Movimentação de dados entre fontes de dados. Essa é uma das principais atividades dos projetos de integração de dados. Tradicionalmente, as técnicas de movimentação de dados fazem parte de Armazém de dadosBI e análise. Mais recentemente, Big Data, Data Lakes, Hadoop, são participantes frequentes nessa área.
Neste post, discutiremos como a linguagem N1QL do Couchbase pode ser usada para fazer a manipulação maciça dos dados nesse tipo de cenário.
Primeiro, vamos nos lembrar das duas abordagens clássicas ao fazer a movimentação de dados:
ETL (Extrair-Transformar-Carregar). Com esse modelo, os dados são extraído (da fonte de dados original), transformado (os dados são reformatados para caber no sistema de destino) e carregado (no armazenamento de dados de destino).
ELT (Extrair- Carregar-Transformar). Com esse modelo, os dados são extraído (da fonte de dados original), carregado no mesmo formato no sistema de destino. Em seguida, fazemos um transformação no sistema de destino para obter o formato de dados desejado.
Vamos nos concentrar em um ELT neste exemplo. Vamos fazer uma exportação simples de um banco de dados relacional e carregar os dados no Couchbase. Usaremos o Oracle Database como fonte de dados de entrada, com o exemplo clássico de esquema de RH incorporado, que modela um departamento de Recursos Humanos.
Esse é o modelo de dados de origem:
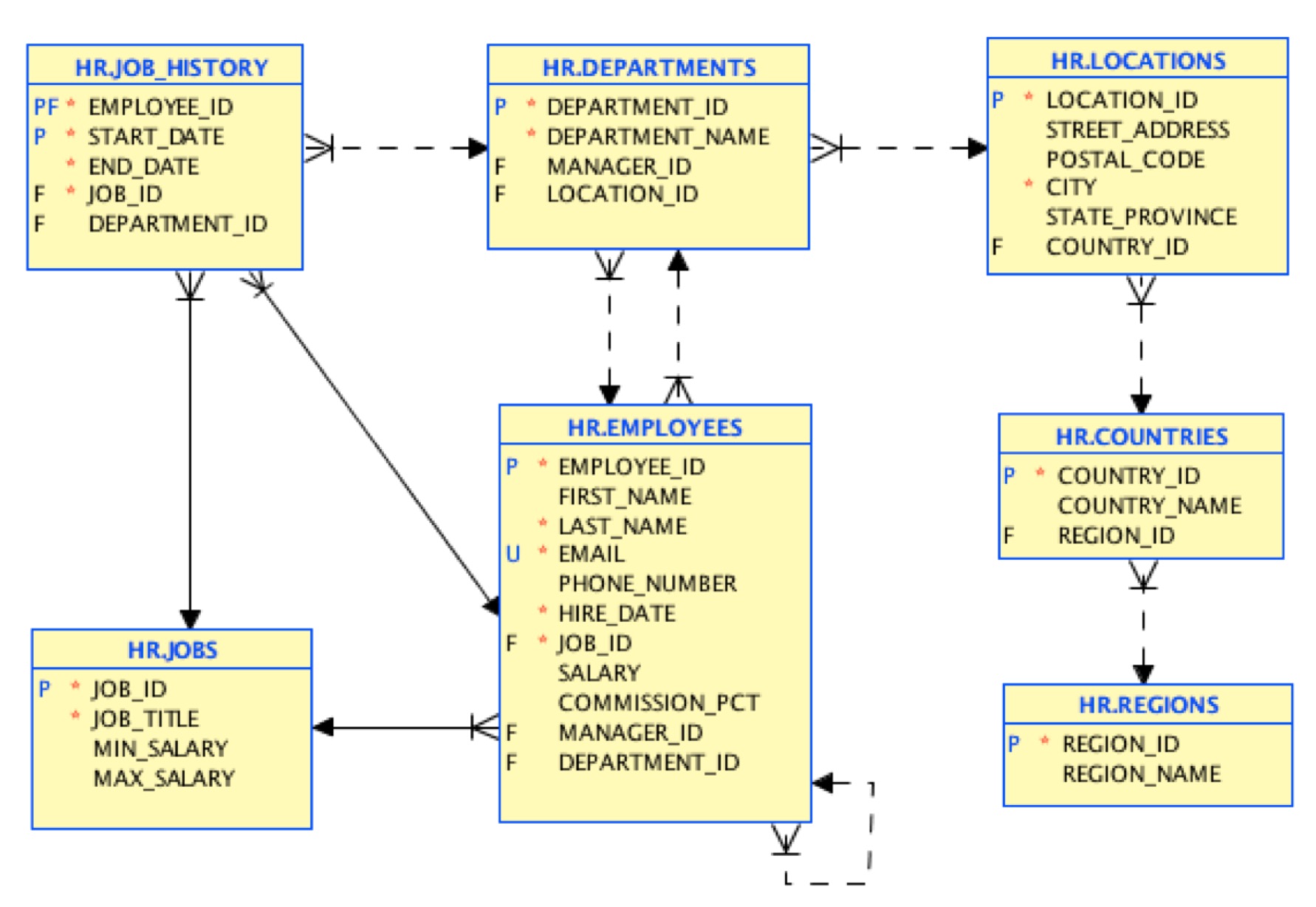
Na primeira etapa, carregaremos os dados com a mesma estrutura. Há uma ferramenta gratuita que você pode usar para realizar essa migração inicial aqui. No final, teremos documentos JSON mapeando esse modelo de tabela:
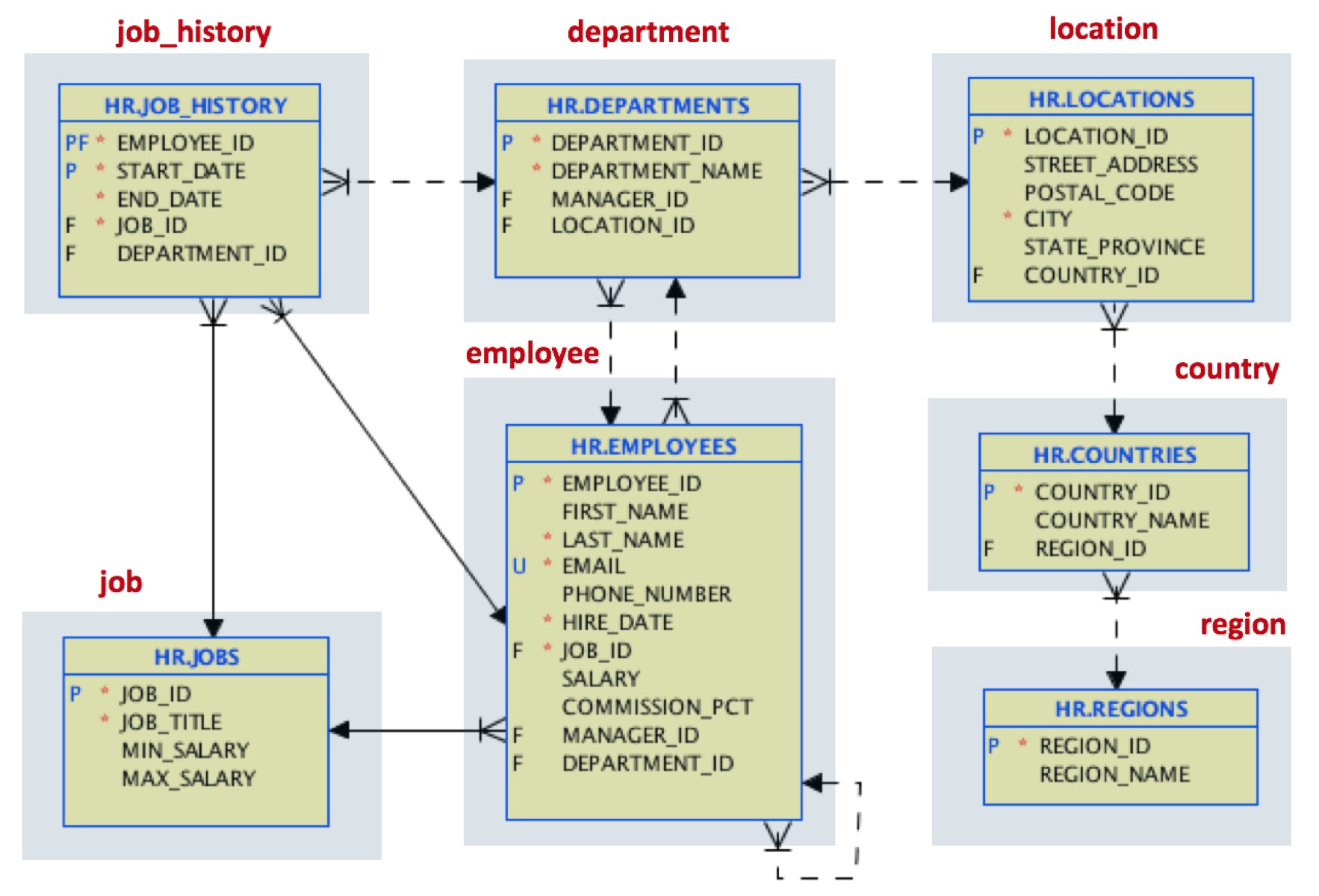
Por exemplo, um documento de localização terá a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 |
{ "street_address": "2017 Shinjuku-ku", "cidade": "Tóquio", "state_province": "Tokyo Prefecture" (Prefeitura de Tóquio), "postal_code": "1689", "tipo": "locais", "location_id": 1200, "country_id": "JP" } |
Essa foi uma primeira etapa fácil. No entanto, esse mapeamento de tabela para documento costuma ser um projeto ruim no mundo NoSQL. No NoSQL, é comum a desnormalização dos dados em favor de um caminho de acesso mais direto, incorporando dados referenciados. O objetivo é minimizar as interações e junções do banco de dados, buscando o melhor desempenho.
Vamos supor que nosso caso de uso seja motivado por um acesso frequente a todo o histórico de trabalho dos funcionários. Decidimos mudar nosso projeto para esse:
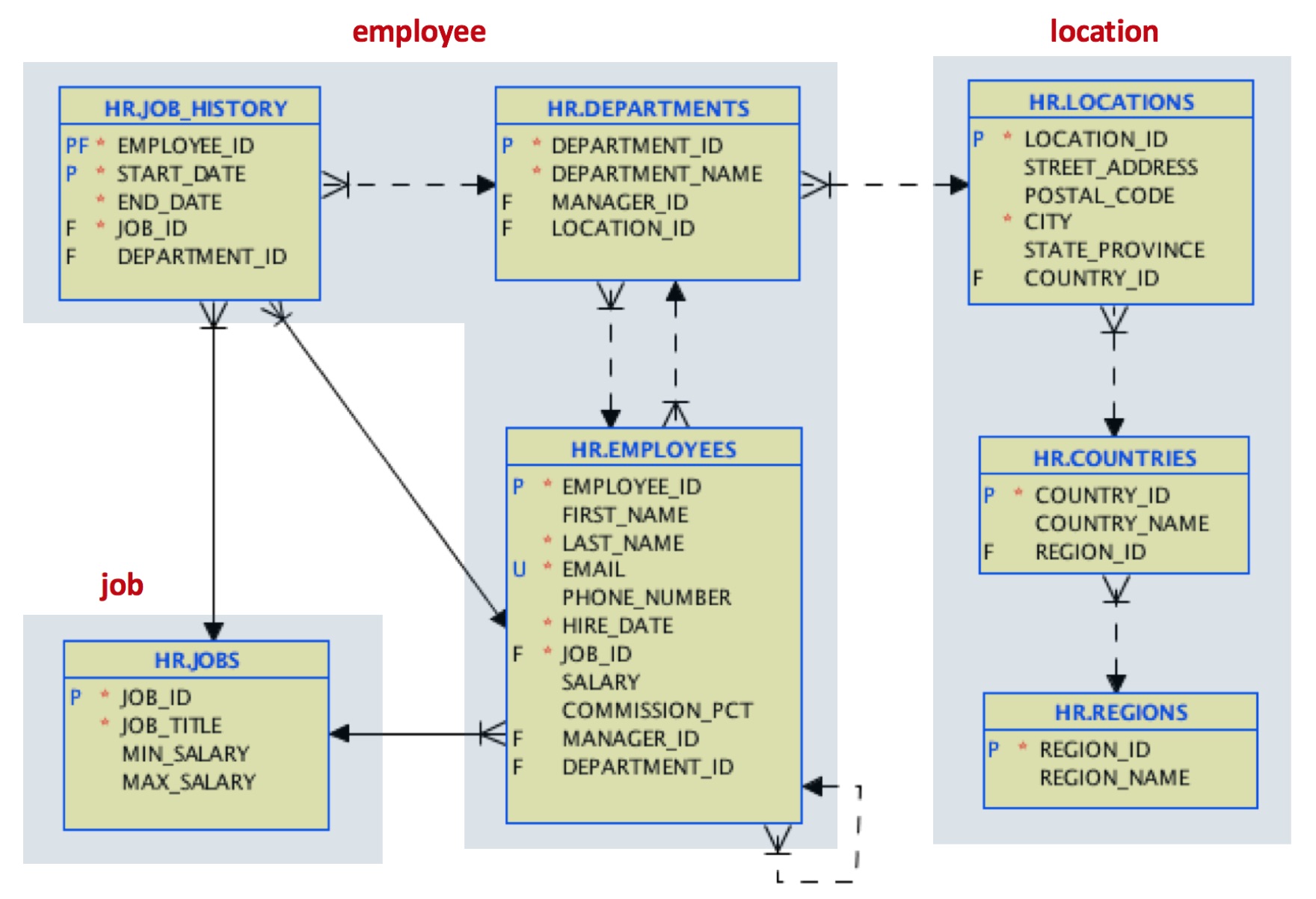
Para locais, estamos unindo em um único documento de local os dados referenciados para país e região.
Para o documento do funcionário, incorporaremos os dados do departamento e incluiremos uma matriz com todo o histórico de trabalho de cada funcionário. Esse suporte de matriz em JSON é uma boa melhoria em relação às referências de chave estrangeira e junções no mundo relacional.
Para o documento de trabalho, manteremos a estrutura original da tabela.
Portanto, temos extraído e carregado os dados, agora vamos transformar nesse modelo para concluir nosso ELT exemplo. Como podemos fazer esse trabalho? Chegou a hora do N1QL
N1QL é a linguagem semelhante ao SQL incluída no Couchbase para acesso e manipulação de dados. Neste exemplo, usaremos dois buckets: HR, que mapeia o esquema original de RH da Oracle, e HR_DNORM, que manterá nosso modelo de documento de destino.
Já carregamos nosso esquema de RH. A próxima etapa é criar um compartimento chamado HR_DNORM. Em seguida, criaremos um índice primário nesse novo bucket:
|
1 |
CRIAR PRIMÁRIO ÍNDICE ON HR_DNORM |
Agora é hora de criar os documentos de localização. Esses documentos são compostos de locais originais, documentos de país e região:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
INSERIR PARA HR_DNORM (chave _k, valor _v) SELECIONAR meta().id _k, { "tipo":"localização", "cidade":local.cidade, "postal_code":local.código postal, "state_province":IFNULL(local.estado_província, nulo), "street_address":local.street_address, "country_name":ct.nome_do_país, "nome_da_região":rg.região_nome } como _v DE RH local JUNTAR RH ct ON CHAVES "países::" || local.country_id JUNTAR RH rg ON CHAVES "regions::" || TO_STRING(ct.region_id) ONDE local.tipo="locais" |
Alguns aspectos a serem observados:
- Estamos usando aqui a projeção de uma instrução SELECT para fazer a inserção. Neste exemplo, os dados originais vêm de um bucket diferente.
- JOINs são usados no bucket original para fazer referência a países e regiões
- Função IFNULL usada para definir explicitamente um valor nulo para o campo state_province
- Função TO_STRING aplicada em um campo numérico para fazer referência a uma chave
Nossa amostra original é a seguinte:
|
1 2 3 4 5 6 7 8 9 |
{ "cidade": "Tóquio", "country_name": "Japão", "postal_code": "1689", "nome_da_região": "Ásia", "state_province": "Tokyo Prefecture" (Prefeitura de Tóquio), "street_address": "2017 Shinjuku-ku", "tipo": "localização" } |
Observe que nos livramos de nossas referências location_id e country_id.
Agora é hora de preparar os documentos de nossos funcionários. Faremos isso em várias etapas. A primeira é criar os funcionários a partir do bucket de RH original, incluindo informações sobre o departamento e o cargo real:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
INSERIR PARA HR_DNORM (chave _k, valor _v) SELECIONAR meta().id _k, { "tipo":"funcionários", "employee_id": emp. ID do funcionário, "first_name": emp.primeiro_nome, "last_name": emp.sobrenome, "phone_number" (número de telefone): emp.número de telefone, "email": emp.e-mail, "hire_date": emp.data_de_contratação, "salário": emp.salário, "commission_pct": IFNULL(emp.comissão_pct, nulo), "manager_id": IFNULL(emp.manager_id, nulo), "job_id": emp.job_id, "job_title": trabalho.título do cargo, "departamento" : { "name" (nome) : dpt.nome_do_departamento, "manager_id" : dpt.manager_id, "department_id" : dpt.departamento_id } } como _v DE RH emp JUNTAR RH trabalho ON CHAVES "jobs::" || emp.job_id JUNTAR RH dpt ON CHAVES "departamentos::" || TO_STRING(emp.department_id) ONDE emp.tipo="funcionários" RETORNO META().id; |
Em segundo lugar, usaremos uma construção temporária para criar a matriz de histórico de trabalho:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
INSERIR PARA HR_DNORM (chave _k, valor histórico de trabalho) SELECIONAR "job_history::" || TO_STRING(trabalho.ID do funcionário) AS _k, { "empregos" : ARRAY_AGG( { "start_date": trabalho.data_inicial, "end_date" (data final): trabalho.data_final, "job_id": trabalho.job_id, "department_id": trabalho.departamento_id } ) } AS histórico de trabalho DE RH trabalho ONDE trabalho.tipo="job_history" GRUPO BY trabalho.ID do funcionário RETORNO META().id; |
Agora é fácil atualizar os documentos de nossos funcionários adicionando uma matriz job_history:
|
1 2 3 4 5 6 7 8 9 |
ATUALIZAÇÃO HR_DNORM emp CONJUNTO histórico de trabalho=( SELECIONAR RAW empregos DE HR_DNORM trabalho USO CHAVES "job_history::" || SUBSTR(meta(emp).id, 11) )[0] ONDE emp.tipo="funcionários" RETORNO meta().id |
Este é o aspecto do nosso documento de funcionário:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
{ "commission_pct": nulo, "departamento": { "department_id": 10, "manager_id": 200, "name" (nome): "Administração" }, "email": "JWHALEN", "employee_id": 200, "first_name": "Jennifer", "hire_date": "2003-09-16T22:00:00Z", "job_history": [ { "department_id": 80, "end_date" (data final): "2007-12-31T23:00:00Z", "job_id": "SA_REP", "start_date": "2006-12-31T23:00:00Z" }, { "department_id": 90, "end_date" (data final): "2001-06-16T22:00:00Z", "job_id": "AD_ASST", "start_date": "1995-09-16T22:00:00Z" }, { "department_id": 90, "end_date" (data final): "2006-12-30T23:00:00Z", "job_id": "AC_ACCOUNT", "start_date": "2002-06-30T22:00:00Z" } ], "job_id": "AD_ASST", "job_title": "Assistente de administração", "last_name": "Whalen", "manager_id": 101, "phone_number" (número de telefone): "515.123.4444", "salário": 4400, "tipo": "funcionários" } |
Observe a matriz job_history de posições anteriores.
Podemos excluir agora os documentos temporários job_history:
|
1 2 |
DELETE DE HR_DNORM emp ONDE meta().id GOSTO "job_history::%" |
Como última etapa, inserimos os documentos originais dos trabalhos:
|
1 2 3 4 |
INSERIR PARA HR_DNORM (chave _k, valor _v) SELECIONAR meta().id _k, _v DE RH _v ONDE _v.tipo="empregos" |
Estamos prontos. Este é um exemplo simples, mas mostra o quão poderosa pode ser a manipulação de dados N1QL. Boa migração de dados!