
Consider this scenario – you are a developer at a fintech company, and one of your users is notified to ask whether they had authorized an international transaction for $1,000. Instead of getting alarmed, the user clicks on the “No” option, with the assurance that your company will take care of the rest.
Behind the scenes, your fraud prevention AI application blocked the purchase before the response, only allowing it to go forward if the user selects “Yes”. The fraud detection system moves quickly, really quickly. It reviews the transaction and predicts whether or not it’s fraudulent with reasonable accuracy in under 50 ms.
To make quick and accurate predictions, your system requires a highly performant, in-memory database such as Couchbase, which stores, retrieves, and delivers data like ML features, profiles, operational data, and other contextual information. Speed and flexibility like that are why leading fintech companies have chosen Couchbase.
Revolut, for example, has built its fraud prevention application to serve its 12+ million users. Although real-time fraud detection is a popular use case among Couchbase customers, we see customers leverage Couchbase for other high-speed use cases such as driver ETA, anomaly detection, dynamic pricing, forecasting, personalized promos, and many more. Couchbase Capella is a Database-as-a-Service (DBaaS) platform that simplifies the development of AI applications and reduces the operational overhead associated with data management.
The role of a feature store
ML algorithms do not understand raw data, hence, it must be preprocessed (using a technique called feature engineering) and transformed into features. ML features are the most relevant fields of a dataset to solve a prediction problem, such as fraud detection. A feature store, both online and offline (more on that in a bit), allows storage, reuse, and secure access to features.
ML developers spend roughly 75-80% of their time on feature engineering. To reduce repeating this effort every time for model training, developers use a feature store to streamline their ML operations. The online feature store is used during predictive analysis, or inference, for low-latency serving of ML features to ML models. Before that can happen, the ML model needs to be trained, which is done with the offline feature store. It is used to store and manage features, which are created during the feature engineering stage.
Several Couchbase customers use Apache Spark for feature engineering jobs because of its massive ecosystem of Python ML libraries for transformations and its MPP (massively parallel processing) capabilities.
To accelerate the development of ML applications, we recently announced a few building blocks that allow you to leverage Capella as both an online and offline feature store within one unified platform:
- Feast plugins to leverage Couchbase in ML applications. Feast (short for Feature Store) is a simple-to-use and cloud-agnostic open-source feature store. Many customers like Revolut already trust Capella as an online feature store. Capella Columnar offers the analytics capabilities that are required for an offline feature store.
- PySpark connector for Capella accelerates feature engineering by combining the massively parallel processing capabilities of Spark with the analytics capabilities of Capella Columnar. Feature engineering jobs involve processing relevant columns as opposed to entire rows and, therefore, can be accelerated using a columnar database like Capella Columnar.
Feast plugins for Couchbase
Feast has been adopted by a wide variety of organizations in different industries, including retail, media, travel, and financial services. The Feast plugins for Couchbase are available in the Feast project. The Capella-backed Feast online and offline feature stores offer the following benefits:
- Makes features available from Capella for training and serving, such that the training/serving skew is minimized
- Avoids data leakage by generating point-in-time correct feature sets so data scientists can focus on feature engineering rather than debugging error-prone dataset joining logic. This ensures that future feature values do not leak to models during training.
- Decouples ML from data infrastructure by providing a single data access layer that abstracts feature storage from feature retrieval. This ensures that models remain portable as you move from training models to serving models, from batch models to real-time models, and from one data infrastructure system to another.
- Registers streaming features into the feature store
- Stores feature-related metadata to enable easy feature discovery in the feature registry
- Validates data to ensure data quality
- Supports transformation
- Versions features to tie feature values to model versions
- Supports Spark for ingestion and syncing offline and online stores
PySpark connector for Couchbase
With its massive ecosystem of Python ML libraries and massively parallel processing capabilities, Apache Spark is second to none for feature engineering. The PySpark connector for Columnar allows you to leverage the Columnar format for your data queries, accelerating the training jobs.
On the other hand, the PySpark connector for Operational allows low-latency serving of features to ML models, accelerating inferencing that is required for applications such as real-time fraud detection.
Here’s the conceptual view of how you could develop an ML application using Capella:
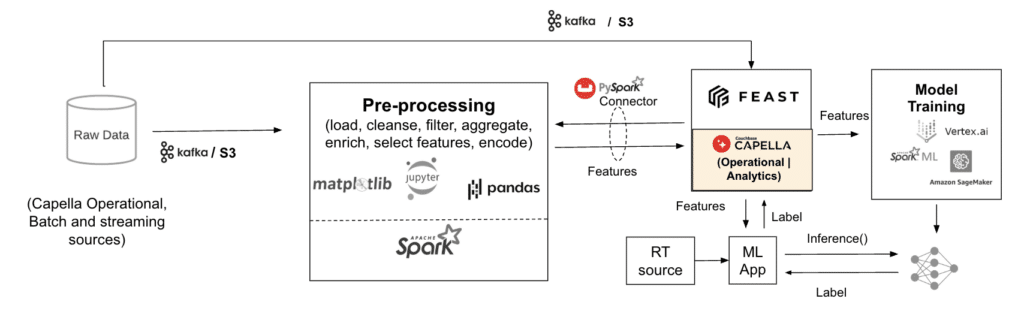
Training pipeline
Step 1: Ingest raw data from Capella (e.g., payment history) and other data sources into Spark for Feature engineering using the respective connectors. The PySpark connector allows you to query data in Capella while supporting optimizations such as predicate pushdowns, etc.
Step 2: Store the features that you created in the Offline store (Capella Columnar) via the Feast APIs and update them as needed via the PySpark connector. The columnar format helps accelerate the feature engineering job when compared to row-based formats.
Step 3: Move the data from Capella Columnar to the ML platform, such as AWS SageMaker, using S3 for staging. You can use SQL++ COPY TO statement to easily move the data to S3.
Step 4: Create a model endpoint for inferencing that the fraud detection application can invoke.
Inference pipeline
Step 1: Sync the data from offline to the online feature store using AirFlow Provider for Couchbase so that the incoming transactions can be processed for fraud detection.
Step 2: In the application, augment the incoming transaction from the transaction source with the information from the online data store and send it to the inference endpoint for predictions.
Step 3: Post-prediction, store the labels along with the associated records in the Capella operational store so that you can use them for auditing or training purposes.
Get started with Capella
Use the building blocks below to get started with your ML application development with Capella:
Leave a comment
You must be logged in to post a comment.