As incorporações vetoriais são um componente essencial do aprendizado de máquina que converte informações de "alta dimensão", como texto ou imagens, em um espaço vetorial estruturado. Esse processo permite a capacidade de processar e identificar dados relacionados de forma mais eficaz, representando-os como vetores numéricos. Nesta postagem, você aprenderá a criar embeddings vetoriais, seus tipos e sua implantação em vários casos de uso.
Explicação sobre embeddings vetoriais
As incorporações vetoriais são como a tradução de informações que entendemos em algo que um computador entende. Imagine que você está tentando explicar o conceito de "Dia dos Namorados" a um computador. Como os computadores não entendem conceitos como feriados, romance e contexto cultural da mesma forma que nós, temos que traduzi-los em algo que eles entendem: números. É isso que os embeddings vetoriais fazem. Eles representam palavras, imagens ou qualquer tipo de dados em uma lista de números que representam o que essas palavras ou imagens representam.
Por exemplo, com palavras, se "cat" (gato) e "kitten" (gatinho) forem semelhantes, quando processadas por meio de um modelo de linguagem (grande), suas listas de números (ou seja, vetores) ficarão bem próximas. No entanto, não se trata apenas de palavras. É possível fazer a mesma coisa com fotos ou outros tipos de mídia. Portanto, se você tiver várias fotos de animais de estimação, as incorporações de vetores ajudarão o computador a ver quais são semelhantes, mesmo que ele não "saiba" o que é um gato.
Digamos que estamos transformando as palavras "Valentine's Day" (Dia dos Namorados) em um vetor. A string "Valentine's Day" seria fornecida a algum modelo, normalmente um LLM (modelo de linguagem grande)que produziria uma matriz de números a ser armazenada junto com as palavras.
|
1 2 3 4 |
{ "word": "Valentine's Day", "vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...] } |
Os vetores são muito longos e complexos. Por exemplo, Tamanho do vetor da OpenAI é normalmente 1536, o que significa que cada incorporação é uma matriz de 1536 números de ponto flutuante.
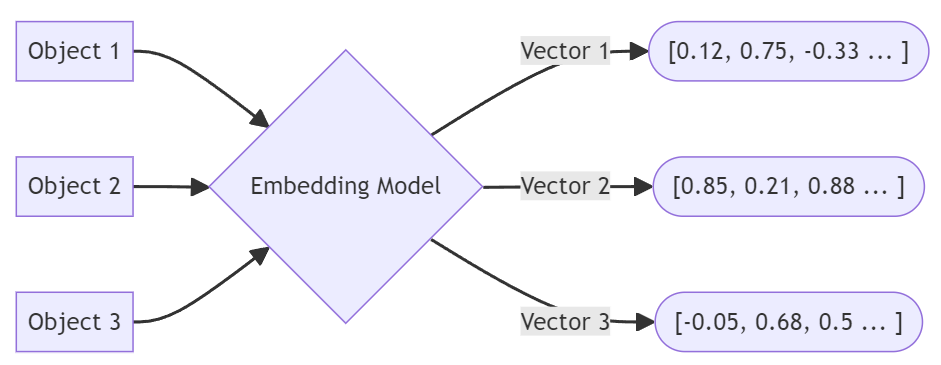
Por si só, esses dados não significam muito: trata-se de encontrar outras incorporações que sejam próximo.
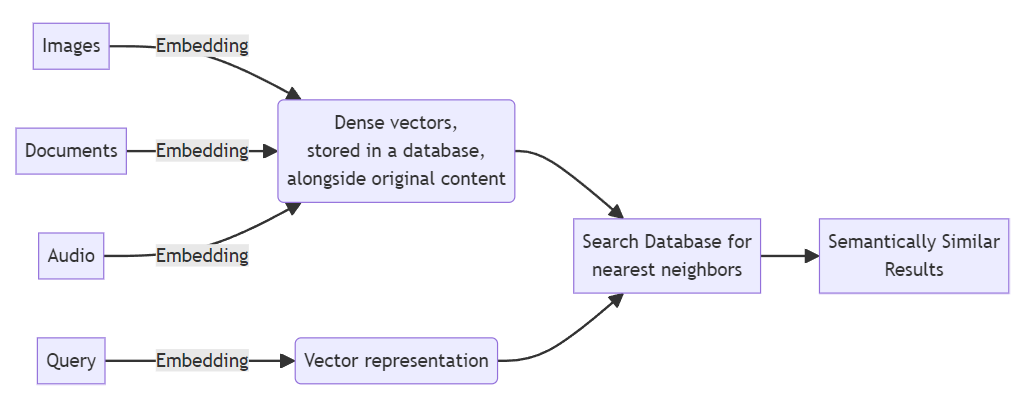
Nesse diagrama, um algoritmo de vizinho mais próximo pode encontrar dados com vetores próximo para a consulta vetorizada. Esses resultados são retornados em uma lista (ordenados por sua proximidade).
Tipos de embeddings de vetores
Há vários tipos de embeddings, cada um com sua maneira exclusiva de entender e representar dados. Aqui está um resumo dos principais tipos que você pode encontrar:
Embeddings de palavras: Os embeddings de palavras traduzem palavras individuais em vetores, capturando a essência de seu significado. Modelos populares como Word2Vec, GloVe e FastText são usados para criar esses embeddings. Eles podem ajudar a mostrar a relação entre as palavras, como entender que "rei" e "rainha" estão relacionados da mesma forma que "homem" e "mulher".
Aqui está um exemplo do Word2Vec em ação:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from gensim.models import Word2Vec sentences = [ "Couchbase is a distributed NoSQL database.", "Couchbase Capella provides flexibility and scalability.", "Couchbase supports SQL++ for querying JSON documents.", "Couchbase Mobile extends the database to the edge.", "Couchbase has a built-in Full Text Search Engine" ] # Preprocess the sentences: tokenize and lower case processed_sentences = [sentence.lower().split() for sentence in sentences] # Train the Word2Vec model model = Word2Vec(sentences=processed_sentences, vector_size=100, window=5, min_count=1, workers=4) # Get the vector for a word word_vector = model.wv['couchbase'] # Print the vector print(word_vector) This Python code would output something like: [-0.00053675, 0.000236998, 0.00510486, 0.00900848, ..., 0.000901757, 0.00639282] |
Embeddings de frases e documentos: Além de palavras isoladas, os embeddings de frases e documentos representam partes maiores do texto. Essas incorporações podem capturar o contexto de uma frase ou documento inteiro, e não apenas palavras individuais. Modelos como BERT e Doc2Vec são bons exemplos. Eles são usados em tarefas que exigem a compreensão da mensagem geral, do sentimento ou do tópico dos textos.
Embeddings de imagens: Convertem imagens em vetores, capturando recursos visuais como formas, cores e texturas. Os embeddings de imagem são criados usando modelos de aprendizagem profunda (como CNNs: Redes neurais convolucionais). Eles permitem tarefas como reconhecimento de imagens, classificação e pesquisas de similaridade. Por exemplo, uma incorporação de imagem pode ajudar um computador a reconhecer se uma determinada imagem é um cachorro-quente ou não.
Embeddings de gráficos: Os Graph Embeddings são usados para representar relacionamentos e estruturas, como redes sociais, organogramas ou caminhos biológicos. Eles transformam os nós e as bordas de um gráfico em vetores, capturando como os itens estão conectados. Isso é útil para recomendações, agrupamento e detecção de comunidades (agrupamentos) em redes.
Embeddings de áudio: Semelhante à incorporação de imagens, a incorporação de áudio traduz o som em vetores, capturando recursos como tom, timbre e ritmo. Eles são usados em tarefas de reconhecimento de voz, análise de música e classificação de som.
Incorporação de vídeos: Os embeddings de vídeo capturam a dinâmica visual e temporal dos vídeos. Eles são usados para atividades como pesquisa de vídeo, classificação e compreensão de cenas ou atividades dentro da filmagem.
Como criar embeddings vetoriais
De modo geral, há quatro etapas:
-
- Escolha seu modelo de incorporação de vetor: Decida o tipo de modelo com base em suas necessidades. Word2Vec, GloVe e FastText são populares para embeddings de palavras, enquanto BERT e GPT-4 são usados para embeddings de frases e documentos, etc.
- Prepare seus dados: Limpe e pré-processe seus dados. No caso de texto, isso pode incluir a tokenização, a remoção de "stopwords" e, possivelmente, a lematização (redução das palavras à sua forma básica). No caso de imagens, isso pode incluir redimensionamento, normalização de valores de pixel etc.
- Treinar ou usar modelos pré-treinados: Você pode treinar seu modelo em seu conjunto de dados ou usar um modelo pré-treinado. O treinamento do zero requer uma quantidade significativa de dados, tempo e recursos computacionais. Os modelos pré-treinados são uma maneira rápida de começar e podem ser ajustados (ou aumentados) com seu conjunto de dados específico.
- Gerar Embeddings: Quando seu modelo estiver pronto, alimente seus dados por meio dele (via SDK, REST, etc.) para gerar embeddings. Cada item será transformado em um vetor que representa seu significado semântico. Normalmente, os embeddings são armazenados em um banco de dados, às vezes junto com os dados originais.
Aplicações de embeddings vetoriais
Então, qual é o grande problema do vetor? Que problemas posso atacar com ele? Aqui estão vários casos de uso que são possibilitados pelo uso de embeddings vetoriais para encontrar itens semanticamente semelhantes (ou seja, "pesquisa vetorial"):
Processamento de linguagem natural (NLP)
-
- Pesquisa semântica: Melhorar a relevância da pesquisa e a experiência do usuário, utilizando melhor o significado por trás dos termos de pesquisa, acima e além da pesquisa tradicional baseada em texto.
- Análise de sentimento: Análise do feedback do cliente, publicações em mídias sociais e avaliações para avaliar o sentimento (positivo, negativo ou neutro).
- Tradução de idiomas: Compreender a semântica do idioma de origem e gerar o texto apropriado no idioma de destino.
Sistemas de recomendação
-
- Comércio eletrônico: Personalização de recomendações de produtos com base no histórico de navegação e de compras.
- Plataformas de conteúdo: Recomendação de conteúdo aos usuários com base em seus interesses e interações anteriores.
Visão computacional
-
- Reconhecimento e classificação de imagens: Identificação de objetos, pessoas ou cenas em imagens para aplicações como vigilância, marcação de fotos, identificação de peças, etc.
- Pesquisa visual: Permitir que os usuários pesquisem com imagens em vez de consultas de texto.
Assistência médica
-
- Descoberta de medicamentos: Ajuda a identificar interações.
- Análise de imagens médicas: Diagnóstico de doenças por meio da análise de imagens médicas, como raios X, ressonâncias magnéticas e tomografias computadorizadas.
Finanças
-
- Detecção de fraudes: Análise de padrões de transações para identificar e evitar atividades fraudulentas.
- Pontuação de crédito: Análise do histórico e do comportamento financeiro.
Geração Aumentada por Recuperação (RAG)
Geração aumentada por recuperação é uma abordagem que combina os pontos fortes de um modelos de linguagem generativos (como o GPT-4) com recursos de recuperação de informações (como a pesquisa vetorial) para aprimorar a geração de respostas.
O RAG pode aumentar uma consulta a um LLM como o GPT-4 com informações de domínio atualizadas e relevantes. Há duas etapas:
-
- Consulta de documentos relevantes.
A pesquisa vetorial é particularmente boa para identificar dados relevantes, mas qualquer consulta pode funcionar, inclusive consultas analíticas que Colunar do Couchbase torna possível. - Passe os resultados da consulta como contexto para o modelo generativo, juntamente com a própria consulta.
- Consulta de documentos relevantes.
Essa abordagem permite que o modelo produza respostas mais informativas, precisas e contextualmente relevantes.
Os casos de uso do RAG incluem:
-
- Resposta a perguntas: Ao contrário dos sistemas de domínio fechado que dependem de um conjunto de dados fixo, o RAG pode acessar informações atualizadas de sua fonte de conhecimento.
- Criação de conteúdo: O RAG pode aumentar o conteúdo com fatos e números relevantes, garantindo maior precisão.
- Chatbots/Assistentes: Bots como Couchbase Capella iQ pode fornecer respostas mais detalhadas e informativas em uma ampla gama de tópicos.
- Ferramentas educacionais: O RAG pode fornecer explicações detalhadas ou informações suplementares sobre uma ampla variedade de assuntos, de acordo com as dúvidas do usuário.
- Sistemas de recomendação: O RAG pode gerar explicações ou motivos personalizados por trás das recomendações, recuperando informações relevantes que correspondam aos interesses do usuário ou ao contexto da consulta.
Embeddings vetoriais e Couchbase
O Couchbase é um banco de dados multiuso que se destaca no gerenciamento de dados JSON. Essa flexibilidade se aplica às incorporações vetoriais, pois a natureza sem esquema do Couchbase permite o armazenamento e a recuperação eficientes de dados vetoriais complexos e multidimensionais juntamente com documentos JSON tradicionais (conforme mostrado anteriormente nesta postagem do blog)
|
1 2 3 4 |
{ "word": "Valentine's Day", "vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...] } |
O ponto forte do Couchbase está em sua capacidade de lidar com uma ampla variedade de tipos de dados e casos de uso em uma única plataforma, em contraste com as plataformas especializadas e de finalidade única. bancos de dados vetoriais (como o Pinecone) focado exclusivamente em pesquisa vetorial e similaridade. Os benefícios da abordagem do Couchbase incluem:
Consulta híbrida: Com o Couchbase, você pode combinar SQL++, chave/valor, geoespacial e pesquisa de texto completo em uma única consulta para reduzir o processamento pós-consulta e criar mais rapidamente um conjunto avançado de recursos de aplicativos.
Versatilidade: O Couchbase oferece suporte à pesquisa de valor-chave, de documentos e de texto completo, bem como à análise e à geração de eventos em tempo real, tudo na mesma plataforma. Essa versatilidade permite que os desenvolvedores usem embeddings vetoriais para recursos avançados de pesquisa e recomendação sem precisar de um sistema separado.
Escalabilidade e desempenho: Projetado para alto desempenho e escalabilidade, o Couchbase garante que os aplicativos que usam embeddings vetoriais possam ser dimensionados de forma eficiente para atender às crescentes demandas de dados e tráfego.
Experiência em desenvolvimento unificado: A consolidação dos casos de uso de dados no Couchbase simplifica o processo de desenvolvimento. As equipes podem se concentrar na criação de recursos em vez de gerenciar vários bancos de dados, integrações e pipelines de dados.
Próximas etapas
Dar Couchbase Capella e veja como um banco de dados multiuso pode ajudá-lo a criar aplicativos poderosos e adaptáveis. Você também pode download a versão do servidor local do Couchbase Server 7.6, completa com integração de pesquisa vetorial.
Você pode começar a trabalhar em minutos com uma avaliação gratuita (não é necessário cartão de crédito). IA generativa do Capella iQ está integrado e pode ajudá-lo a começar a escrever suas primeiras consultas.
Perguntas frequentes sobre incorporação de vetores
Qual é a diferença entre vetorização e incorporação de texto?
A vetorização de texto é uma maneira de contar as ocorrências de palavras em um documento. A incorporação representa o significado semântico das palavras e seu contexto.
Qual é a diferença entre indexação e incorporação?
A incorporação é o processo de geração dos vetores. Indexação é o processo que permite a recuperação dos vetores e seus vizinhos.
Quais tipos de conteúdo podem ser incorporados?
Palavras, textos, imagens, documentos, áudio, vídeo, gráficos, redes, etc.
Como os embeddings vetoriais dão suporte à IA generativa?
A incorporação de vetores pode ser usada para encontrar contexto para aumentar a geração de respostas. Consulte a seção acima sobre RAG.
O que são embeddings no aprendizado de máquina?
Uma representação matemática de dados usada para representar os dados de forma compacta e para encontrar semelhanças entre os dados.