Mover datos entre fuentes de datos. Se trata de una de las actividades clave en los proyectos de integración de datos. Tradicionalmente, las técnicas en torno al movimiento de datos han formado parte de Almacén de datosBI y análisis. Más recientemente, Big Data, Data Lakes, Hadoop, son actores frecuentes en este ámbito.
En esta entrada, discutiremos cómo el lenguaje N1QL de Couchbase puede ser usado para hacer manipulación masiva sobre los datos en este tipo de escenarios.
En primer lugar, recordemos los dos enfoques clásicos a la hora de realizar el movimiento de datos:
ETL (Extraer-Transformar-Cargar). Con este modelo los datos son extraído (de la fuente de datos original), transformado (los datos se reformatean para ajustarse al sistema de destino) y cargado (en el almacén de datos de destino).
ELT (Extraer-Cargar-Transformar). Con este modelo los datos son extraído (de la fuente de datos original), cargado en el mismo formato en el sistema de destino. A continuación, hacemos un transformación en el sistema de destino para obtener el formato de datos deseado.
Nos centraremos en un ELT en este ejemplo. Hagamos una simple exportación desde una base de datos relacional, y carguemos los datos en Couchbase. Utilizaremos Oracle Database como fuente de datos de entrada, con el clásico ejemplo de esquema HR incorporado, que modela un departamento de Recursos Humanos.
Este es el modelo de datos de origen:
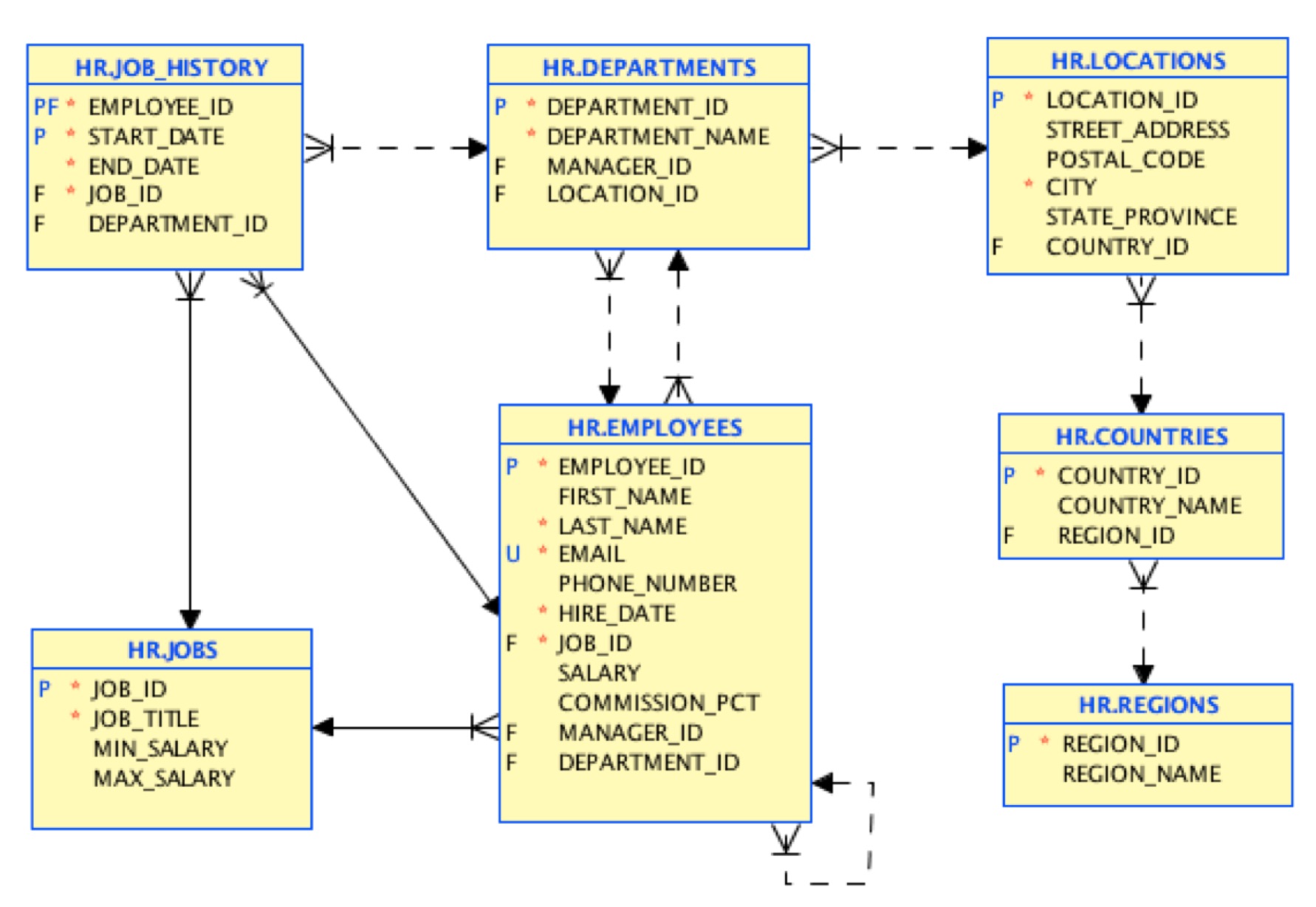
En el primer paso, cargaremos los datos con la misma estructura. Existe una herramienta gratuita que puedes utilizar para realizar esta migración inicial aquí. Al final, tendremos documentos JSON mapeando este modelo de tabla:
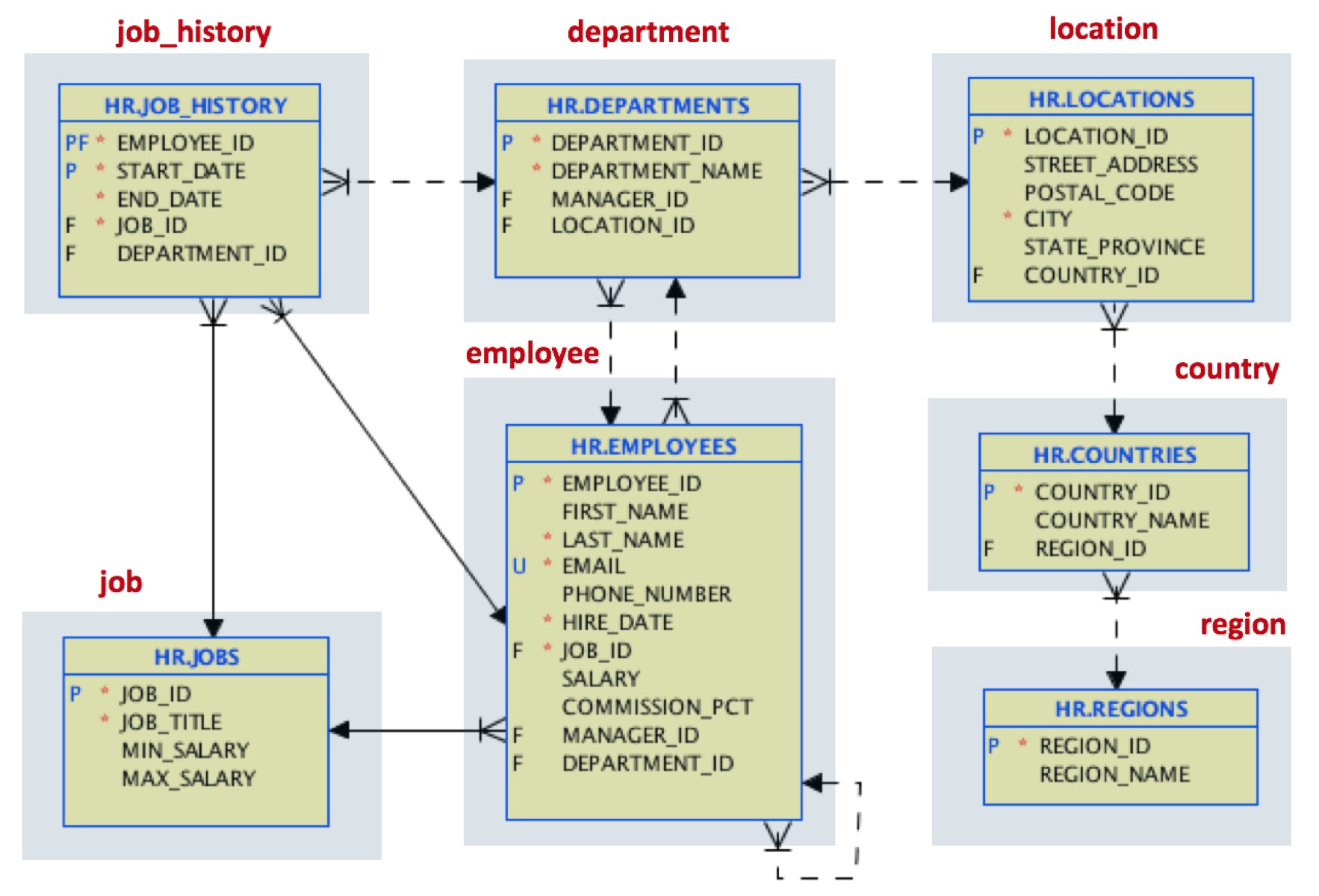
Por ejemplo, un documento de localización tendrá el siguiente aspecto:
|
1 2 3 4 5 6 7 8 9 10 |
{ "dirección_calle": "2017 Shinjuku-ku", "ciudad": "Tokio", "estado_provincia": "Prefectura de Tokio", "código_postal": "1689", "tipo": "localizaciones", "location_id": 1200, "country_id": "JP" } |
Este fue un primer paso fácil. Sin embargo, este mapeo de tabla a documento suele ser un mal diseño en el mundo NoSQL. En NoSQL es frecuente desnormalizar los datos en favor de una vía de acceso más directa, incrustando los datos referenciados. El objetivo es minimizar las interacciones con la base de datos y las uniones, buscando el mejor rendimiento.
Supongamos que nuestro caso de uso está motivado por un acceso frecuente a todo el historial laboral de los empleados. Decidimos cambiar nuestro diseño por éste:
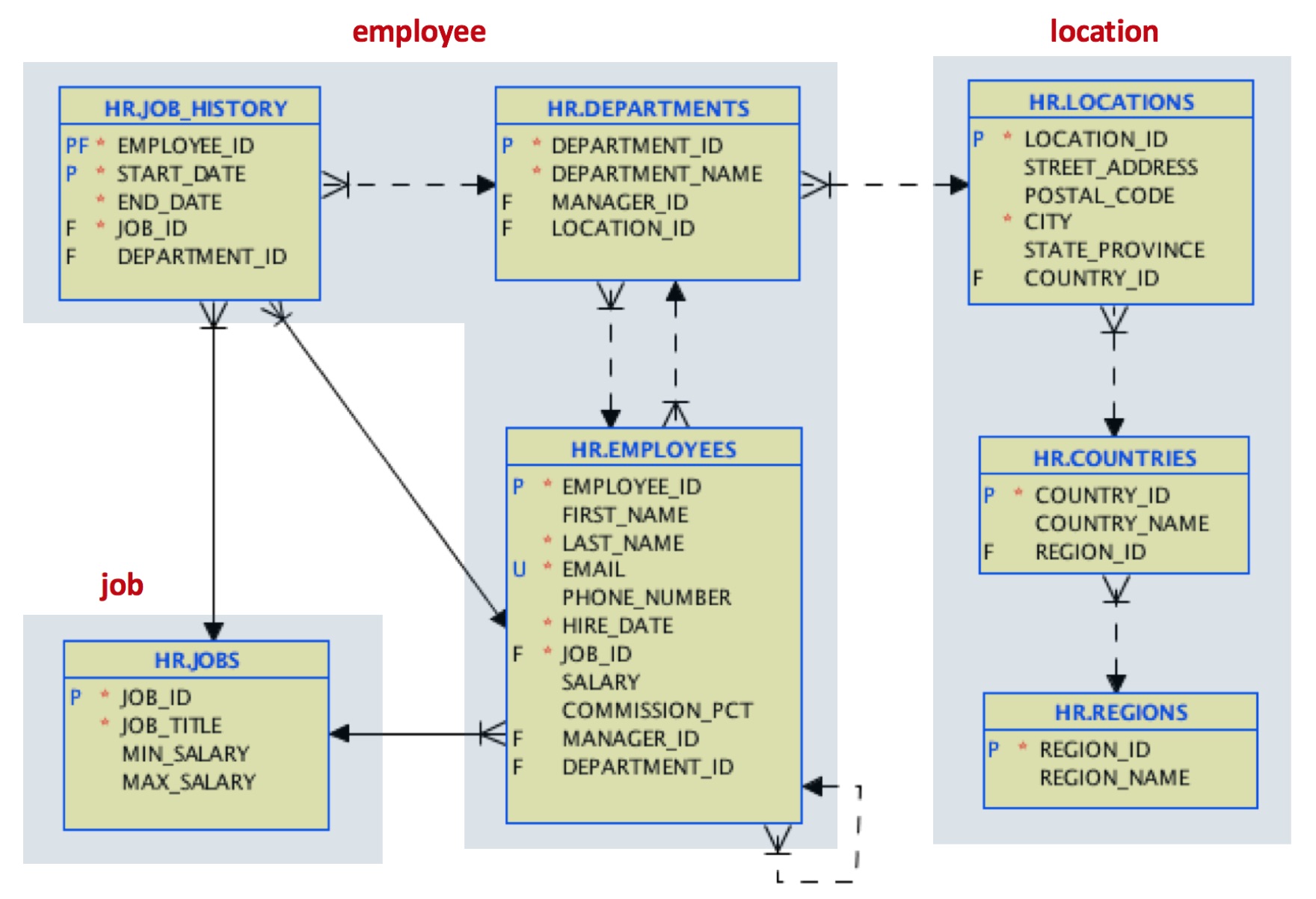
Para las localizaciones, unimos en un único documento de localización los datos referenciados para el país y la región.
Para el documento del empleado, incrustaremos los datos del departamento, e incluiremos un array con todo el historial laboral de cada empleado. Este soporte de matrices en JSON es una buena mejora respecto a las referencias de clave foránea y las uniones en el mundo relacional.
Para el documento de trabajo, mantendremos la estructura de tablas original.
Así que tenemos extraído y cargado los datos, ahora vamos a transformar en este modelo para terminar nuestro ELT ejemplo. ¿Cómo podemos hacer este trabajo? Es hora de N1QL
N1QL es el lenguaje tipo SQL incluido con Couchbase para el acceso y manipulación de datos. En este ejemplo, utilizaremos dos buckets: HR, que corresponde al esquema original de Oracle HR, y HR_DNORM, que contendrá nuestro modelo de documento de destino.
Ya hemos cargado nuestro esquema HR. El siguiente paso es crear un bucket llamado HR_DNORM. Luego crearemos un índice primario en este nuevo bucket:
|
1 |
CREAR PRIMARIO ÍNDICE EN HR_DNORM |
Ahora es el momento de crear los documentos de localización. Estos documentos se componen de ubicaciones originales, documentos de país y documentos de región:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
INSERTAR EN HR_DNORM (clave _k, valor _v) SELECCIONE meta().id _k, { "tipo":"localización", "ciudad":loc.ciudad, "código_postal":loc.código_postal, "estado_provincia":IFNULL(loc.provincia, null), "dirección_calle":loc.dirección, "nombre_país":ct.nombre_país, "nombre_región":rg.región_nombre } como _v DESDE RRHH loc ÚNASE A RRHH ct EN TECLAS "países::" || loc.country_id ÚNASE A RRHH rg EN TECLAS "regiones::" || TO_STRING(ct.región_id) DONDE loc.tipo="localizaciones" |
Algunas cosas a tener en cuenta:
- Aquí estamos utilizando la proyección de una sentencia SELECT para realizar la inserción. En este ejemplo, los datos originales proceden de un bucket diferente.
- Los JOIN se utilizan en el cubo original para hacer referencia a países y regiones
- Función IFNULL utilizada para establecer explícitamente un valor nulo para el campo state_province
- Función TO_STRING aplicada a un campo numérico para hacer referencia a una clave
Nuestra muestra original se convierte en esto:
|
1 2 3 4 5 6 7 8 9 |
{ "ciudad": "Tokio", "nombre_país": "Japón", "código_postal": "1689", "nombre_región": "Asia", "estado_provincia": "Prefectura de Tokio", "dirección_calle": "2017 Shinjuku-ku", "tipo": "localización" } |
Ten en cuenta que hemos eliminado las referencias location_id y country_id.
Ahora es el momento de nuestros documentos de empleado. Lo haremos en varios pasos. El primero es crear los empleados a partir del cubo original de RRHH, incluyendo la información del departamento y del puesto real:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
INSERTAR EN HR_DNORM (clave _k, valor _v) SELECCIONE meta().id _k, { "tipo":"empleados", "employee_id": emp. empleado_id, "nombre": emp.nombre, "apellido": emp.apellido, "número_teléfono": emp.número_teléfono, "email": emp.correo electrónico, "fecha_contratación": emp.fecha_contratación, "salario": emp.salario, "commission_pct": IFNULL(emp.comisión_pct, null), "manager_id": IFNULL(emp.manager_id, null), "job_id": emp.job_id, "job_title": empleo.cargo, "departamento" : { "nombre" : dpt.nombre_departamento, "manager_id" : dpt.manager_id, "department_id" : dpt.departamento_id } } como _v DESDE RRHH emp ÚNASE A RRHH empleo EN TECLAS "empleos::" || emp.job_id ÚNASE A RRHH dpt EN TECLAS "departamentos::" || TO_STRING(emp.departamento_id) DONDE emp.tipo="empleados" DEVOLVER META().id; |
En segundo lugar, utilizaremos una construcción temporal para construir la matriz del historial de trabajos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
INSERTAR EN HR_DNORM (clave _k, valor historial_trabajo) SELECCIONE "job_history::" || TO_STRING(jobh.empleado_id) AS _k, { "empleos" : ARRAY_AGG( { "fecha_inicio": jobh.fecha_inicio, "fecha_final": jobh.fecha_final, "job_id": jobh.job_id, "department_id": jobh.departamento_id } ) } AS historial_trabajo DESDE RRHH jobh DONDE jobh.tipo="job_history" GRUPO POR jobh.empleado_id DEVOLVER META().id; |
Ahora es fácil actualizar los documentos de nuestros empleados añadiendo un array job_history:
|
1 2 3 4 5 6 7 8 9 |
ACTUALIZACIÓN HR_DNORM emp SET historial_trabajo=( SELECCIONE RAW puestos de trabajo DESDE HR_DNORM jobh UTILICE TECLAS "job_history::" || SUBSTR(meta(emp).id, 11) )[0] DONDE emp.tipo="empleados" DEVOLVER meta().id |
Este es el aspecto de nuestro documento de empleado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
{ "commission_pct": null, "departamento": { "department_id": 10, "manager_id": 200, "nombre": "Administración" }, "email": "JWHALEN", "employee_id": 200, "nombre": "Jennifer", "fecha_contratación": "2003-09-16T22:00:00Z", "job_history": [ { "department_id": 80, "fecha_final": "2007-12-31T23:00:00Z", "job_id": "SA_REP", "fecha_inicio": "2006-12-31T23:00:00Z" }, { "department_id": 90, "fecha_final": "2001-06-16T22:00:00Z", "job_id": "AD_ASST", "fecha_inicio": "1995-09-16T22:00:00Z" }, { "department_id": 90, "fecha_final": "2006-12-30T23:00:00Z", "job_id": "AC_ACCOUNT", "fecha_inicio": "2002-06-30T22:00:00Z" } ], "job_id": "AD_ASST", "job_title": "Auxiliar de administración", "apellido": "Whalen", "manager_id": 101, "número_teléfono": "515.123.4444", "salario": 4400, "tipo": "empleados" } |
Observe la matriz job_history de puestos anteriores.
Ahora podemos eliminar los documentos temporales de job_history:
|
1 2 |
BORRAR DESDE HR_DNORM emp DONDE meta().id COMO "job_history::%" |
Como último paso insertamos los documentos originales de los trabajos:
|
1 2 3 4 |
INSERTAR EN HR_DNORM (clave _k, valor _v) SELECCIONE meta().id _k, _v DESDE RRHH _v DONDE _v.tipo="empleos" |
Hemos terminado. Este es un ejemplo simple, pero muestra lo poderosa que puede ser la manipulación de datos N1QL. ¡Feliz migración de datos!