Criar uma arquitetura de Big Data não significa escolher entre NoSQL ou Hadoop. Em vez disso, trata-se de fazer com que o NoSQL e o Hadoop trabalhem juntos. O Hadoop foi projetado para cargas de trabalho analíticas em lote e de streaming. Os bancos de dados NoSQL são projetados para cargas de trabalho operacionais da Web, móveis e de IoT da empresa. O big data operacional nos bancos de dados NoSQL é o combustível para o Hadoop.
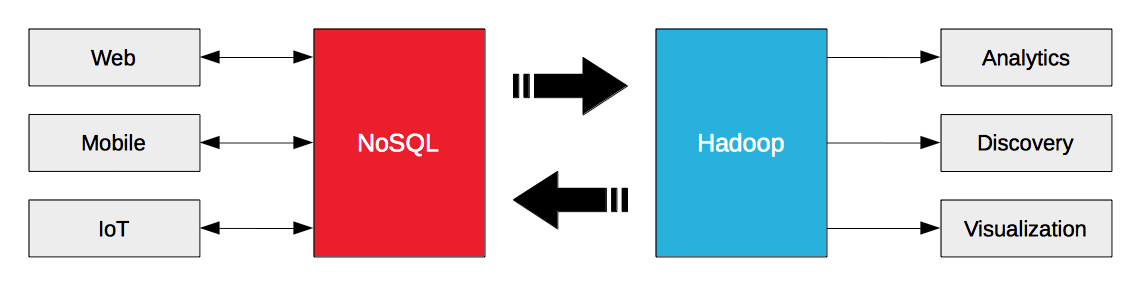
A chave para desbloquear o valor do big data operacional é simplificar o fluxo entre os bancos de dados NoSQL e o Hadoop, e é por isso que a Hortonworks e a Couchbase anunciaram hoje uma parceria estratégica. O Couchbase Server 3.0 introduziu o protocolo de alteração de banco de dados (DCP) para transmitir dados não apenas para destinos internos (por exemplo, nós / clusters), mas também para destinos externos (por exemplo, Hadoop). A Hortonworks Data Platform (HDP) 2.2 inclui não apenas o Sqoop para importação/exportação de dados, mas também o Kafka para mensagens de alta taxa de transferência e o Storm para processamento de fluxo.
O Couchbase Server pode transmitir dados para destinos externos. O HDP pode ingerir dados de fontes externas e processá-los como um fluxo. Esses recursos permitem que as empresas exportem e transmitir dados para o HDP a partir do Couchbase Server e vice-versa.
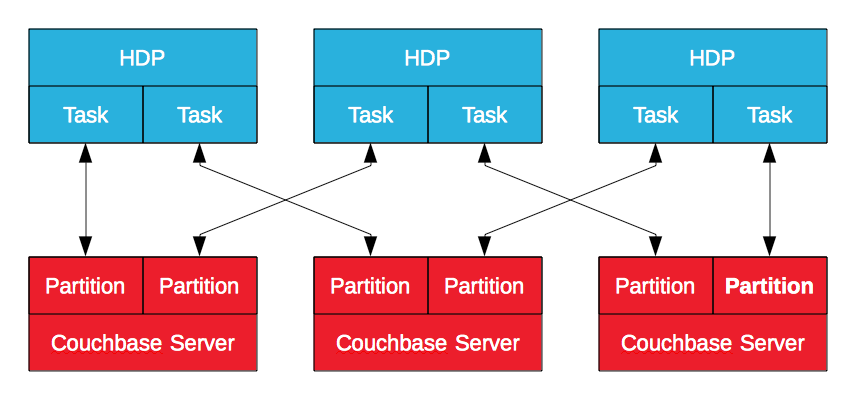
Conector do Hadoop do servidor Couchbase
O Couchbase Server Hadoop Connector, certificado pela Hortonworks, utiliza o MapReduce para exportar dados do Couchbase Server para o HDP e vice-versa. Os dados no Couchbase Server são armazenados em partições lógicas com nós que possuem um subconjunto delas. Criado com base no subprojeto Apache Sqoop, ele gerará um trabalho MapReduce no HDP para importar ou exportar dados do Couchbase Server. Isso permite que o Hadoop importe e exporte dados com várias tarefas, em paraleloconectando-se a vários nós do Couchbase Server. É um processo em lote, mas é eficaz, principalmente quando o objetivo é enriquecer e refinar os dados operacionais.
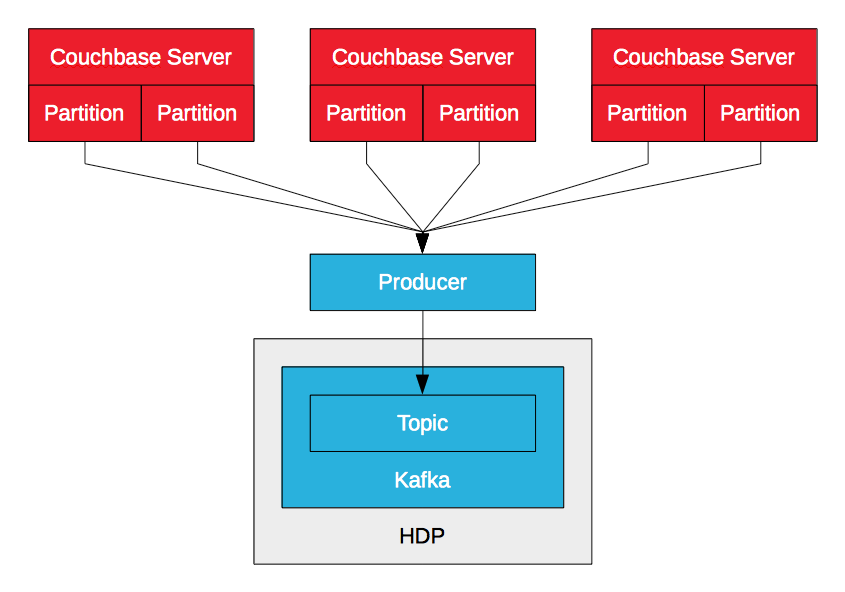
Produtor Kafka do servidor Couchbase
O produtor do Couchbase Server Kafka utiliza o DCP para transmitir mutações de dados (inserir, atualizar, excluir) em um Couchbase Server para um tópico do Kafka. O produtor recebe vários fluxos de vários nós, um por partição lógica, e os mescla. À medida que recebe as mutações, ele as envia para o tópico. Isso permite alta taxa de transferência e baixa latência na ingestão de dados no HDP via Kafka. Enquanto o Sqoop permite que as empresas importem dados do Couchbase Server por meio de lotes, o Kafka permite que elas importem dados por meio de fluxos. Os dados podem ser gravados no HDFS com o Camus do LinkedIn, por exemplo, ou consumidos pelo Storm ou Spark Streaming para processamento em tempo real.
O PayPal abriu um servidor Couchbase Kafka produtor para o Couchbase Server 2.5.
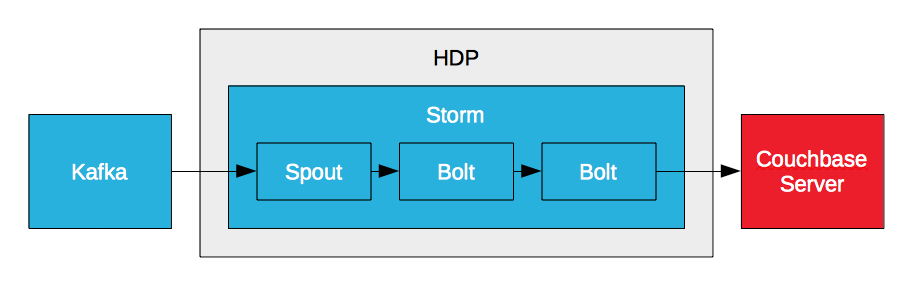
Servidor Couchbase Storm Bolt
O Storm pode processar um fluxo de dados em tempo real, mas não pode persistir os dados e não pode fornecer acesso a eles. No entanto, ele pode gravar dados no Couchbase Server por meio de um parafuso. O Storm requer um banco de dados de alto desempenho para atender aos requisitos de alta taxa de transferência e baixa latência. É por isso que empresas como o PayPal criam bolts do Couchbase Server. Isso permite que elas processem fluxos de dados em tempo real e gravem os dados processados no Couchbase Server. A chave para a análise em tempo real é a baixa latência. É a entrada de baixa latência, analisando os dados em movimento, e a saída de baixa latência, acessando os resultados para relatórios e visualização.
Parafuso de tempestade do servidor Couchbase (exemplo #1)
Parafuso de tempestade do servidor Couchbase (exemplo #2)
Big Data em tempo real
Empresas como o PayPal estão aproveitando o Kafka, o Storm e o Flume para criar soluções de big data em tempo real, simplificando o fluxo de dados entre Servidor Couchbase e distribuições do Hadoop, como o HDP. É o Couchbase Server, o Kafka, o Storm e o HDFS. É Kafka para Storm para HDFS e Couchbase Server. Depende de você. O HDP inclui todos os componentes necessários para suportar o fluxo de dados de e para o Couchbase Server. Como será sua arquitetura de Big Data em tempo real?
Mundo Strata+Hadoop
A Couchbase fará uma apresentação com o LinkedIn hoje sobre o Couchbase Server e o Kafka. Couchbase para Hadoop no Linkedin: Kafka está viabilizando o pipeline de Big Data
Recursos
Apresentação do PayPal no Couchbase Connect 2014
Central de Big Data