is meaningless for us but helps us have unique document keys.
(The last function explicitly add the XLM asset code field in cases where it is missing, because when it’s a native asset type is leaves asset code blank, which makes it confusing.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import requests, time from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator usdctrades = "https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/trades?base_asset_type=credit_alphanum4&counter_asset_type=native&base_asset_code=USDC&base_asset_issuer=GA5ZSEJYB37JRC5AVCIA5MOP4RHTM335X2KGX3IHOJAPP5RE34K4KZVN" xlmtrades = "https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/trades?base_asset_type=native&counter_asset_type=credit_alphanum4&counter_asset_code=USDC&counter_asset_issuer=GA5ZSEJYB37JRC5AVCIA5MOP4RHTM335X2KGX3IHOJAPP5RE34K4KZVN" def connect(): cluster = Cluster('couchbase://localhost', ClusterOptions(PasswordAuthenticator('Administrator', 'Administrator'))) return cluster.bucket('stellar') def gettrades(tradesurl): print("Fetching: " + tradesurl) response = requests.request("GET", tradesurl) return response.json() def upsert_document(connection, doc, key): try: result = connection.upsert(key, doc) print(result) except Exception as e: print("Error",e) def process_trades(trades): now = str(time.time()) for trade in trades: trade['type'] = 'trade' key = trade['id']+now if trade['base_asset_type'] == 'native': trade['base_asset_code'] = 'XLM' elif trade['counter_asset_type'] == 'native': trade['counter_asset_code'] = 'XLM' upsert_document(cb, trade, key) cb = connect() trades = gettrades(usdctrades)['_embedded']['records'] process_trades(trades) trades = gettrades(xlmtrades)['_embedded']['records'] process_trades(trades) |
The resulting set of documents are processed for the trades where the base is USDC and then again using the URL that fetchs XLM to USDC trades.
There will now be 20 documents in the Couchbase Stellar bucket:

Couchbase Stellar Trade Documents
Querying Stellar trades in Couchbase
Using N1QL (SQL for JSON) language we can now easily querying from our list of trades.
First, we create a basic index for the documents using the Query tab and running this query:
|
1 |
CREATE PRIMARY INDEX ON stellar |
In a larger scale example you would want to create secondary indexes on the fields you are interested in querying. But with this small set of documents, don’t worry about it.
Now we can run the actual query. In this query we use some basic functions to convert types, reformat the date, and select the values we are interested in. All the documents are JSON formatted and any query will default to showing you the source JSON matches, as shown here:
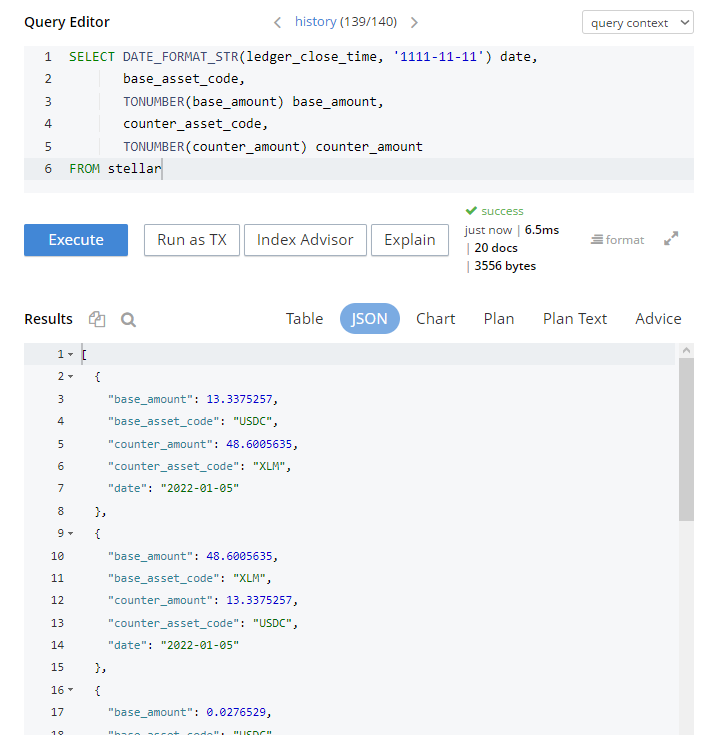
Couchbase Query of Stellar Trades in JSON
Select the Table button above the results to show it in a more structured manner:
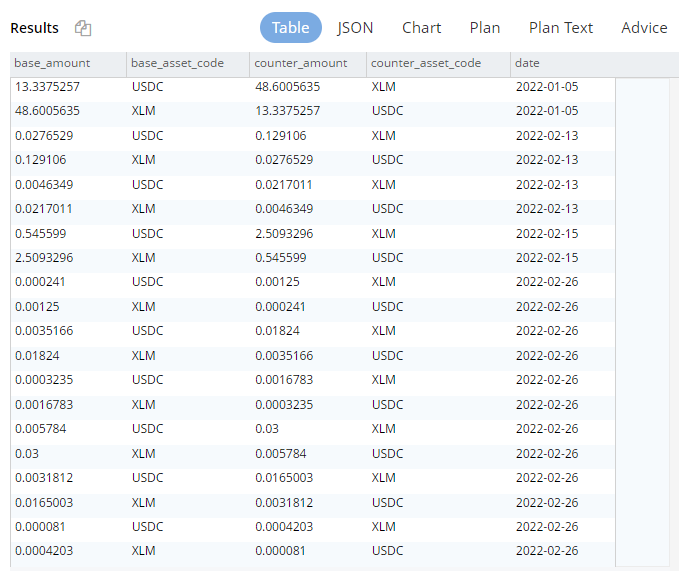
Couchbase Query Stellar trades shown in a table
The table can be easily sorted. The Chart button can now also be used because we have a good field for the X-axis (date) and Y-axis (base or counter amounts). Select the options after choosing the Chart button as shown here:
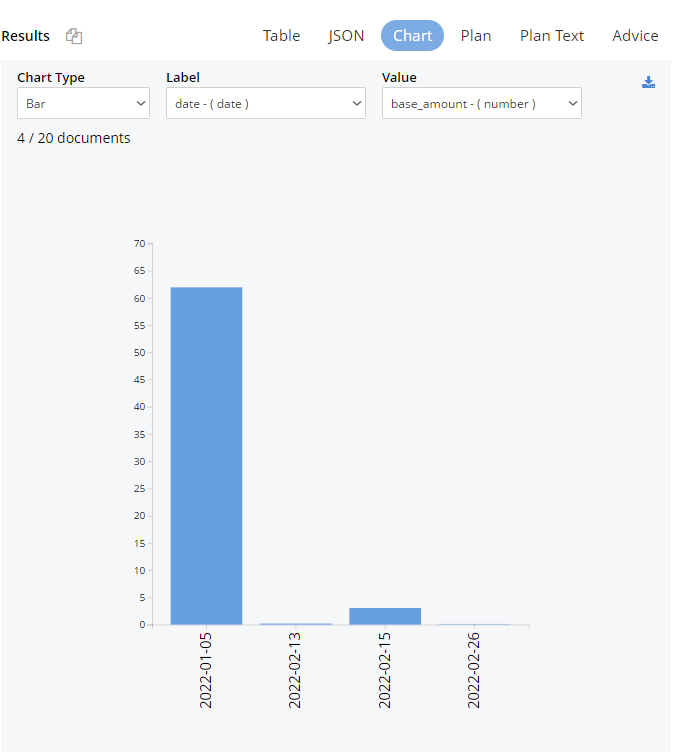
Couchbase query of Stellar trades shown in a chart
This is a simple yet effective way to dig further into your data.
What else can we do?
So far we’ve kept the examples very simple – fetch some Stellar account and trade details and store them in Couchbase NoSQL documents. This is just the tip of the iceberg!
In future posts, we’ll show some more examples of various types of document joins and investigate further into understanding the value lost or gained from doing the above trades.
For now, you can try tweaking the query by accessing the price objects and see what calculations can help you discover on profit/loss. (Hint: the price object has a numerator and denominator in it and can be accessed as a field using price.n and price.d in the query.)
What next?
Here are some additional links to read up on the topics we discussed: