This post describes how to build a basic client that records activity on the Stellar Decentralized Blockchain. Stellar hosts a growing list of new and different cryptocurrency alt-coins and tokens. With the code from this post you can create a basic query tool of assets held in a Stellar account, using Couchbase for storage and query.
What you’ll need
Couchbase
To follow along, set up a recent version of Couchbase that is equal to or higher than 7.0.2. You can do most things with earlier versions but in future posts, you won’t be able to access the built-in charting, scopes, or collections. Couchbase Capella database-as-a-service is available as well with a simple free trial, or you can install an on-prem or Docker version of Couchbase.
Using the built-in Couchbase Admin UI – choose the Bucket menu in the sidebar and the Add Bucket button (top right). Create a bucket called stellar, as shown in Figure 1. It needs minimal memory assigned to it, mine defaults to 300MB which will be more than enough.
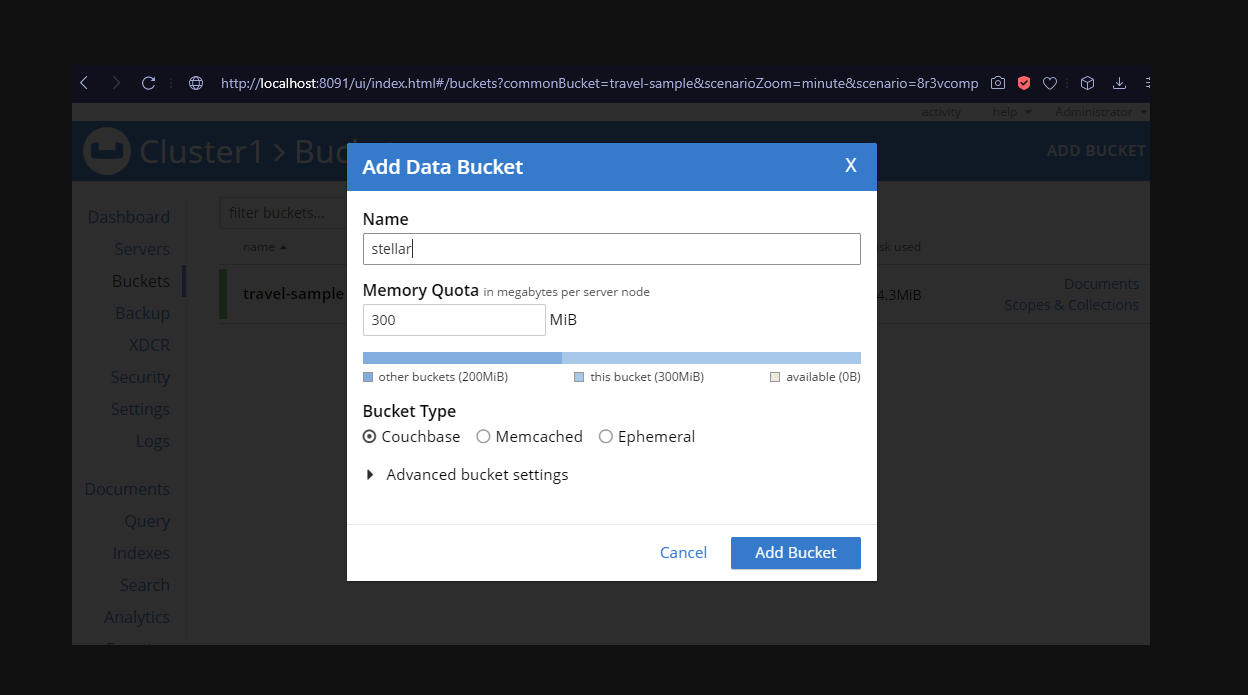
Figure 1. Add a new data bucket to the Couchbase cluster.
It will take a minute to warm up before it turns green to show it is available, shown in Figure 2.
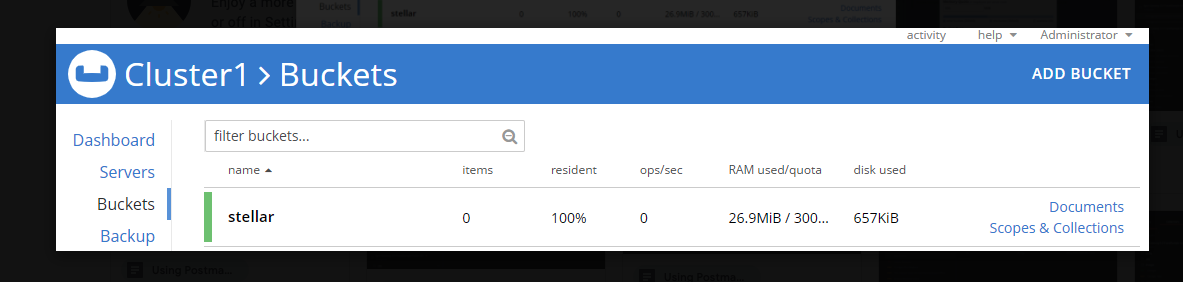
Figure 2. The new bucket is now available.
Stellar Wallet Address
Next you’ll need a Stellar wallet address to monitor. To find an interesting account, use Stellar.expert and its account browser to find a wallet ID.
For my experiments, I’m using this address as it has a small but interesting collection of tokens:
|
1 |
GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ |
Python SDK
Next we’ll use Python 3 and the Couchbase Python SDK. Install the Python SDK using the pip command as described in the documentation. Also include the requests package that we’ll need for downloading from the Stellar web API.
|
1 |
python3 -m pip install --upgrade pip setuptools wheel |
Test the installation by launching Python and importing the Couchbase module:
|
1 2 3 4 5 |
tyler@megaserv:python-stellar$ python3 Python 3.8.10 (default, Nov 26 2021, 20:14:08) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import couchbase |
If it completes with no errors, then we are good to go. Press CTRL+D to quit.
Connecting to Couchbase
The Hello Couchbase examples in the documentation show the basic connection information you need to add to our Python script. At a minimum, to connect to our new bucket we need:
- The administrator username/password (or one with access rights to the new bucket)
- The name/IP of the Couchbase server/cluster
- The name of the new bucket (e.g., stellar)
Create a script called app.py:
|
1 2 3 4 5 6 7 |
from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator cluster = Cluster('couchbase://localhost', ClusterOptions( PasswordAuthenticator('Administrator', 'Administrator'))) cb = cluster.bucket('stellar') |
You can run the script and see if you get any errors before continuing.
Reviewing Stellar.org accounts schema
For this project, we will download account information directly from the Stellar web API and store the raw JSON data in Couchbase for querying later.
To access a Stellar account we will use their Horizon service and hit their /public/asset endpoint. For example, I use Postman.co to do a quick view of the resulting JSON to get a feel for the schema, as shown in Figure 3.
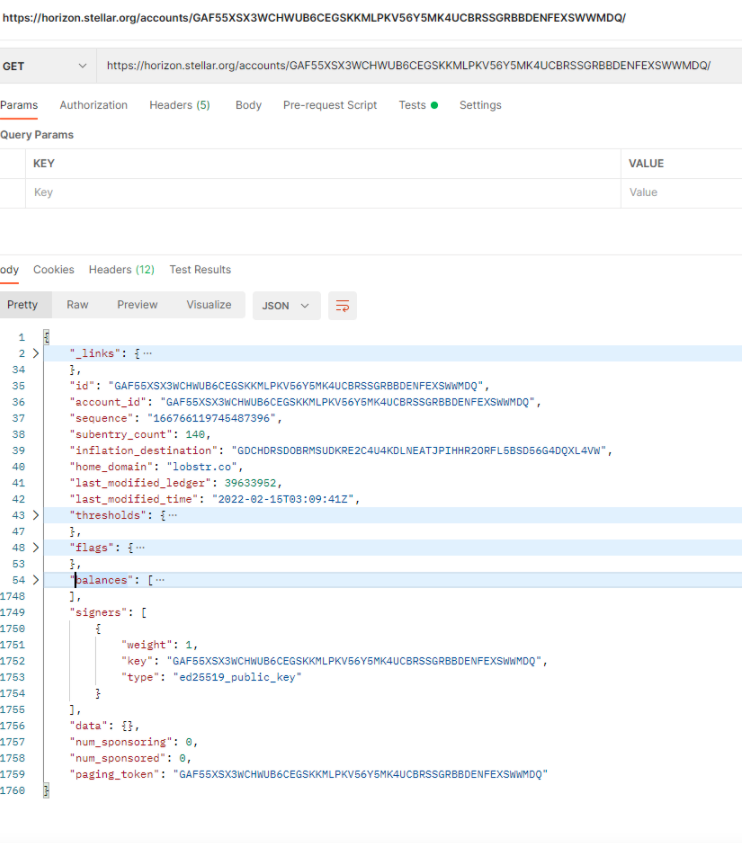
Figure 3. Sample of the Stellar accounts JSON document.
In the figure, note that I’ve collapsed a few objects and lists to see things more clearly. The root level elements, such as account_id, subentry_count, and last_modified_time are potentially useful. But most of the entries are in the balances object, almost 1700 lines in fact.
These are the meat and potatoes of the asset holder, let’s look at them a bit deeper in Figure 4 below.
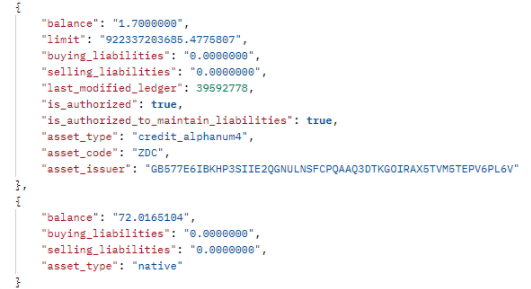
Figure 4. Two entries from the balances list.
In the above figure there are two types of balances shown. There are dozens of others that are not being shown, but they are all similar to the first one shown here. It lists a balance of the number of tokens (1.7), the asset_code (ZDC are Zodiac Tokens), and the asset_issuer address (since many accounts can issue the same asset). Note also the asset_type (credit_alphanum4).
The second entry above is the only different asset_type in the list (native). In this case, it’s an account level base balance, the owner’s Lobstr wallet native token, in this case Stellar Lumens (XLM). This balance can be swapped with balances of any other asset and vice versa through the asset trading account.
Planning our workflow
With the above in mind we can plan for how to store and access all the information we are interested in. So, what are we interested in?
First, we are interested in a daily update of statistics about the account. So, assume we’ll run our script daily and update the information in the database.
Current balances will be good to know – including the native XLM amount and the other token balances. As long as we retain these details in the documents we store, we will be able to query them at any time. We will also have to make sure our key is a sort of timestamp or incrementing ID so that our documents are not overwritten by newer entries.
We could also do some intermediate calculations to keep another document up to date with base totals, etc. but we’ll leave that to a future post.
The next two steps to take are to download this JSON document and then upload it to Couchbase. We’ll then look at the result in the Web Console UI and test out the queries and charts.
Downloading Stellar accounts data with Python
This is, admittedly, a very simple example that we can build on over the upcoming weeks.
To access a web API we use the Python requests module and store the results in a JSON object.
|
1 2 3 4 5 6 7 8 9 |
import requests url = "https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/" response = requests.request("GET", url) jsondoc = response.json() #for key, value in jsondoc.items(): # print(key, ":", value) |
I include a simple loop example to show you how easy it is if you want to see it printed out in a very ugly form. There are prettier printing techniques but we’ll use the ones built into Couchbase to make it easier instead of writing more code here.
Sending JSON document to Couchbase
Next we use our Couchbase bucket object and do an upsert call. Upsert is the same as a document or database insert statement, but will update any existing document if it already exists. In our case, we also want to generate a unique ID and use it for our document ID.
Let’s add a unix timestamp using the time module and build a key, as shown in the Python SDK getting started guide, which also includes some basic exception capturing.
Putting it all together
Now let’s step back and look at the consolidated code example built with various functions to help compartmentalize everything and make it a little more reusable.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import requests, time from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator account = 'GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ' def connect(): cluster = Cluster('couchbase://localhost', ClusterOptions(PasswordAuthenticator('Administrator', 'Administrator'))) return cluster.bucket('stellar') def getjson(): url = "https://horizon.stellar.org/accounts/%s/" % account print("Fetching: " + url) response = requests.request("GET", url) return response.json() def upsert_document(connection, doc): now = int( time.time() ) try: key = str(now) + "_" + account[:5] result = connection.upsert(key, doc) print(result) except Exception as e: print("Error",e) cb = connect() json = getjson() upsert_document(cb, json) |
The result will list the web API URL that was used and show either an error or the OperationResult details:
|
1 2 3 4 |
$ python app.py Fetching: https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/ OperationResult<rc=0x0, key='1644906573_GAF55', cas=0x16d3e1d051760000, tracing_context=0, tracing_output=None> |
Looking at token results in the web console
After running the script a few times you should have a few documents in the project bucket now. When you have selected the stellar bucket, press the Documents button (top right) to see a list of documents that you can interact with, one result is shown in Figure 5.
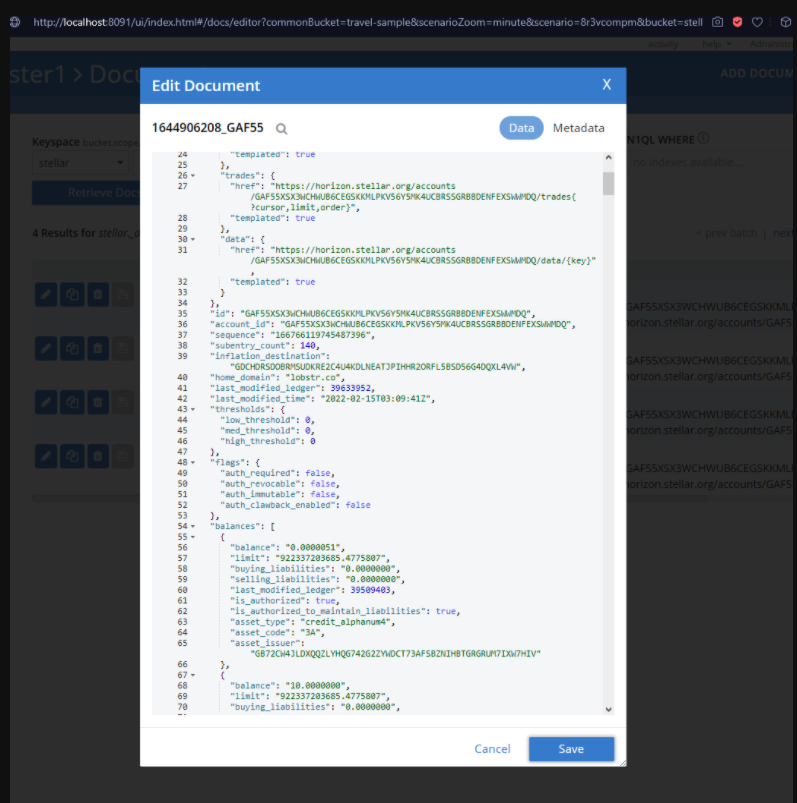
Figure 5. Sample Stellar account document open in Couchbase web console.
To enable querying we need to build a few indexes. Switch to the Query tab and enter these N1QL query statements to get a few indexes set up. Note, we are using a default collection of documents, so we prefix the bucket name to denote that. (In a future post we’ll segregate our documents for different purposes and use collections to do so.)
|
1 2 3 4 |
create primary index on default:stellar; create index idx_account_id on default:stellar(id); create index idx_modified on default:stellar(last_modified_time); create index idx_entrycount on stellar(subentry_count); |
For each of the different assets:
|
1 2 3 4 |
create index idx_asset_code on stellar(balances.asset_code); create index idx_asset_type on stellar(balances.asset_type); create index idx_asset_issuer on stellar(balances.asset_issuer); create index idx_asset_balance on stellar(balances.balance); |
Then test the index with a basic query:
|
1 |
select count(*) from stellar; |
The Results window should show a basic output with the number of documents in the bucket, in this case, 7 documents as shown in Figure 6.
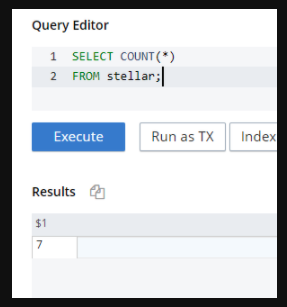
Figure 6. Sample query to count the documents in the bucket.
Querying attributes in a set of JSON documents
You can build queries easily as N1QL is very similar to standard SQL but with JSON intelligence built-in. There are functions that allow us to access entries in the balances list object as if they were each columns. Using UNNEST, each of the sub-entries becomes an accessible field name in the query.
For example, the following query lists all the assets and balances:
|
1 2 3 |
SELECT balances.balance AS balance, balances.asset_code FROM stellar UNNEST balances |
The query window shows the results in JSON by default, but you can switch it to the Table option and see our results so far:
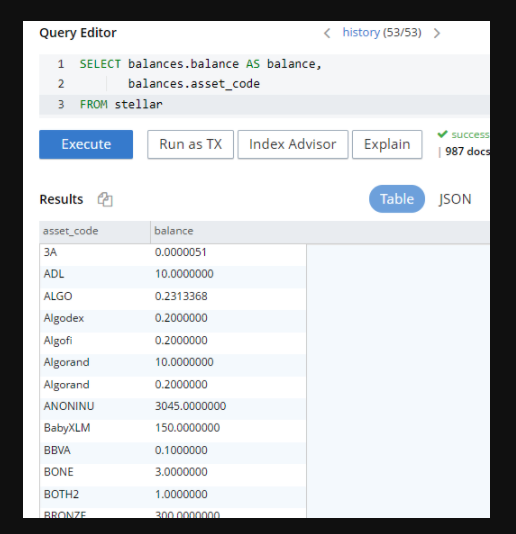
Next steps
In our next post, we’ll dive deeper and build some charts and use some more querying magic.
Here are some additional links to read up on the topics we discussed:
- Start using the Couchbase Python SDK
- Couchbase N1QL checksheet (PDF)
- Stellar decentralized exchange (stellar.org)
- Blockchain basics
- Stellar developer API docs (accounts)
- Stellar Lumens – XLM – the token of the future