Quando nós, desenvolvedores, ouvimos o termo expansão de dados, ele pode parecer um pouco com um termo comercial como TCO, ROI e similares. Todos esses termos têm uma realidade para os desenvolvedores, fora do âmbito do analista e do gerente. Portanto, hoje quero falar sobre a realidade da expansão de dados para os desenvolvedores. Como isso afeta nosso trabalho.
O Data Sprawl pode ser resumido no fato de que temos dados, uma quantidade enorme, armazenados em muitos armazenamentos de dados diferentes. Além disso, nós, como desenvolvedores, temos que fazer com que esses armazenamentos de dados interajam entre si. E, é claro, quanto mais, melhor, certo 😬?
Geralmente está associado a custos financeiros mais altos:
-
- Infraestrutura
- Licenças
- Integração
- Treinamento
- Operacional
- Custos de suporte
Plataformas separadas com várias interfaces lhe darão dores de cabeça por causa disso:
-
- Implementação e gerenciamento independentes
- Diferentes modelos de dados e interfaces de programação
- Integração entre vários produtos
- Tíquetes de suporte com diferentes fornecedores
E precisamos gastar mais tempo, esforços e custos por causa disso:
-
- Licença e contrato
- Treinamento para desenvolvedores e operações
- Suporte
- Criar API ou conector para o banco de dados
- Aquisição de infraestrutura
É um pouco sombrio quando se olha dessa forma, mas é um desafio cotidiano para muitas empresas. E não apenas com diferentes cargas de trabalho de dados, isso também se aplica aos aplicativos em nuvem.
Vamos dar uma olhada em um exemplo específico. Criei um aplicativo que usa CRUD de um banco de dados de documentos, cache de um armazenamento de cache e pesquisa de um mecanismo de pesquisa de texto completo. (Fonte do GitHub)
Dando uma olhada nesse esquema, você pode basicamente contar cada seta que vê como uma interação entre diferentes sistemas que os desenvolvedores precisam pensar e codificar.
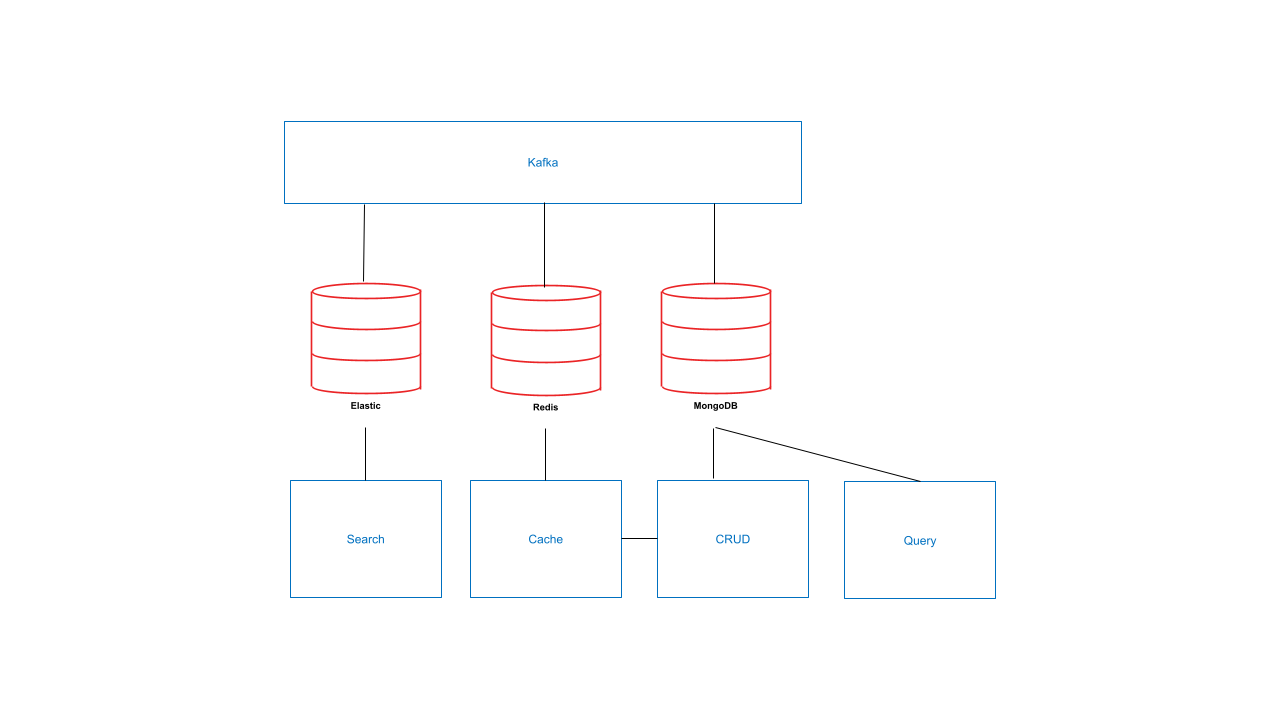
Aqui estamos sincronizando automaticamente os bancos de dados de cache e pesquisa usando streaming de eventos. São 8 interações e 4 armazenamentos de dados para aprender e gerenciar. Como você precisa garantir que cada armazenamento esteja conectado ao serviço de streaming e que receba as atualizações corretas, é necessário gerenciar o serviço de streaming, a pesquisa, o cache e o armazenamento de dados. Você também precisa integrar o cache ao seu serviço CRUD (idealmente com os outros serviços, mas vamos manter isso simples). Em resumo: há muito o que fazer.
Podemos limitar essas interações eliminando os serviços de streaming e garantindo que outros serviços sejam atualizados manualmente. Essa é uma licença a menos, algo a ser operado, algo a ser aprendido, algo a ser integrado. Ainda não é o ideal, mas poderia ser assim:
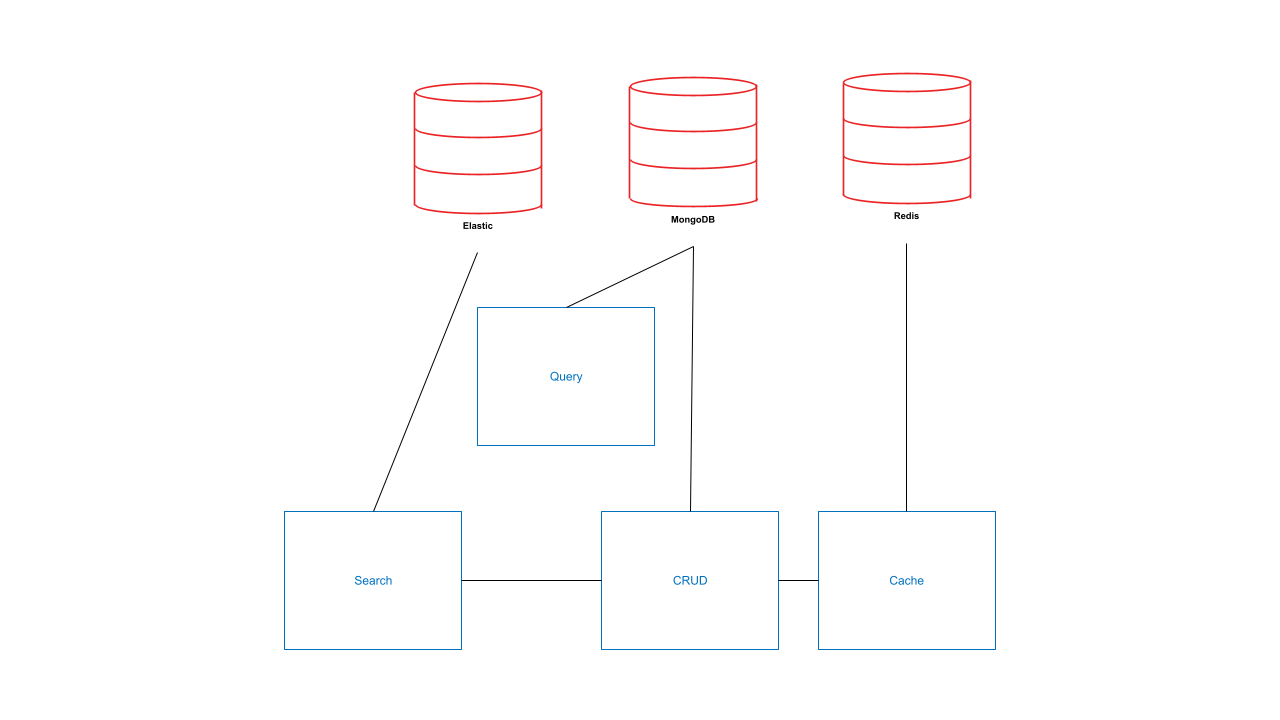
É um pouco mais simples, apenas 6 interações e 3 armazenamentos de dados em vez de 8 e 4. Mas ainda há muitas interações e parte da integração de streaming precisa ser feita manualmente. Antes, porém, poderíamos ter aprendido e usado os conectores existentes entre os serviços existentes. Vamos dar uma olhada rápida no código de amostra Java/Spring Boot escrito para isso.
Há quatro interfaces que representam o que os desenvolvedores podem fazer com os armazenamentos de dados. CRUD, Cache, Consulta e Pesquisa.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public interface CRUD { StoredFileDocument read(String id); void create(String id, StoredFileDocument doc); void update(String id, StoredFileDocument doc); void upsert(String id, StoredFileDocument doc); void delete(String id); } public interface Cache { void writeInCache(StoredFileDocument doc); StoredFileDocument readFromCache(String id); void touch(String id); void evict(String id); } public interface Query { List<Map<String, Object>> query(String whereClause); List<Map<String, Object>> findAll(); } public interface Search { List<Map<String, Object>> search(String term); void index(StoredFileDocument doc); void delete(String id); } |
Não mostraremos todo o código nesta postagem, mas apenas algumas das partes interessantes.
Estamos em uma configuração em que o serviço CRUD tem links para os serviços Search e Cache. Vamos ver como seria em uma versão simplificada. Temos de importar o serviço de cache e de pesquisa, pois eles são necessários. A partir daí, todos os métodos são afetados por eles. O Read precisa primeiro consultar o cache, atualizar a última vez que o objeto foi encontrado no cache ou obtê-lo do banco de dados e inseri-lo no cache. Em seguida, os métodos Create, Update e Delete afetam o Cache e a Pesquisa, pois os dados recém-criados, atualizados ou excluídos precisam ser propagados para o Cache ou para os índices do armazenamento de dados da Pesquisa.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
@Service public class MongoCRUD implements CRUD { private MongoCollection<StoredFileDocument> collection; private Cache cache; private Search search; public MongoCRUD(MongoCollection<StoredFileDocument> collection, Cache cache, Search search) { this.collection = collection; this.cache = cache; this.search = search; } @Override public StoredFileDocument read(String id) { StoredFileDocument doc = cache.readFromCache(id); if (doc == null) { System.out.println(id); doc = collection.find(eq("fileId", id)).first(); cache.writeInCache(doc); } else { cache.touch(id); } return doc; } @Override public void create(String id, StoredFileDocument doc) { doc.setFileId(id); collection.insertOne(doc); cache.writeInCache(doc); search.index(doc); } @Override public void update(String id, StoredFileDocument doc) { collection.findOneAndReplace(eq("fileId", id), doc); cache.touch(id); search.index(doc); } @Override public void upsert(String id, StoredFileDocument doc) { FindOneAndReplaceOptions options = new FindOneAndReplaceOptions().upsert(true); collection.findOneAndReplace(eq("fileId", id), doc, options); cache.touch(id); search.index(doc); } @Override public void delete(String id) { collection.deleteOne(eq("fileId", id)); cache.evict(id); search.delete(id); } } |
Com o Couchbase, isso estaria mais próximo de algo como isto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
@Service @Profile("couchbase") public class CouchbaseCRUD implements CRUD { private Collection collection; public CouchbaseCRUD(Collection collection) { this.collection = collection; } @Override public StoredFileDocument read(String id) { GetResult res = collection.get(id); return res.contentAs(StoredFileDocument.class); } @Override public void create(String id, StoredFileDocument doc) { MutationResult res = collection.insert(id, doc); } @Override public void update(String id, StoredFileDocument doc) { MutationResult res = collection.replace(id, doc); } @Override public void upsert(String id, StoredFileDocument doc) { MutationResult res = collection.upsert(id, doc); } @Override public void delete(String id) { MutationResult res = collection.remove(id); } } |
O motivo pelo qual não precisamos de uma dependência do serviço de Cache e Pesquisa é que o Couchbase já integra um cache e um mecanismo de pesquisa. Não há necessidade de implementar a interface do cache e não há necessidade de implementar o método de exclusão e indexação da interface de pesquisa. É tudo automatizado e integrado.
Normalmente, quando explico isso a alguém, segue-se uma conversa sobre como isso deve ser ruim, porque é preciso fazer concessões para poder fazer todas as coisas. Todas as plataformas de dados, multimodelos, cargas de trabalho múltiplas, como você quiser falar sobre elas, não são criadas da mesma forma, ou pelo menos não com a mesma arquitetura em mente.
O Couchbase pode ser visto como vários bancos de dados diferentes, todos responsáveis por cargas de trabalho diferentes e todos integrados por meio de seu serviço de streaming interno. Dessa forma, cada parte do Couchbase é mantida atualizada automaticamente e cada parte pode se especializar em sua própria carga de trabalho de dados. No final, você obtém 3 interações e 1 datastore.
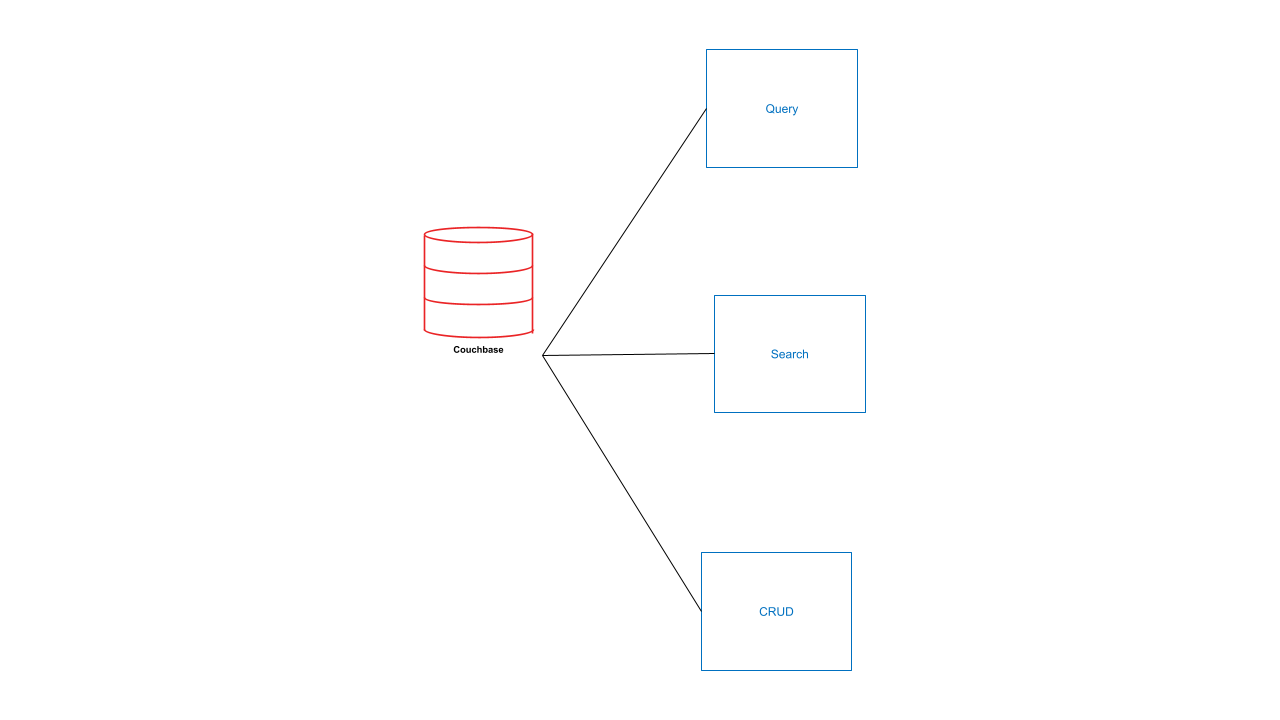
Isso já é muito bom, mas temos mais uma coisa. Nossos serviços estão integrados à nossa linguagem de consulta SQL++. Vamos dar um exemplo. Você tem um CMS que contém uma árvore de documentos, com várias permissões em cada documento, e essas permissões podem ser herdadas por documentos filhos nos quais você deseja executar uma pesquisa como um usuário conectado com um conjunto específico de permissões. Se você estiver usando um mecanismo de busca externo, o que normalmente acontece é o seguinte:
-
- Execute uma consulta de pesquisa no mecanismo de pesquisa
- Reúna os identificadores dos documentos retornados porque nem todo o conteúdo do documento está indexado
- Executar uma consulta para obter os documentos completos
- Se o seu serviço de consulta não for compatível com JOIN, execute outra consulta para obter permissões herdadas e filtrar os documentos
Se quiséssemos tornar as coisas mais complicadas (e talvez também mais reais), poderíamos adicionar uma lógica de cache personalizada a cada etapa. Mas isso já é complicado o suficiente.
O Couchbase pode fazer tudo em uma única etapa. Em uma única consulta SQL++, podemos pesquisar, selecionar os campos que desejamos e fazer JOIN em outros documentos para classificar as permissões. É tão simples quanto isso. Como o Couchbase é uma plataforma de dados bem integrada, sua linguagem de consulta permite que você aproveite todos os seus poderes. Se você estiver interessado, os detalhes podem ser encontrados em outro post.
Encerramento
Então, o que aprendemos hoje? O uso de uma plataforma de dados bem arquitetada pode economizar muito tempo, dinheiro, esforço e dor de cabeça. Porque, no final, você tem menos coisas em que pensar, menos código para escrever, o que significa menos código para manter e uma capacidade mais rápida de enviar para a produção. Felizmente, ela também simplifica e economiza em questões como licenças, treinamento, conformidade e todas aquelas coisas com as quais os gerentes, analistas, seu chefe e o chefe do seu chefe se preocupam!
- Assista à minha palestra com a RedMonk: O que é dispersão de dados? Como aproveitar uma plataforma para lidar com eles
- Confira o código do meu exemplo de expansão de dados
- Saiba mais sobre como Serviços do Couchbase são projetados para tornar o desenvolvimento fácil e simples.
- Experimente o Couchbase Capella DBaaS para colocá-lo à prova