Quando se trata de aprendizado de máquina, muito é já foi dito e escrito sobre o treinamento de seus modelos de ML. Mas de igual importância é onde você armazena esses modelos quando estiver pronto para fornecer previsões em tempo real.
Na semana passada, analisamos Cinco casos de uso para usar o Couchbase com seu sistema de fornecimento de previsões em tempo real. Exploramos como o Couchbase é usado para armazenar entradas ou recursos que são posteriormente passados para os modelos de aprendizado de máquina (ML), metadados de modelos e as próprias previsões.
Neste artigo, exploraremos como usar o Couchbase Server para armazenar modelos de ML treinados.
Aprendizado de máquina on-line e a necessidade de um armazenamento rápido de modelos
Tradicionalmente, um modelo de aprendizado de máquina é treinado off-line em grandes quantidades de dados históricos e, em seguida, implantado na produção para fornecer previsões.
Entretanto, o treinamento off-line nem sempre é possível. Por exemplo, às vezes, pequenas empresas iniciantes podem não ter acesso a grandes quantidades de dados de treinamento. Esse também pode ser o caso de empresas estabelecidas em que uma equipe está iniciando um novo caso de uso de ML que não tem dados de treinamento suficientes. Como resultado, a espera pela disponibilidade de dados de treinamento suficientes afeta o tempo de comercialização do seu produto.
Para resolver esse problema, algumas empresas usam aprendizado de máquina on-line. Nessa abordagem, as empresas treinam um modelo inicial usando pequenas quantidades de dados, implantam-no na produção e, em seguida, treinam-no novamente de forma incremental à medida que mais dados ficam disponíveis. Uma empresa pode precisar implantar milhares desses modelos na produção, cada um lidando com um caso de uso diferente.
Com o aprendizado de máquina on-line, os modelos podem precisar ser atualizados com muita frequência. Ao mesmo tempo, as previsões continuam a ser fornecidas usando os modelos recém-atualizados. É necessário um armazenamento de dados de alta taxa de transferência e baixa latência de leitura e gravação para armazenar os modelos de ML.
Armazenamento de modelos de aprendizado de máquina no Couchbase
A plataforma de dados Couchbase satisfaz os requisitos de desempenho do aprendizado de máquina on-line. Sua arquitetura que prioriza a memória - com cache de documentos integrado - oferece alta taxa de transferência sustentada e latência consistente abaixo de milissegundos.
Servidor Couchbase armazena qualquer um de seus modelos de ML, em formato binário ou JSON, com até 20 MB de tamanho (ou seja, o limite de documentos do Couchbase). Seus modelos são armazenados em buckets (ou "Collections") do Couchbase e você os acessa como qualquer outro dado armazenado no Couchbase. Isso facilita o gerenciamento do ciclo de vida dos modelos de ML, pois os modelos são atualizados com uma simples atualização de valor-chave.
Formatos de modelo binário vs. JSON
Uma vantagem de armazenar o modelo de ML em formato binário é que você não precisa converter de JSON para binário no momento de fazer as previsões. Os modelos binários também são menores em tamanho.
No entanto, o armazenamento do modelo no formato JSON permite que os usuários examinem o modelo por meio de várias interfaces do Couchbase. Isso pode ser útil para os usuários que se preocupam com a explicabilidade da IA e não querem que o modelo de ML seja uma caixa preta.
Outra vantagem de armazenar o modelo no formato JSON é que o Serviço de consulta do Couchbase ou Serviço de pesquisa de texto completo podem indexar e consultar o modelo. O Couchbase Data Platform inclui todos esses serviços e elimina a necessidade de produtos separados.
O Couchbase também atende a outros requisitos que um sistema de ML de produção exige de seu armazenamento de modelos, como alta disponibilidade, capacidade de escalonar dinamicamente com o aumento da carga de trabalho, acesso seguro aos dados e facilidade de gerenciamento.
Formatos de modelos ML e ONNX
Uma variedade de estruturas de ML, como scikit-learn e TensorFlow, está disponível para ajudar a treinar e implantar modelos. Em geral, os cientistas de dados criam modelos usando a estrutura e a linguagem com as quais estão mais familiarizados ou escolhem uma estrutura mais adequada para o treinamento de modelos.
Às vezes, o modelo é implantado na produção usando a mesma linguagem e estrutura que as usadas durante o treinamento. Essa abordagem proporciona facilidade de uso. Entretanto, a linguagem ou a estrutura que funciona melhor para o treinamento pode não ser a ideal para fazer previsões.
É comum que os usuários convertam o modelo treinado em uma estrutura diferente ou o reescrevam em uma linguagem diferente. Open Neural Network Exchange (ONNX) é um formato popular de intercâmbio de modelos usado para essa finalidade.
Os modelos treinados em uma variedade de estruturas populares podem ser convertidos em ONNX. Em seguida, você pode exportar o modelo ONNX para outra estrutura mais adequada à implementação. Ou pode manter o modelo no formato ONNX e implantá-lo em um dos tempos de execução compatíveis, como o tempo de execução ONNX de código aberto.
O tempo de execução do ONNX é compatível com Linux, Windows e Mac, com associações disponíveis para várias linguagens, como Python e Java. Por favor Consulte o tempo de execução do ONNX para obter mais detalhes.
Serialização e desserialização de modelos de ML
Os modelos treinados são normalmente serializado e salvo em algum formato em um arquivo e, em seguida desserializado para restaurá-los e carregá-los durante a implementação. Por exemplo, picles é um formato específico do Python que permite que um modelo do scikit-learn seja armazenado como um fluxo de bytes.
Vamos dar uma olhada em como um modelo de aprendizado de máquina pode ser treinado, serializado e armazenado no Couchbase e, em seguida, recuperado, desserializado e usado para fazer previsões.
Treinaremos um modelo (a classificador de máquina de vetor de suporte (SVM)) para prever o tipo de flor de íris com base nas dimensões de suas sépalas e pétalas. Usaremos o Conjunto de dados da íris para treinar o modelo usando a estrutura do scikit-learn. Esse conjunto de dados contém dimensões de sépalas e pétalas para três tipos diferentes de flores de íris, em um total de 150 linhas.
Usando o Couchbase como um armazenamento de modelos de ML: Formato binário
Fluxo de trabalho de treinamento e serialização
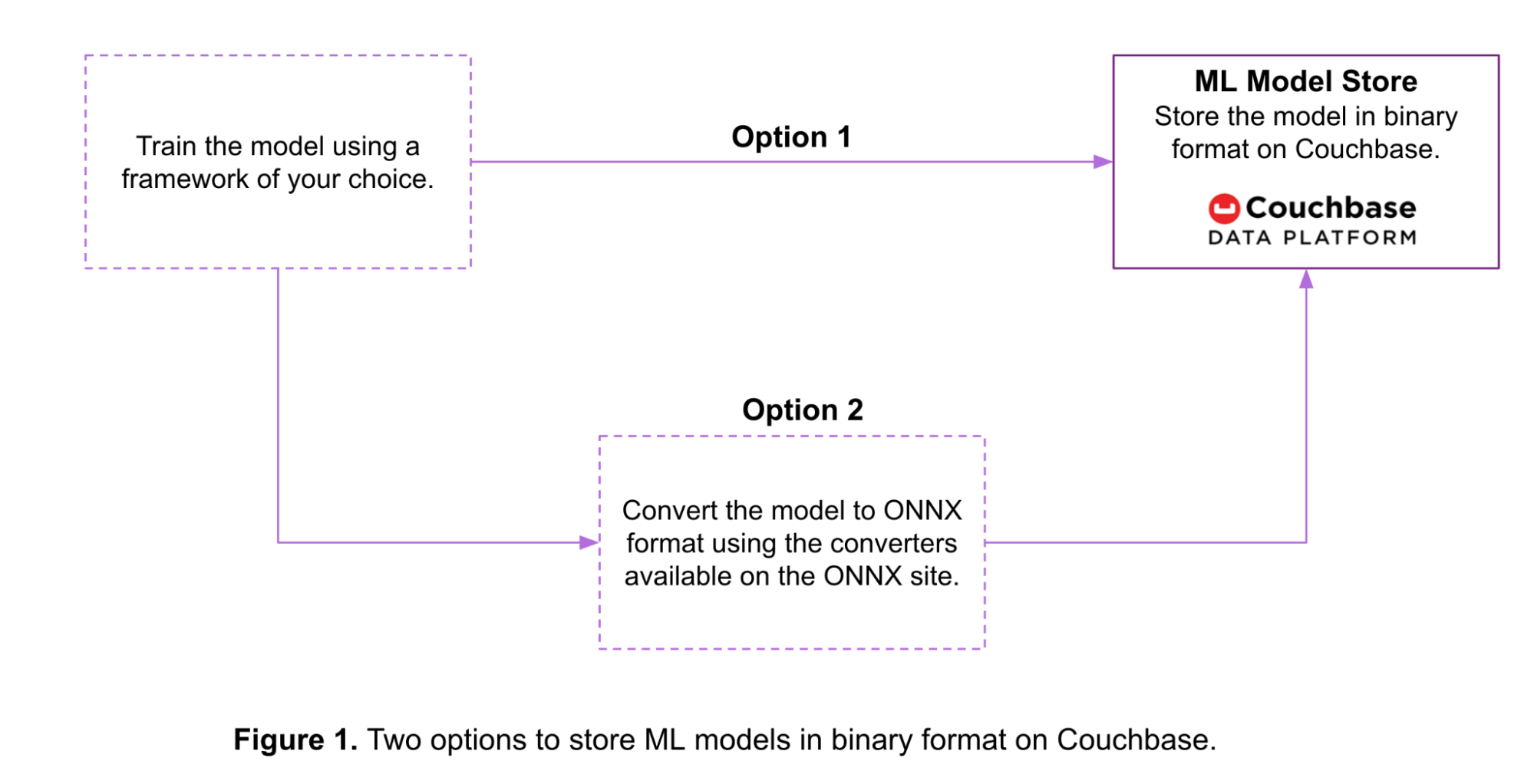
Conforme mostrado na Figura 1 abaixo, há duas opções para armazenar um modelo de ML em formato binário no Couchbase:
- Opção 1: Os modelos treinados em várias estruturas de ML são convertidos em um fluxo de bytes usando ferramentas fornecidas pela própria estrutura. Em seguida, os modelos são armazenados nesse formato em um bucket do Couchbase.
- Opção 2: Os modelos treinados são convertidos no formato ONNX antes de serem armazenados no Couchbase. Aqui estão alguns ferramentas de conversão disponíveis para várias estruturas de ML.
Abaixo está um exemplo de código para a Opção 2. Neste exemplo:
- Um classificador SVM é treinado no conjunto de dados da íris usando a estrutura do scikit-learn.
- O modelo treinado é convertido do scikit-learn para o formato ONNX usando o conversor disponível aqui.
- O modelo ONNX é então armazenado em um bucket do Couchbase chamado
ModelRepositoryusando o Couchbase Python SDK. Leia mais sobre os SDKs do Couchbase disponíveis aqui.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Step-1: Train a scikit-learn model from sklearn import svm from sklearn import datasets clf = svm.SVC() X, y = datasets.load_iris(return_X_y = True) clf.fit(X, y) # Step-2: Convert the scikit-learn model into ONNX format from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 4]))] onx = convert_sklearn(clf, initial_types = initial_type) # Step-3: Store the ONNX model in binary format in a # Couchbase Bucket from couchbase.cluster import Cluster from couchbase.cluster import PasswordAuthenticator from couchbase import FMT_BYTES cluster = Cluster(host) authenticator = PasswordAuthenticator(user_name, password) cluster.authenticate(authenticator) modelBucket = cluster.open_bucket('ModelRepository') key = "iris.onnx" value = onx.SerializeToString() modelBucket.upsert(key, value, format = FMT_BYTES) |
Fluxo de trabalho de desserialização e previsão
O sistema de fornecimento de previsões lê o modelo do Couchbase e gera a previsão (por exemplo, o tipo de flor Iris).
Aqui está o código para ler o modelo que foi armazenado no Couchbase no exemplo anterior.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Read the ONNX model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the previous example rv = modelBucket.get("iris.onnx") onnxModel = rv.value # Predict using ONNX runtime. import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
Esse modelo é então usado para gerar uma previsão usando o tempo de execução do ONNX. As previsões são geradas nas três primeiras linhas da matriz de entrada X que foi obtida no exemplo anterior.
Também é possível dividir o conjunto de dados em dados de treinamento e de teste e gerar previsões sobre os dados de teste.
Uso do Couchbase como um armazenamento de modelos de ML: Formato JSON
Fluxo de trabalho de treinamento e serialização
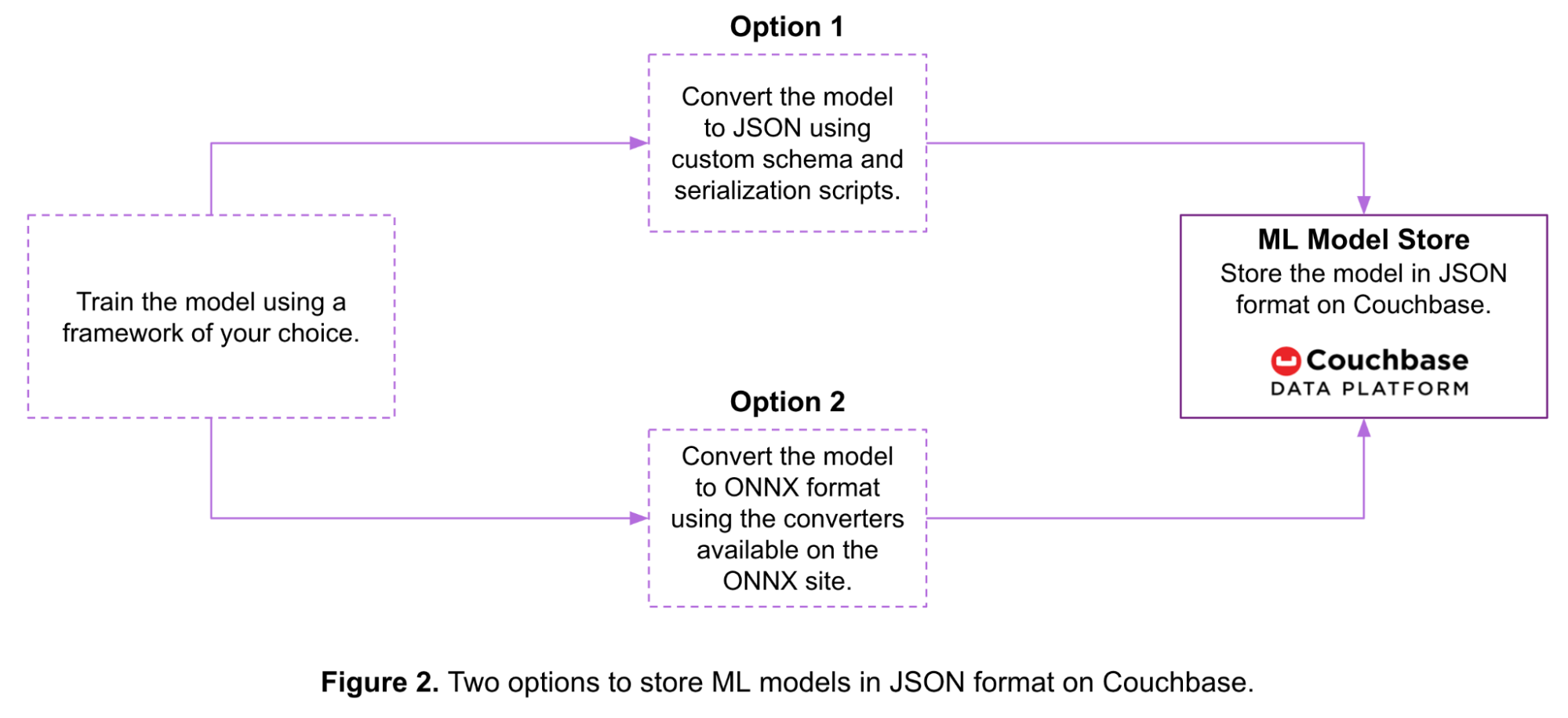
A Figura 2 abaixo mostra duas opções para armazenar um modelo de aprendizado de máquina como um documento JSON no Couchbase:
- Opção 1: Você pode serializar o modelo usando um esquema e scripts personalizados antes de armazená-lo no Couchbase.
- Opção 2: Você pode converter o modelo no formato ONNX e, em seguida, armazená-lo no Couchbase.
Aqui está um exemplo de código para a Opção 2:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Steps 1 and 2 to train the model and convert it into the ONNX # format as well the steps to connect to a Couchbase bucket # are the same as the one in the earlier binary model example. # Step-3: Convert the ONNX model to JSON & store in a # Couchbase bucket from google.protobuf.json_format import MessageToJson import json key = "iris_json.onnx" value = json.loads(MessageToJson(onx)) modelBucket.upsert(key, value) |
Fluxo de trabalho de desserialização e previsão
Aqui está o código de desserialização para ler o modelo que foi armazenado no Couchbase no exemplo anterior. Esse modelo é então usado para gerar uma previsão usando o tempo de execução do ONNX.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Read the ONNX-JSON model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the earlier example rv = modelBucket.get("iris_json.onnx") # Convert the ONNX-JSON model to ONNX object from onnx import ModelProto from google.protobuf.json_format import Parse model = ModelProto() Parse(json.dumps(rv.value), model) onnxModel1 = model.SerializeToString() # Predict using ONNX runtime import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel1) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction1 = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
Aprendizado de máquina on-line usando o Couchbase como um armazenamento de modelos de ML
O Couchbase pode ser usado para armazenar seus modelos de ML para aprendizado de máquina on-line.
A Figura 3 abaixo mostra o fluxo de aprendizagem on-line e previsões com modelos armazenados na plataforma de dados Couchbase.
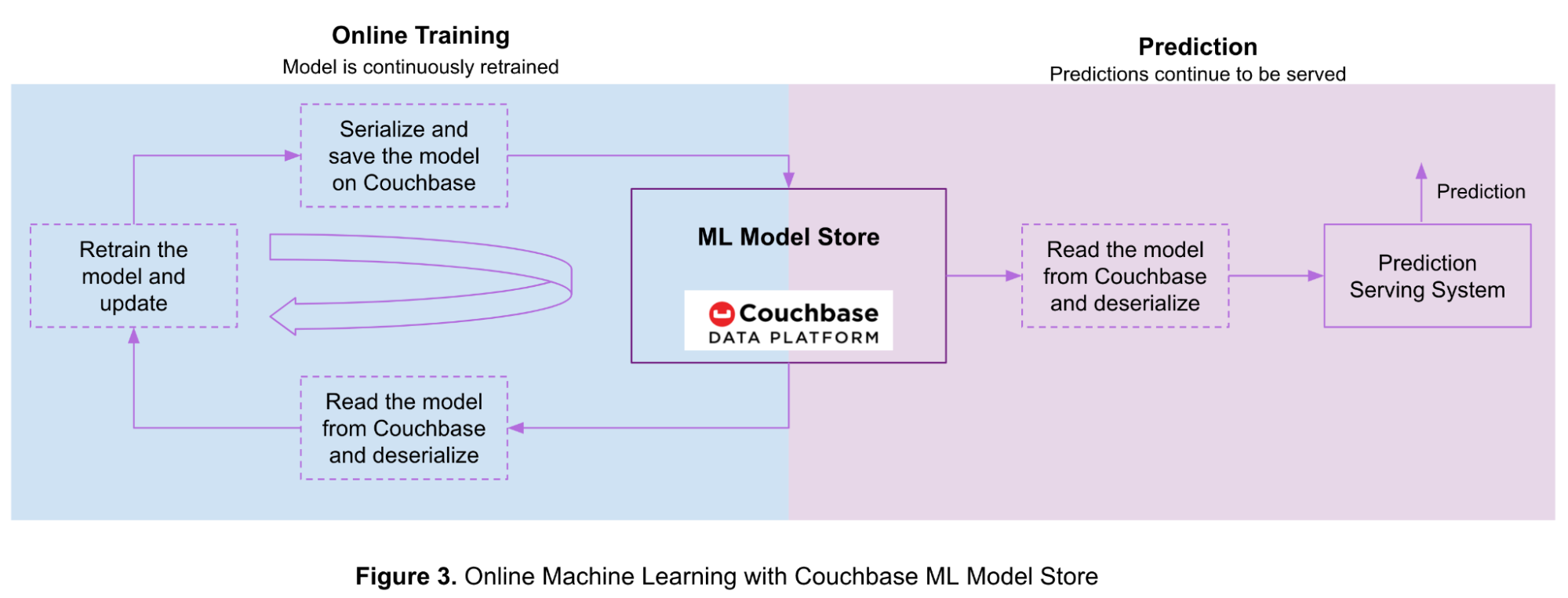
Primeiro, você treina o modelo off-line com uma pequena quantidade de dados de treinamento, depois o serializa e o armazena em um bucket do Couchbase. À medida que mais dados ficam disponíveis, seu modelo de ML é continuamente atualizado usando o aprendizado on-line.
As etapas para usar o Couchbase para aprendizado de máquina on-line são as seguintes:
- Leia o modelo do Couchbase e deserialize-o usando as etapas mencionadas nas seções anteriores.
- Treinar novamente o modelo usando dados de treinamento recém-disponíveis.
- Serialize o modelo atualizado e salve-o em um bucket do Couchbase usando as etapas descritas nas seções anteriores.
- Retorne à etapa 1 à medida que mais dados de treinamento estiverem disponíveis.
Seu sistema de fornecimento de previsões continua a fornecer previsões durante esse processo, seguindo estas etapas:
- Leia o modelo do Couchbase e deserialize-o usando as etapas mencionadas nas seções anteriores.
- Gerar previsão.
A arquitetura dos sistemas mais comuns de fornecimento de previsões foi descrita no artigo da semana passada: 5 Casos de uso para sistemas de serviço de previsão em tempo real com o Couchbase.
Conclusão
Conforme mostrado na Figura 4 abaixo, você pode substituir múltiplos produtos de armazenamento de dados com a única Couchbase Data Platform. Essa abordagem reduz a complexidade, a sobrecarga operacional e o custo total de propriedade (TCO).
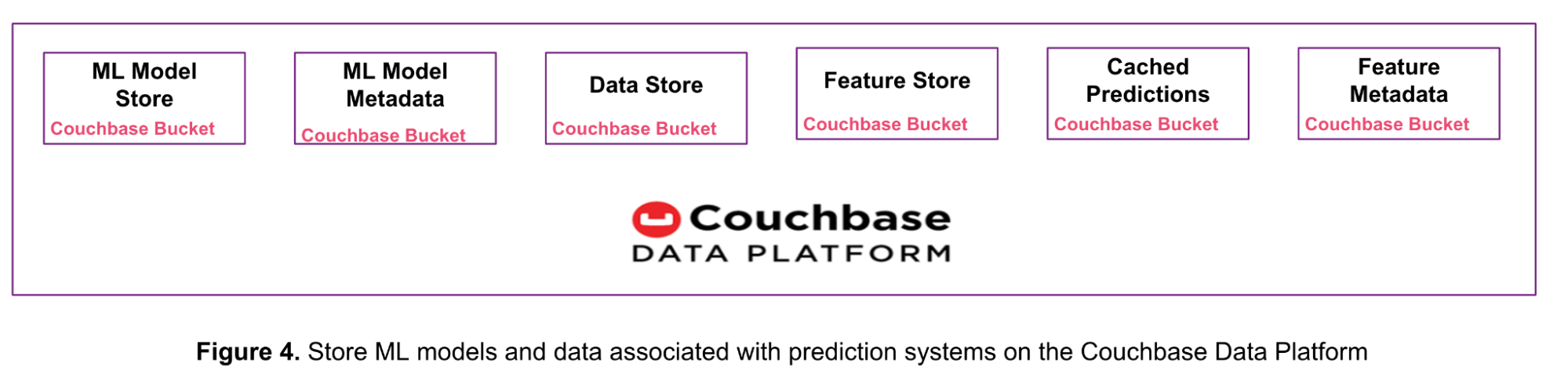
Vimos neste artigo como a plataforma de dados Couchbase armazena modelos de ML de até 20 MB e como ela é usada para aprendizado de máquina on-line.
Na semana passada, analisamos 5 Casos de uso para sistemas de serviço de previsão em tempo real com o Couchbase e aprendeu como a plataforma de dados Couchbase pode armazenar dados brutos de entrada, recursos, previsões, metadados de recursos e metadados de modelos.
Cada um desses tipos de dados pode ser armazenado em um bucket ou coleção separada do Couchbase. Uma coleção é um contêiner de dados dentro de um bucket para agrupar logicamente itens semelhantes. Esse recurso foi introduzido com o Couchbase Server 7.0. Consulte a documentação sobre escopos e coleções no Couchbase para obter mais informações.
Próximas etapas
Se você estiver interessado em aprender mais sobre aprendizado de máquina e Couchbase, aqui estão algumas etapas e recursos excelentes para você começar:
- Inicie sua avaliação gratuita do Couchbase Cloud - Não é necessária instalação.
- Aprofunde-se nos detalhes técnicos com este white paper: Couchbase Under the Hood: uma visão geral da arquitetura.
- Explore o Consulta, Pesquisa de texto completo, Eventose Análises serviços que o Couchbase oferece.
