O Couchbase continua a liderar o caminho para permitir a análise de dados de alto desempenho com a introdução de SDKs para Capella ColumnarO SDK da Microsoft, seu banco de dados analítico de ponta, foi projetado para análises JSON em tempo real com ETL zero e opções para write-back operacional. Para os desenvolvedores que precisam de acesso rápido e confiável a bancos de dados colunares, esses SDKs oferecem integração perfeita em várias linguagens de programação. Se você estiver criando em Java, Pythonou Node.jsCom os SDKs do Capella Columnar, você pode aproveitar os recursos avançados do banco de dados analítico do Couchbase com o mínimo de esforço.
Nesta postagem do blog, exploraremos os principais recursos, benefícios e casos de uso do recém-lançado SDKs Colunares Capella-mostrando como eles simplificam as operações de dados para os desenvolvedores que trabalham em aplicativos com uso intensivo de dados. Também apresentamos exemplos de código para ilustrar a simplicidade e a consistência de nossa abordagem.
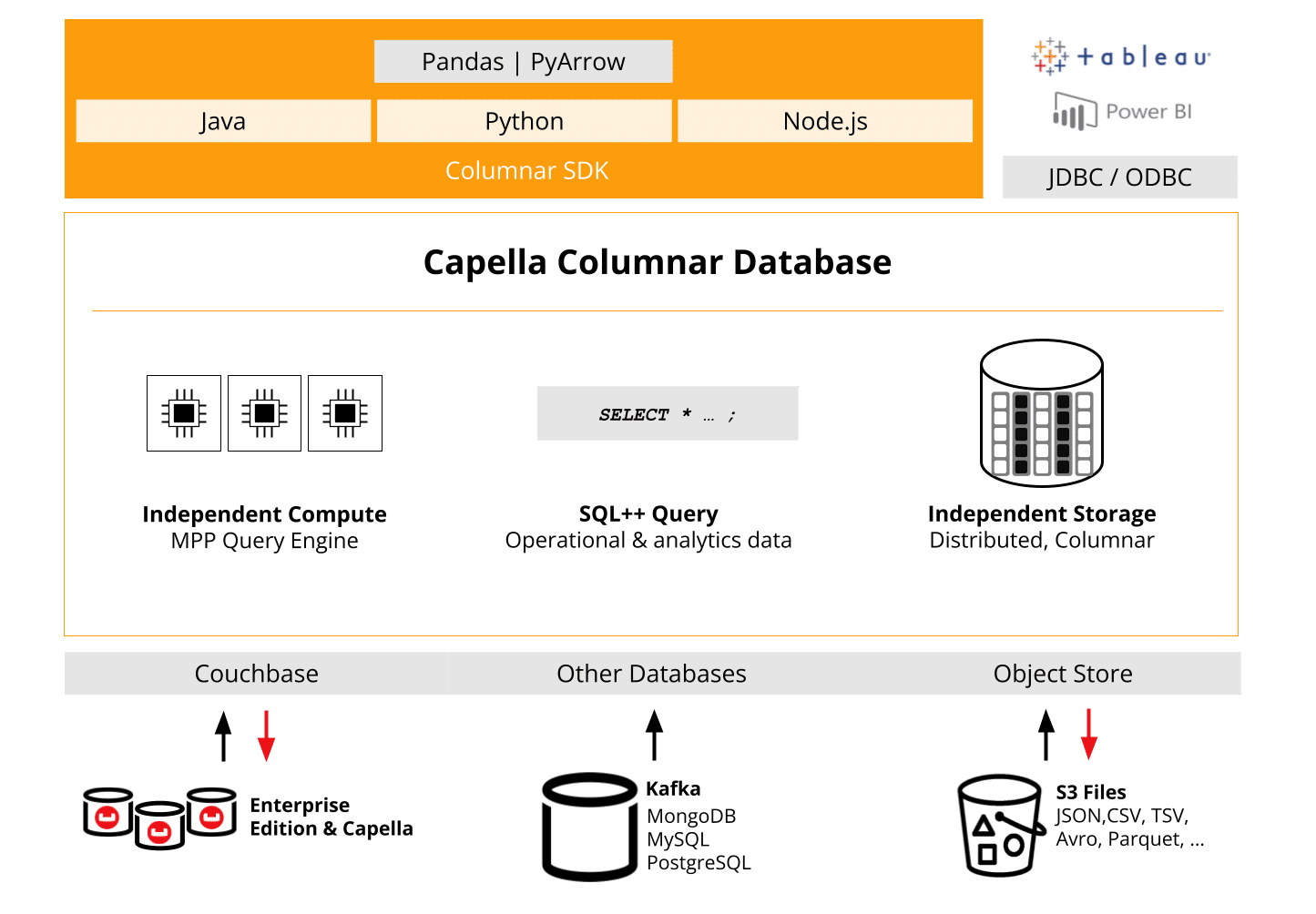
SDKs criados para fins específicos para análise em tempo real
Um dos principais pontos fortes dos Capella Columnar SDKs é sua capacidade de otimizar o acesso aos dados e o desempenho das consultas, tornando-os ideais para cargas de trabalho analíticas em grande escala. Como as organizações dependem cada vez mais da análise de dados em tempo real e do processamento em lote, a consulta eficiente e o gerenciamento de recursos tornam-se essenciais.
Os SDKs do Capella Columnar foram projetados com essas necessidades em mente, oferecendo uma série de recursos que ajudam os desenvolvedores a ajustar as interações de dados e a garantir um alto rendimento, mesmo em condições exigentes. Os SDKs foram desenvolvidos desde o início especificamente para proporcionar alto desempenho e confiabilidade, sem tomar atalhos (como wrappers sobre APIs etc.).
No centro dos SDKs do Capella Columnar estão três pilares principais:
- Facilidade de desenvolvimento
Os desenvolvedores podem interagir com o banco de dados colunar do Couchbase em sua pilha de tecnologia existente, sem a necessidade de ferramentas ou configurações adicionais. Os SDKs suportam nativamente cada linguagem, oferecendo APIs idiomáticas que parecem naturais para os desenvolvedores. - APIs que podem ser descobertas
Os SDKs são projetados com uma API totalmente detectável. Isso significa que, em seu IDECom o SDK, você terá o preenchimento automático e sugestões de funções, classes e parâmetros, acelerando o ciclo de desenvolvimento. Não é mais necessário procurar os métodos certos - o SDK o guiará durante o desenvolvimento. - Robustez
Criados com o desempenho em mente, os SDKs oferecem recursos avançados como gerenciamento de conexões, Tratamento de erros, tempos limitee tentativas. Esses recursos garantem que seu aplicativo permaneça estável mesmo em ambientes de alta carga ou tolerantes a falhas.
Suporte a plataformas e idiomas
Os SDKs do Capella Columnar são compatíveis com um conjunto diversificado de plataformas e linguagens, incluindo:
- Idiomas: Java (17+), Python (3.9-3.12), Node.js (v20, v22)
- Sistemas operacionais: Linux, Windows, macOS (incluindo suporte para processadores ARM, como AWS Graviton e Apple M1)
Ao oferecer suporte a essas plataformas, o Couchbase garante que os desenvolvedores possam implantar seus aplicativos em diversos ambientes, desde infraestruturas de nuvem até sistemas locais.
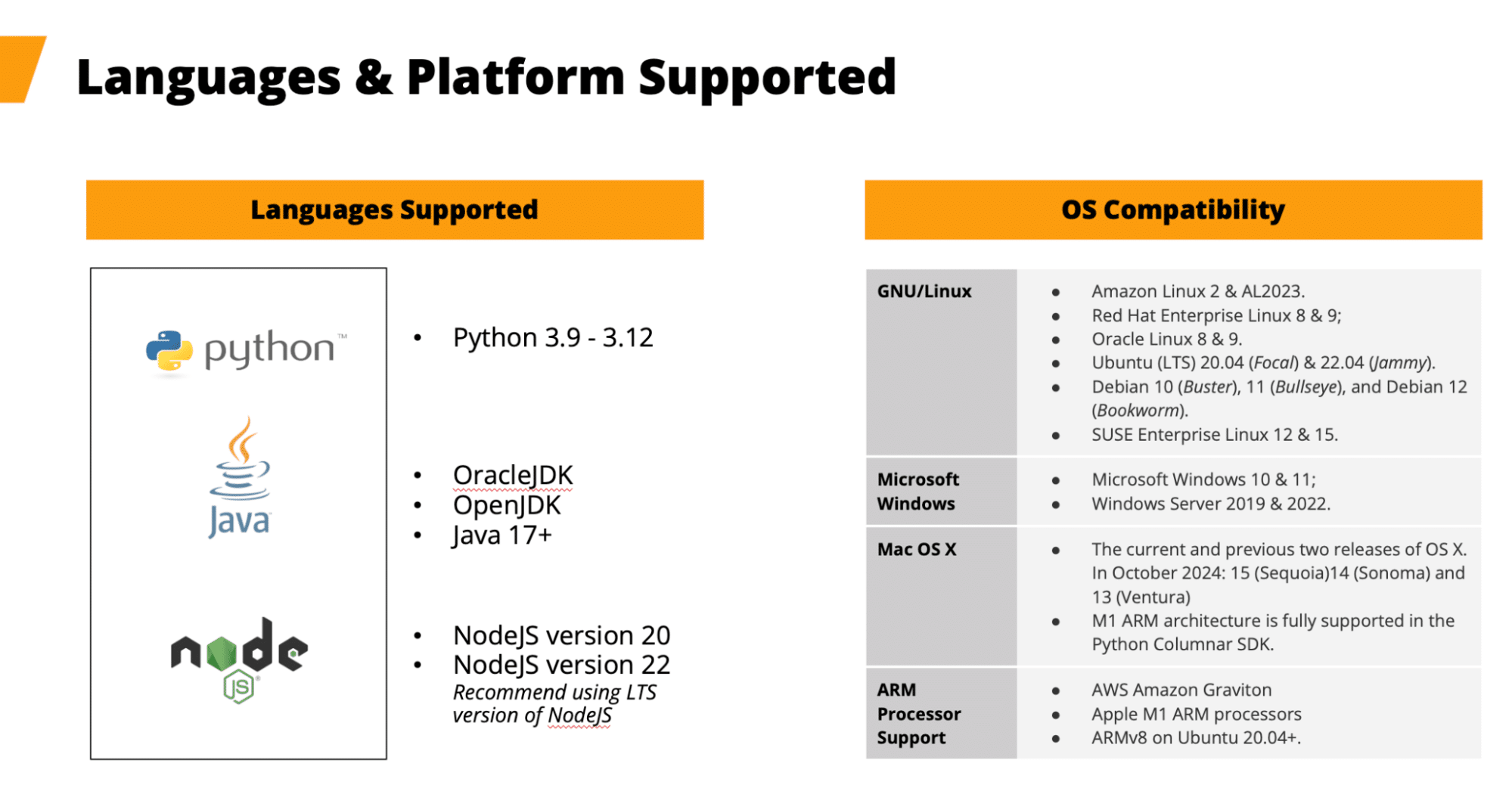
Figura 2. Consulte a documentação do SDK para saber se houve alterações no suporte a idiomas/plataformas
O Couchbase prioriza a preparação para o futuro, mantendo a compatibilidade com versões anteriores do SDK, permitindo que os desenvolvedores atualizem seus aplicativos sem medo de interromper as alterações. Esse compromisso garante que, à medida que novos recursos e aprimoramentos forem introduzidos, as funcionalidades existentes permanecerão intactas, permitindo que as organizações aproveitem os recursos mais recentes e, ao mesmo tempo, preservem seus fluxos de trabalho estabelecidos.
Como os SDKs do Capella Columnar ajudam os dados mestres em escala
O SDKs colunares do Couchbase Capella oferecem um conjunto abrangente de ferramentas para o gerenciamento eficiente da análise de dados em grande escala, com foco na consistência, no desempenho e na escalabilidade.
Aqui está uma visão geral dos principais recursos:
API unificada em todos os idiomas
Os SDKs do Capella Columnar fornecem um API consistente em idiomas como Java, Pythone Node.jssimplificando a colaboração entre equipes e permitindo que os desenvolvedores alternem entre idiomas, mantendo uma experiência de desenvolvimento unificada.
Gerenciamento de dados e execução de consultas simplificados
Esses SDKs oferecem acesso intuitivo a escopos e coleçõescom suporte para ambos Chamadas de API síncronas e assíncronas. Para a execução de consultas, eles permitem consultas SQL++ flexíveis com opções para Leituras com buffer (para conjuntos de dados na memória) e Leituras em streaming (para processamento em tempo real de grandes conjuntos de dados), otimizando o desempenho com base nas necessidades operacionais.
Gerenciamento de conexão resiliente e tratamento de erros
Os SDKs se ajustam automaticamente a alterações na topologia do banco de dadosgarantindo um desempenho suave durante failovers ou reequilibra. Eles também apresentam novas tentativas automáticas de consulta e fornecer Limpar mensagens de erro alinhado com o Códigos de erro do Analytics para ajudar na resolução rápida de problemas.
Suporte a várias plataformas e flexibilidade de controle de versão
Com suporte para vários ambientes, como Linux, Windows, MacOSe Processadores ARMOs SDKs oferecem flexibilidade entre as infraestruturas. Seus estrutura de API com controle de versão garante a compatibilidade com os novos recursos do Couchbase, permitindo que os desenvolvedores integrem atualizações sem preocupações com a compatibilidade.
Escalabilidade e arquitetura distribuída
Os SDKs do Capella Columnar aproveitam os recursos do Couchbase arquitetura distribuída para particionamento automático de dados e Replicação entre centros de dados (XDCR). Isso permite o dimensionamento contínuo em vários nós e regiões, garantindo alta disponibilidade e eficiente distribuição global de dados à medida que os aplicativos crescem.
Casos de uso para Capella Columnar SDKs
Análise de dados em tempo real
Para organizações que lidam com análises em tempo real, os SDKs do Capella Columnar simplificam o processamento de dados. Com suporte a consultas de streamingSe o desenvolvedor tiver um sistema de gerenciamento de dados, poderá processar os dados recebidos linha por linha, o que é perfeito para cenários como análise de registros, Dados do sensor de IoTou transações financeiras em tempo real.
Exemplo de caso de uso de segmentação de anúncios
Um caso de uso de análise em tempo real com os SDKs do Capella Columnar pode envolver a integração de dados de fluxo de cliques ou de interação com a Web de, por exemplo, um bucket S3 para impulsionar a entrega de anúncios just-in-time. Nesse cenário, os dados de fluxo de cliques, que capturam as interações do usuário em tempo real em um site, são transmitidos para o Capella Columnar usando configurações de links externos. Os SDKs permitem a consulta rápida e eficiente desses dados à medida que eles chegam, usando consultas SQL++ flexíveis para analisar o comportamento do usuário em tempo real.
Ao mesmo tempo, os dados do perfil do usuário armazenados em um banco de dados NoSQL ou relacional são alimentados no sistema por meio de conectores Kafka, permitindo uma visão unificada das preferências e do histórico de cada usuário. Ao combinar esses fluxos de dados com o código usado nos SDKs do Columnar, as empresas podem otimizar sua estratégia de segmentação de anúncios, fornecendo anúncios personalizados com base nas interações mais recentes e nas preferências históricas do usuário - tudo processado rapidamente e em escala usando a arquitetura distribuída do Capella Columnar.
Os modelos de ciência de dados podem ser aplicados usando outras ferramentas para encontrar tendências e criar resultados analíticos que geram experiências adequadas para o usuário final. Isso permite a entrega de anúncios relevantes em tempo hábil, maximizando o envolvimento e as taxas de conversão por meio de aplicativos criados com base nos SDKs.
Processamento de dados em lote
Para cargas de trabalho de análise mais tradicionais em que os dados são processados em massa, o modo de consulta com buffer garante o uso eficiente da memória ao carregar conjuntos de dados na memória. Casos de uso como Processos de ETL, inteligência de negóciose armazenamento de dados podem se beneficiar desse recurso. Usando o poder do SQL++, as ferramentas de BI podem extrair informações de alto valor rapidamente, sem a necessidade de contar com tantas ferramentas analíticas de terceiros.
Operações de dados entre idiomas
O API unificada permite que as equipes de desenvolvimento alternem facilmente entre linguagens de programação sem a necessidade de aprender novos padrões. Isso é particularmente útil para equipes que trabalham com arquiteturas de microsserviçosonde diferentes componentes podem ser escritos em diferentes linguagens (por exemplo, Java para serviços de backend, Node.js para APIs em tempo real).
Visão geral técnica: introdução
Para que você tenha uma ideia de como é fácil começar a usar todos os SDKs do Capella Columnar, aqui está um exemplo de conexão com um cluster do Capella Columnar usando o SDK do PythonVeja os documentos para Java e Node.js exemplos:

Figura 3. Exemplo de código de gerenciamento de conexão em Python
O processo é semelhante em todos os SDKsgarantindo uma experiência consistente, independentemente do idioma. Uma vez conectado, você pode executar consultas SQL, gerenciar escopos e trabalhar com coleções.
Execução assíncrona de consultas
O Python SDK oferece suporte às APIs de streaming sincronizado e assíncrono. Os aplicativos que precisam de operações sem bloqueio também podem realizar consultas assíncronas usando a API asyncio estrutura. Isso permite que você execute consultas sem esperar que elas terminem, aumentando a taxa de transferência, especialmente ao lidar com grandes conjuntos de dados ou operações lentas. Esse exemplo também mostra o acesso a dados em buffer versus streaming.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from acouchbase_columnar import get_event_loop from acouchbase_columnar.cluster import AsyncCluster query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM `travel-sample`.inventory.route GROUP BY airline ORDER BY route_count DESC """ res = await cluster.execute_query(query) # Buffered: Execute a query and buffer all result rows in client memory. all_rows = await res.get_all_rows() # NOTE: all_rows is a list, _do not_ use `async for` for row in all_rows: print(f'Found row: {row}') # Streaming: Execute a query and process rows as they arrive from server. res = await cluster.execute_query(statement) async for row in res.rows(): print(f'Found row: {row}') |
Neste exemplo, o asyncio O loop de eventos é usado para tratar as consultas de forma assíncrona, permitindo que o aplicativo execute outras tarefas enquanto aguarda os resultados da consulta.
Consultas parametrizadas
As consultas parametrizadas ajudam a proteger seu aplicativo contra Ataques de injeção de SQL separando a lógica de consulta das entradas de dados. Isso é especialmente importante ao lidar com dados fornecidos pelo usuário.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Positional Parameters query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$1 AND distance>=$2 GROUP BY airline ORDER BY route_count DESC """ res = scope.execute_query(query, QueryOptions(positional_parameters=['SFO', 1000])) # Named Parameters query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$source_airport AND distance>=$min_distance GROUP BY airline ORDER BY route_count DESC """ res = scope.execute_query(query, QueryOptions(named_parameters={'source_airport': 'SFO', 'min_distance': 1000})) |
Neste exemplo, passamos o código do aeroporto como um parâmetro, garantindo que a consulta permaneça segura e evitando os riscos associados à injeção de SQL.
Uso de resultados de consultas em bibliotecas de análise de dados
O Couchbase Columnar SDK se integra perfeitamente às bibliotecas populares de análise de dados Python, como Pandas e PyArrowAs ferramentas de análise de dados e IA/ML são ferramentas comuns escolhidas para projetos de ciência de dados e IA/ML, facilitando a incorporação de resultados de consultas em seu fluxo de trabalho de análise.
Importação de resultados de consultas para um DataFrame do Pandas
Este exemplo mostra como os resultados da consulta do Couchbase podem ser facilmente convertidos em Pandas DataFramespermitindo a manipulação e a exploração de dados.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd res = scope.execute_query(query) df = pd.DataFrame.from_records(res.rows(), index='airline') print(df.head()) # airline route_count avg_route_distance # AA 2354 2314.884359 # UA 2180 2350.365407 # DL 1981 2350.494112 # US 1960 2101.417609 # WN 1146 1397.736500 |
Importação de resultados de consulta para uma tabela PyArrow
Para tarefas de desempenho intenso, os resultados do Couchbase podem ser usados em Tabelas PyArrowfacilitando a análise na memória e a integração com sistemas de armazenamento em colunas.
|
1 2 3 4 5 6 7 8 9 10 |
import pyarrow as pa res = scope.execute_query(query) table = pa.Table.from_pylist(res.get_all_rows()) print(table.to_string()) # pyarrow.Table # route_count: int64 # avg_route_distance: double # airline: string |
Ao oferecer suporte às bibliotecas Pandas e PyArrow, o Couchbase Columnar Python SDK simplifica a integração aos pipelines existentes de ciência e análise de dados, permitindo a análise e o processamento eficientes dos dados.
Esses exemplos demonstram como executar consultas em buffer, de fluxo contínuo, assíncronas e parametrizadas usando os SDKs do Couchbase, permitindo que você adapte a execução da consulta aos requisitos do seu aplicativo.
Conclusão
Os SDKs do Capella Columnar são um complemento poderoso para os desenvolvedores que trabalham com análise de dados em grande escala. Com suporte robusto para várias linguagens, execução de consultas simplificada e compatibilidade entre plataformas, esses SDKs oferecem a flexibilidade, o desempenho e a confiabilidade necessários para lidar com cargas de trabalho de dados modernas. Não importa se você está processando fluxos de dados em tempo real ou executando consultas analíticas complexas, os SDKs do Capella Columnar foram projetados para aprimorar sua experiência de desenvolvimento.
Explore as possibilidades e comece a criar aplicativos mais inteligentes e rápidos com o Capella Columnar hoje mesmo!
Recursos
-
- Documentação e instruções de instalação: Python - Node.js - Java
- Saiba mais sobre Capella Columnar e seus casos de uso
- Comece a usar o Capella, gratuitamente, hoje mesmo: registrar-se