Recapitulação
Nas duas parcelas anteriores de esta sérieNa seção "A arquitetura de microsserviços", discutimos os motivadores por trás da criação de microsserviços. Também analisamos por que o Couchbase é o repositório de dados perfeito para ser usado com essa arquitetura. Também analisamos três variantes de um exemplo de microsserviço de perfil de usuário. Duas foram escritas em Python e uma foi escrita em Node.js para comparação. Nesta última parte da série, discutiremos um método para gerar dados de teste para o esquema de microsserviço.
Por que usar dados de teste?
Testes rigorosos são essenciais para o lançamento de um software estável. Muitos elementos fazem parte de uma boa estratégia de teste. Na última década, o termo "DevOps" é frequentemente usado para fazer referência tanto aos conjuntos de ferramentas usados no desenvolvimento e teste de software quanto à cultura, aos processos e aos procedimentos que devem ser implementados para obter um desenvolvimento rápido e ágil. Independentemente da terminologia, há um ponto em comum: automação e orquestração. Esses dois aspectos podem facilmente constituir sua própria série de blog, portanto, não nos deteremos muito neles, exceto para dizer que a geração de dados de teste é um aspecto essencial do DevOps e do desenvolvimento e teste ágeis de software.
Pessoalmente, caí na armadilha de não ter um bom conjunto de dados de desenvolvimento. Por conveniência, criei manualmente alguns dados que se encaixavam no esquema desejado para que eu pudesse fazer testes de unidade no código. Mas, no dia seguinte, percebi que o código que funcionava bem com meu pequeno conjunto de dados não funcionava muito bem quando era executado em um banco de dados de teste com milhares de registros e dados mais realistas.
Geração de dados JSON para testar o microsserviço Python
Há muitas maneiras de colocar os dados de teste em um banco de dados de teste ou de desenvolvimento. Um método é copiar e higienizar os dados de produção, se possível. Pode não ser viável ter cópias completas da produção para vários ambientes de desenvolvimento e teste, dependendo dos recursos disponíveis. As plataformas de banco de dados devem ser dimensionadas adequadamente e deve-se tomar cuidado para remover dados confidenciais por motivos de conformidade e segurança. Cópias completas de produção devem ser um requisito para ambientes de teste de regressão e pré-produção. A geração de dados sintéticos e aleatórios com um conjunto mínimo de dados para teste e desenvolvimento de unidades geralmente é adequada.
Com um banco de dados relacional, pode ser um desafio criar uma instância de banco de dados com um subconjunto de tabelas porque os modelos relacionais normalmente exigem que todas as estruturas de dados estejam presentes. No entanto, com o formato de documento JSON do Couchbase, isso é muito mais fácil de fazer. Observando a amostra do microsserviço, o esquema foi criado em torno dos escopos e coleções do Couchbase. Eles poderiam facilmente fazer parte de um esquema maior com mais coleções e escopos. Mas tudo o que precisamos são as coleções para acessar chaves, perfis de usuários e imagens de usuários, pois isso é tudo o que o nosso exemplo de serviço precisa acessar para funcionar.
Na segunda parte da série do blog, usamos o JMeter para fazer testes de desempenho. Para realizar testes de desempenho, o banco de dados deve ter pelo menos milhares de registros para fornecer ao JMeter um conjunto de dados razoável para a geração de testes. O microsserviço simplesmente obtém elementos de perfil e os retorna por meio da API REST. O pressuposto é que outros componentes do aplicativo consumam os dados e executem a lógica comercial usando os resultados.
Revisando as três coleções de perfis, veja a seguir um exemplo de um documento na coleção dados_do_usuário coleção. O serviço não impõe se o campo de imagem tem uma ID que faz referência a um registro de imagem. O serviço apenas retorna os dados do perfil ou os dados da imagem. O pressuposto é que o que quer que o consuma no sentido ascendente lidará com essa lógica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": 1, "name" (nome): "Michael Jones", "nickname" (apelido): "mjones", "imagem": "", "user_id": "michaeljones2104", "email": "michael.jones@example.com", "email_verified": "True" (Verdadeiro), "first_name": "Michael", "last_name": "Jones", "endereço": "0208 River Parkway", "cidade": "Strongdol", "estado": "IL", "zip_code" (código postal): "29954", "telefone": "363-555-9036", "date_of_birth": "10/27/1958" } |
A coleção user_images é simples, com um ID de registro (que pode ser referenciado por um perfil de usuário), um campo de tipo de imagem para que vários codecs de imagem possam ser suportados e a própria imagem codificada em Base64. Conforme observado na primeira postagem da série, o Couchbase oferece suporte a documentos binários, mas usamos o JSON por sua portabilidade e extensibilidade no aplicativo de amostra. Isso implica em um custo adicional de largura de banda de rede para obter os dados e os ciclos do processador para fazer a decodificação.
|
1 2 3 4 5 |
{ "record_id": 1, "tipo": "jpeg", "imagem": "AAAAD..." } |
O básico service_auth contém o token de autenticação, mas pode ser facilmente ampliada para incluir outros campos de autenticação.
|
1 2 3 4 |
{ "record_id": 1, "token": "6j6nW3KD0ZXodBv1" } |
Geração de dados JSON de amostra aleatória
Escrevi um utilitário chamado cb_perf para gerar dados aleatórios e inseri-los no Couchbase. O utilitário também faz alguns testes de desempenho para avaliar os recursos do Python em uma plataforma. Ferramentas como o YCSB usam um esquema irrealista, pois o único objetivo é avaliar o desempenho bruto. Eu queria ter a capacidade de pegar um JSON arbitrário e inseri-lo com dados sintéticos aleatórios.
Para testar o microsserviço de amostra, adicionei o esquema a cb_perf para que eu pudesse gerar conjuntos de dados de teste em qualquer cluster do Couchbase. Os cb_perf O utilitário JSON usa um arquivo de definição de esquema JSON. Para cada coleção, você define a estrutura de dados JSON.
Você pode especificar expressões Jinja2 com variáveis que mapeiam os tipos de dados do randomizador para cada valor JSON. Dessa forma, cada registro será diferente. Você também pode definir quais índices criar. Nesse caso, criamos um índice primário e índices secundários em alguns campos.
Ela especifica que id_registro é um campo de ID e que a contagem geral de registros solicitada não deve ser substituída (para que possamos criar quantos registros quisermos).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "name" (nome): "user_data", "schema": { "record_id": "record_id", "name" (nome): "{{ rand_first }} {{ rand_last }}", "nickname" (apelido): "{{ rand_nickname }}", "imagem": "", "user_id": "{{ rand_username }}", "email": "{{ rand_email }}", "email_verified": "{{ rand_bool }}", "first_name": "{{ rand_first }}", "last_name": "{{ rand_last }}", "endereço": "{{ rand_address }}", "cidade": "{{ rand_city }}", "estado": "{{ rand_state }}", "zip_code" (código postal): "{{ rand_zip_code }}", "telefone": "{{ rand_phone }}", "date_of_birth": "{{ rand_dob_1 }}" }, "idkey": "record_id", "primary_index": verdadeiro, "override_count": falso, "indexes" (índices): [ "record_id", "nickname" (apelido), "user_id" ] }, |
Aproveitamos o cb_perf para a coleção de imagens para criar uma imagem JPEG aleatória (ele cria um mapa aleatório de valores RGB para criar uma imagem de cores aleatórias). Definimos o seguinte:
-
- Definir record_id para ser a ID da imagem.
- Crie um índice primário e secundário no campo ID.
- Use uma quantidade de imagens igual à contagem de registros solicitada.
- Substituir a função tamanho padrão do lote para operações assíncronas (o padrão é 100) para defini-lo como 10, pois esses documentos são grandes (aproximadamente 70 KiB por documento). Não queremos criar um gargalo se carregarmos dados em uma rede de longa distância ou na Internet. O padrão pode ser usado em uma rede privada de alta taxa de transferência, como uma VPC de nuvem ou um data center corporativo.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "name" (nome): "user_images", "schema": { "record_id": "record_id", "tipo": "jpeg", "imagem": "{{ rand_image }}" }, "idkey": "record_id", "primary_index": verdadeiro, "override_count": falso, "batch_size": 10, "indexes" (índices): [ "record_id" ] }, |
Criamos apenas um único registro de autenticação no service_auth pois isso é tudo o que é necessário.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "name" (nome): "service_auth", "schema": { "record_id": "record_id", "token": "{{ rand_hash }}" }, "idkey": "record_id", "primary_index": verdadeiro, "override_count": verdadeiro, "record_count": 1, "indexes" (índices): [ "record_id" ] } |
Na parte final, conectamos os registros de imagem aos registros de perfil. Usamos a regra "link" como parte da definição do esquema. As regras de esquema são executadas após um carregamento de dados. Estamos simplesmente extraindo a lista de chaves de registro de imagem e atualizando o campo de imagem nos documentos de perfil para incluir uma referência à chave de imagem.
|
1 2 3 4 5 6 7 8 |
"regras": [ { "name" (nome): "rule0", "tipo": "link", "foreign_key": "sample_app:profiles:user_data:picture", "primary_key": "sample_app:profiles:user_images:record_id" } ] |
Carregando os dados gerados
O Cb_perf tem um modo de carregamento que cria o número especificado de registros do esquema solicitado para carregar os dados.
|
1 |
% ./cb_perf carregar --hospedeiro db.exemplo.com --esquema perfil_demo -u desenvolvedor -p senha --contagem 1000 |
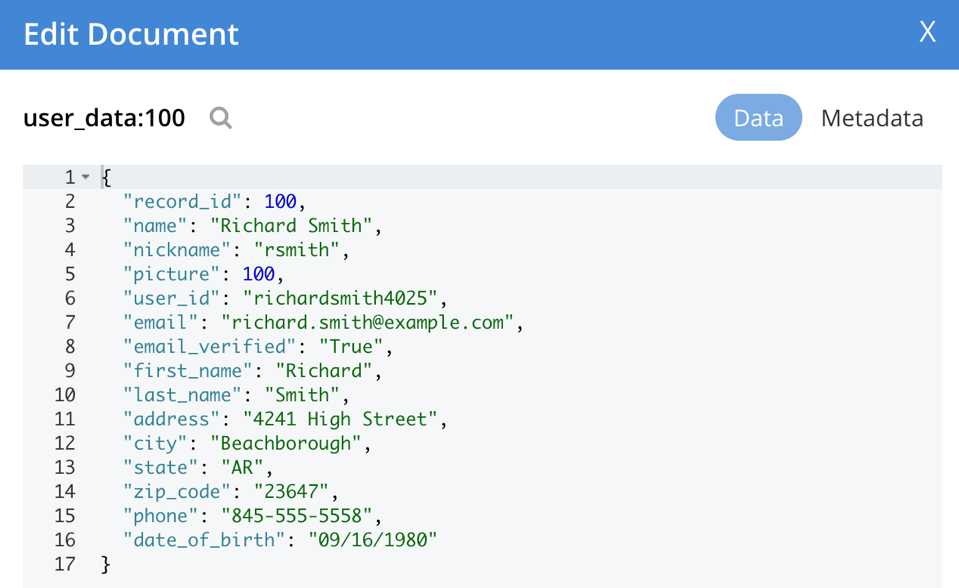
Quando concluído, os dados serão carregados e os índices serão criados. Você está pronto para executar e testar os microsserviços. O utilitário gera automaticamente IDs de documentos (o ID do documento do Couchbase nos metadados do documento, em oposição ao ID do registro no documento) para ser o nome da coleção, mais dois pontos e o ID do registro. Aqui, podemos ver um exemplo do que foi carregado na UI do Couchbase.
A seguir
Isso conclui a série Criando um microsserviço Python com o Couchbase. No entanto, aguarde futuras atualizações sobre novos recursos que estão sendo adicionados ao cb_perf e outros tópicos. Obrigado por ler esta série. Espero que a tenha considerado informativa.
Recursos Python e links de séries de blogs
-
- Baixe o utilitário cb_perf do meu GitHub
- Leia as postagens anteriores desta série:
- Documentos do Couchbase Python SDK - Primeiros passos com o Python SDK
Fato engraçado aleatório
Em um universo muito, muito distante, em uma época tecnológica diferente, o Perl era a linguagem interpretada mais popular. Ela cresceu de uma linguagem de processamento de texto (como o clássico AWK do UNIX) para uma linguagem de uso geral onipresente. Entre 1996 e 2000, a comunidade Perl decidiu se inspirar na antiga competição Obfuscated C e realizou competições Obfuscated Perl. A sintaxe solta e de forma livre do Perl certamente pode levar a programas difíceis de decifrar, portanto, é natural que tenha havido uma competição desse tipo. Todo programador, em algum momento, olha para algo que escreveu, talvez alimentado por cafeína e privação de sono, e se pergunta o que isso faz.
|
1 |
python3 -c "print(bytearray([ord(b'a')+b%26 for b in [19,7,0,13,10,18]]).decode('utf-8'))" |
