Building a big data architecture doesn’t mean choosing between NoSQL or Hadoop. Instead it’s about making NoSQL and Hadoop work together. Hadoop is engineered for batch and streaming analytical workloads. NoSQL databases are engineered for enterprise web, mobile, and IoT operational workloads. The operational big data in NoSQL databases is fuel for Hadoop.
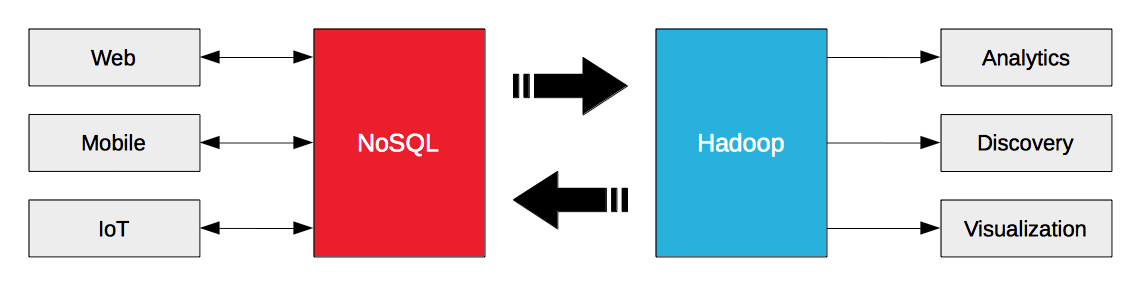
The key to unlocking the value of operational big data is streamlining the flow of it between NoSQL databases and Hadoop, and that’s why Hortonworks and Couchbase announced a strategic partnership today. Couchbase Server 3.0 introduced the database change protocol (DCP) to stream data not only to internal destinations (e.g. nodes / clusters), but also to external destinations (e.g. Hadoop). Hortonworks Data Platform (HDP) 2.2 includes not only Sqoop for data import / export, but Kafka for high throughput messaging and Storm for stream processing.
Couchbase Server can stream data to external destinations. HDP can ingest data from external sources, and process it as a stream. These capabilities enable enterprises to export and stream data to HDP from Couchbase Server and vice-versa.
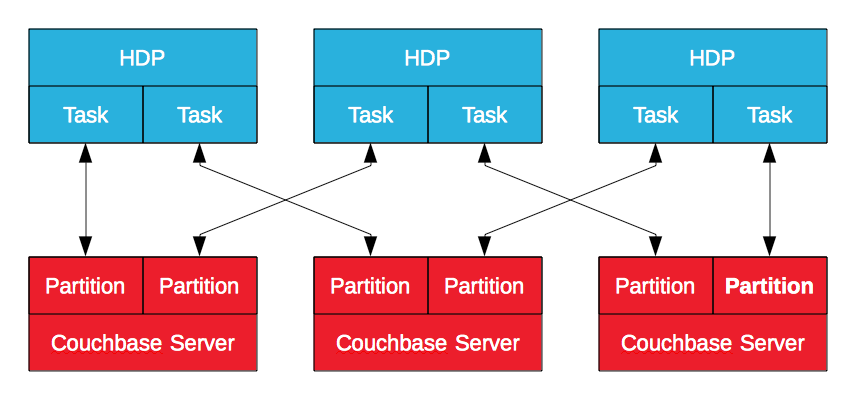
Couchbase Server Hadoop Connector
The Couchbase Server Hadoop Connector, certified by Hortonworks, leverages MapReduce to export data from Couchbase Server to HDP and vice-versa. The data in Couchbase Server is stored in logical partitions with nodes owning a subset of them. Built on the Apache Sqoop subproject, it will generate a MapReduce job in HDP to import data from or export data to Couchbase Server. This enables Hadoop to import and export data with multiple tasks, in parallel, by connecting to multiple Couchbase Server nodes. It’s a batch process, but it’s effective – particularly when the goal is to enrich and refine operational data.
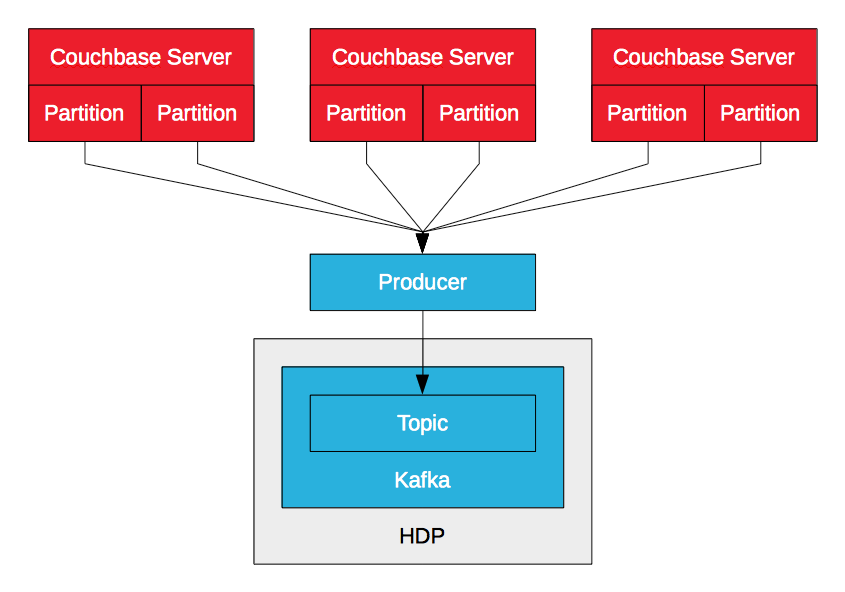
Couchbase Server Kafka Producer
The Couchbase Server Kafka producer leverages DCP to stream data mutations (insert, update, delete) in a Couchbase Server to a Kafka topic. The producer receives multiple streams from multiple nodes, one per logical partition, and merges them. As it receives mutations, it sends them to the topic. This enables high throughput, low latency ingestion of data into HDP via Kafka. Whereas Sqoop enables enterprises to import data from Couchbase Server via batches, Kafka enables them to import data via streams. The data can be written to HDFS with LinkedIn’s Camus, for example, or consumed by Storm or Spark Streaming for real-time processing.
PayPal open sourced a Couchbase Server Kafka producer for Couchbase Server 2.5.
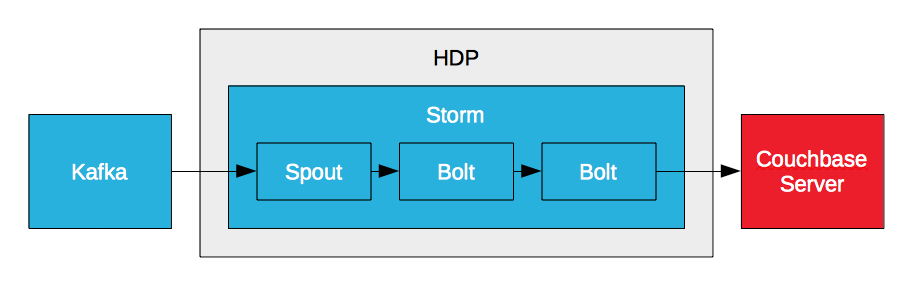
Couchbase Server Storm Bolt
Storm can process a stream of data in real time, but it can’t persist data and it can’t provide access to it. However, it can write data to Couchbase Server via a bolt. Storm requires a high performance database to meet high throughput, low latency requirements. That’s why enterprises like PayPal create Couchbase Server bolts. It enables them to process streams of data in real-time and write the processed data to Couchbase Server. The key to real-time analytics is low latency. It’s low latency input, analyzing data in motion, and low latency output, accessing the results for reporting and visualization.
Couchbase Server Storm Bolt (Example #1)
Couchbase Server Storm Bolt (Example #2)
Real-Time Big Data
Enterprises like PayPal are leveraging Kafka, Storm, and Flume to create real-time big data solutions by streamlining the flow of data between Couchbase Server and Hadoop distributions like HDP. It's Couchbase Server to Kafka to Storm to HDFS. It's Kafka to Storm to HDFS and Couchbase Server. It's up to you. HDP includes all of the components necessary to support the flow of data to and from Couchbase Server. What will your real-time big data architecture look like?
Strata+Hadoop World
Couchbase will be presenting with LinkedIn today on Couchbase Server and Kafka. Couchbase to Hadoop at Linkedin: Kafka is Enabling the Big Data Pipeline
Resources
PayPal Presentation at Couchbase Connect 2014
Big Data Central