Em a primeira parte desta sérieEm nosso artigo sobre o Couchbase, discutimos os motivadores por trás da criação de microsserviços e por que o Couchbase é o repositório de dados perfeito para ser usado em uma arquitetura de microsserviço. Com sua natureza sem estado, ele pode ser implantado em qualquer lugar e dimensionado horizontalmente conforme necessário. Embora seja possível escrever um microsserviço em qualquer linguagem, para se adequar a um fluxo de trabalho ágil em que é necessário fornecer funcionalidade rapidamente, você deve escolher uma linguagem conhecida pela maioria dos desenvolvedores e que permita um desenvolvimento rápido. Como Python e JavaScript são duas linguagens populares, qualquer uma delas seria uma boa opção. Nesta série de blogs, vamos nos concentrar em Python.
Considerações sobre o desempenho distribuído
Os requisitos de desempenho dos aplicativos são importantes, mas às vezes são difíceis de quantificar. Um exemplo simples é um relatório que é executado em X horas; no entanto, ele deve ser executado em Y minutos devido a requisitos comerciais. Esse exemplo é fácil de quantificar e fornece uma meta clara de melhoria. Quando você tem uma arquitetura geograficamente distribuída, se um componente puder suportar X solicitações por segundo, isso não significa nada. Considerando o número de variáveis em uma arquitetura geograficamente aplicativo distribuídoSe você não tiver uma solução, precisa dar um passo atrás e começar com algo que possa quantificar; por exemplo, você quer que um aplicativo para smartphone carregue totalmente em X segundos ou que uma página da Web carregue totalmente em Y segundos. Em seguida, trabalhe de trás para frente para ver o que é necessário para que isso aconteça.
Considerações sobre o desempenho do microsserviço Python
Ao criar um microsserviço em Python, você tem algumas opções a considerar antes de começar a codificar. Você pode escrever todo o seu próprio código Python para criar o serviço ou usar uma estrutura de API Python, como Flask ou FastAPI. Em a primeira parte desta sérieNa seção "Código completo", forneci um exemplo da primeira opção. Chamarei essa opção de "código completo". Nesta segunda parte da série, apresentarei uma implementação do serviço simples de perfil de usuário usando FastAPI. Escolhi o FastAPI em vez do Flask para este blog porque a maioria o considera mais rápido, e achei que seria divertido experimentá-lo.
Mas, primeiro, vamos nos concentrar em nosso exemplo original de "código completo". Usamos a função Servidor HTTPS para criar um servidor Web básico para responder às nossas chamadas de API. Para nossa API, decidimos usar caminhos (em vez de parâmetros ou publicação de um corpo JSON), pois é rápido e fácil de analisar. Nossa API simples de perfil de usuário não precisa fornecer muita coisa - apenas alguns métodos para procurar um perfil de usuário e obter os dados. Incluí opções de pesquisa por ID, Apelido ou Nome de usuário. Na vida real, os requisitos variam de acordo com a forma como o aplicativo upstream é projetado.
O programa de código completo tem duas áreas lógicas: o código que é executado uma vez e o código executado para cada solicitação, ou seja, a função do_GET. Por conveniência, não vamos nos concentrar no código de execução limitada, mas na função do_GET e em suas funções satélite. Com a função Servidor HTTPS essa função será chamada com cada solicitação. O caminho da solicitação estará na classe e poderá ser acessado por meio de self.path e os cabeçalhos estão em self.headers. Se estiver apenas começando a usar Python, autônomo é assim em Java - ele faz referência à instância de chamada da classe.
O serviço precisará iterar o conteúdo da string de caminho para que possa fazer a pesquisa apropriada e retornar os dados. Graças à beleza do design nativo do JSON do Couchbase, não precisamos fazer muita coisa, se é que precisamos fazer alguma coisa, com os dados antes de enviá-los. Portanto, vamos nos concentrar em como inspecionar o caminho. O Python tem muitas opções integradas para processamento de strings que permitem que você escreva um código bonito, mas não necessariamente o código mais rápido. Python é uma linguagem interpretada (é executada diretamente a partir da fonte), portanto, as declarações fazem diferença.
Vamos dar uma olhada em duas opções para o processamento de strings de caminho - o começa com e dividir métodos.
|
1 2 3 4 5 6 7 |
% python3 -m tempo -s 'text="/api/v1/id/4"' 'text.startswith("/api/v1/id/")' 2000000 loops, melhor de 5: 111 nsec por loop % python3 -m tempo -s 'text="/api/v1/id/4"' 'text.split("/")[-1]' 1000000 loops, melhor de 5: 205 nsec por loop |
A divisão é mais cara, mas teremos de fazê-la, portanto, seria melhor fazê-la apenas uma vez. Assim, podemos evitar chamar qualquer outra coisa usando o array retornado da divisão em vez de começa com.
|
1 2 3 |
% python3 -m tempo -s 'True if 1 == 5 else False' 50000000 loops, melhor de 5: 6.07 nsec por loop |
As instruções condicionais são rápidas, portanto, embora possa não parecer bonito, faremos uma única divisão e, em seguida, criaremos um if...elif...else para iterar pelo caminho. Escreveremos funções auxiliares curtas para fazer uma consulta ou obter um valor-chave e retornar os dados JSON ao solicitante com o mínimo de processamento.
Além disso, para tornar nosso microsserviço seguro, adicionaremos um token de portador. Usaríamos algo como o OAuth com tokens Bearer e JWT em um ambiente real. Para o nosso exemplo, simplificaremos muito isso e adicionaremos uma coleção ao nosso esquema com um token fixo. O serviço consultará esse token na inicialização e responderá somente às solicitações que fornecerem esse token como um token de portador. Por fim, se necessário, adicionaremos um caminho de verificação de integridade que responde com um HTTP 200 para sabermos que nosso serviço é saudável.
|
1 2 3 4 5 6 7 8 9 10 |
def do_GET(autônomo): vetor_caminho = autônomo.caminho.dividir('/') path_vector_length = len(vetor_caminho) se path_vector_length == 5 e vetor_caminho[3] == 'id': se não autônomo.v1_check_auth_token(autônomo.cabeçalhos): autônomo.não autorizado() retorno parâmetro_de_pedido = vetor_caminho[4] registros = autônomo.v1_get_by_id('user_data', parâmetro_de_pedido) autônomo.v1_responder(registros) |
Contêineres do microsserviço Python
Decidi usar o Kubernetes para testar o serviço, então tive que criar contêineres com as várias implementações da API. Há um contêiner Python publicado que pode ser usado como base. Alguns pré-requisitos do sistema operacional terão de ser instalados antes dos pacotes Python necessários. O contêiner Python é baseado no Debian, portanto os pacotes de pré-requisitos podem ser instalados com o APT. Em seguida tubulação pode ser chamado para instalar os pacotes Python necessários. A porta do serviço precisará ser exposta e, por fim, o serviço poderá ser executado da mesma forma que seria executado na linha de comando. Para colocar o serviço em um contêiner, ele precisará de uma modificação adicional para oferecer suporte a variáveis de ambiente, pois esse é o método preferido para passar parâmetros para um contêiner.
Este é um exemplo do Dockerfile para o serviço de código completo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DE python:3.9-bullseye CORRER apto atualização CORRER apto instalar elpa-magit -y CORRER apto instalar git-todos python3-dev python3-tubulação python3-ferramentas de configuração cmake construir-essenciais libssl-dev -y WORKDIR /usr/src/aplicativo ADD . /usr/src/aplicativo CORRER tubulação instalar --não-cache-dir -r requisitos.txt EXPOSIÇÃO 8080 CMD ./micro-serviço-demonstração.py O serviço pode então ser executar de passagem o parâmetros através de o ambiente: doca executar -d --nome microsserviço \ -p 8080:8080 \ -e COUCHBASE_HOST=$COUCHBASE_HOST \ -e USUÁRIO DA BASE DE DADOS=$COUCHBASE_USER \ -e COUCHBASE_PASSWORD=$COUCHBASE_PASS \ -e COUCHBASE_BUCKET=$COUCHBASE_BUCKET \ testesvc |
FastAPI
Há algum tempo, a WSGI (Web Server Gateway Interface) foi criada para estruturas da Web em Python. Ela permitiu que um desenvolvedor se concentrasse apenas na criação de aplicativos da Web, em vez de todas as outras tarefas de nível inferior necessárias em um servidor da Web. Esse padrão foi estendido para a ASGI (Asynchronous Server Gateway Interface), que oferece suporte à programação Python assíncrona e, portanto, é adequada para aplicativos sem estado, como APIs REST.
Uvicórnio é uma implementação de servidor Web ASGI para Python, e o FastAPI se integra ao Uvicron para criar uma plataforma de desenvolvimento rápido de API. Decidi usar isso para criar uma segunda implementação de API para comparar com a versão completa do código. Como ele oferece suporte total ao Python assíncrono, também funciona bem com o Couchbase Python SDK, que oferece suporte total à programação assíncrona.
O uso dessa estrutura acelera o desenvolvimento porque é necessário muito menos código do que a versão de código completo. Algumas funções para se conectar ao Couchbase são necessárias, mas, além disso, os métodos de aplicativos decorados são usados para interagir com a instância da FastAPI chamando segmentos mínimos de código para buscar e retornar dados. Assim como na versão de código completo, o serviço se conecta ao Couchbase uma vez e usa os métodos de coleta resultantes para obter dados. Os no evento é usado na inicialização para se conectar ao Couchbase, recuperar o token de autenticação e definir todas as variáveis necessárias.
|
1 2 3 4 5 6 7 8 9 10 |
@aplicativo.no evento("inicialização") assíncrono def service_init(): key_id = '1' agrupamento[1] = aguardar get_cluster() coleções['service_auth'] = aguardar get_collection(agrupamento[1], 'service_auth') doc_id = f"service_auth:{key_id}" resultado = aguardar coleções['service_auth'].lookup_in(doc_id, [SD.obter('token')]) auth_token[1] = resultado.content_as[str](0) coleções['user_data'] = aguardar get_collection(agrupamento[1], 'user_data') coleções['user_images'] = aguardar get_collection(agrupamento[1], 'user_images') |
Depois que as ações de inicialização são concluídas, funções curtas para cada caminho de solicitação possível são invocadas por meio de chamadas de método do aplicativo. O parâmetro path é extraído do caminho e passado para a função, juntamente com uma dependência da função para verificar o token de autenticação. Com essa implementação, somente variáveis de ambiente são usadas para passar parâmetros de conexão.
|
1 2 3 4 5 |
@aplicativo.obter("/api/v1/id/{document}", modelo_de_resposta=Perfil) assíncrono def get_by_id(documento: str, autorizado: bool = Depende(verificar_token)): se autorizado: perfil = aguardar get_profile(coleção=coleções['user_data'], nome_da_coleção='user_data', documento=documento) retorno perfil |
O contêiner para essa implementação pode usar a mesma base que a versão completa do código e instalar as mesmas dependências; no entanto, ele terá alguns requisitos adicionais de pacotes Python e o serviço será chamado por meio do Uvicorn.
|
1 2 3 4 5 6 7 8 9 |
DE python:3.9-bullseye CORRER apto atualização CORRER apto instalar elpa-magit -y CORRER apto instalar git-todos python3-dev python3-tubulação python3-ferramentas de configuração cmake construir-essenciais libssl-dev -y WORKDIR /usr/src/aplicativo ADD . /usr/src/aplicativo CORRER tubulação instalar --não-cache-dir -r requisitos.txt EXPOSIÇÃO 8080 CMD uvicórnio serviço:aplicativo --hospedeiro 0.0.0.0 --porto 8080 |
Configuração do Node.js para testar pontos de extremidade
A publicação do blog é sobre Python, mas seria útil ter uma comparação não-Python para a API, portanto, para isso, decidi usar o Node.js; ele é assíncrono e funciona bem com APIs. A implementação do Node.js usa o módulo Express para criar um servidor Web e, de forma semelhante à FastAPI, usa o módulo app.get para todos os caminhos compatíveis. Ele chama uma função para verificar primeiro o token de autenticação e, se for bem-sucedido, chama uma função para obter os dados solicitados.
|
1 2 3 4 5 6 |
aplicativo.obter('/api/v1/nickname/:nickname', checkToken, getRESTAPINickname); aplicativo.obter('/api/v1/username/:username', checkToken, getRESTAPIUsername); aplicativo.obter('/api/v1/id/:id', checkToken, getRESTAPIId); aplicativo.obter('/api/v1/picture/record/:id', checkToken, getRESTAPIPictureId); aplicativo.obter('/api/v1/picture/raw/:id', checkToken, getRESTAPIImageData); aplicativo.obter('/healthz', getHealthCheckPage); |
Há um módulo para as funções do Couchbase localizado em um arquivo JavaScript, e as funções para as chamadas de API compatíveis também estão em módulos em arquivos JavaScript separados. Como no Python, há um contêiner do Node que é usado como base e o utilitário NPM mantém as dependências e inicia o serviço.
|
1 2 3 4 5 6 7 8 |
DE nó:16.14.2 WORKDIR /aplicativo ADD . /aplicativo CORRER rm -rf /aplicativo/módulos_nó CORRER npm instalar -g npm@mais recente CORRER npm instalar EXPOSIÇÃO 8080 CMD npm iniciar |
Kubernetes para fazer o spinup do Couchbase de forma autônoma
Como mencionado anteriormente, o Kubernetes foi escolhido para testar as implementações de serviço. Isso permitiu testes acelerados devido à capacidade de implantar e dimensionar rapidamente os serviços para diferentes cenários de teste. Há duas opções para usar o Couchbase com o Kubernetes. O Operador Autônomo do Couchbase pode ser usado para implantar o Couchbase no ambiente do Kubernetes, ou o serviço pode se conectar a um cluster externo. O serviço foi testado com um cluster externo que foi implantado no mesmo VPC de nuvem. Todos os nós estavam na mesma região de nuvem, e os nós do cluster do Couchbase e os nós do Kubernetes foram implantados em zonas de disponibilidade para simular o que provavelmente seria visto em uma implantação no mundo real.
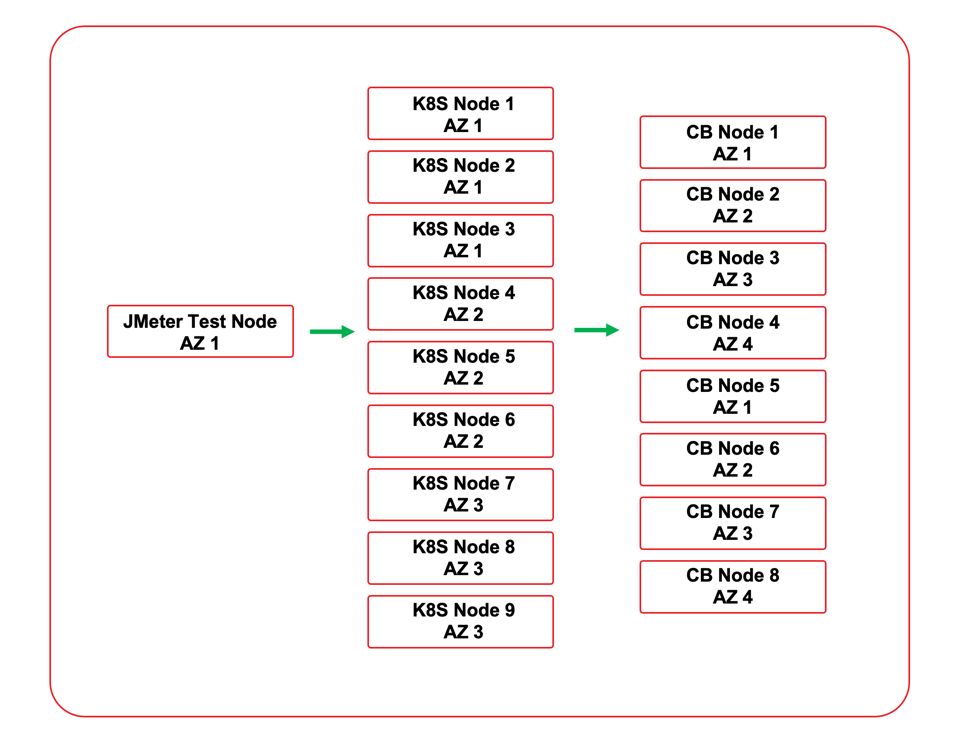
Três arquivos YAML de implantação foram criados para implantar as três implementações. Cada YAML de implantação cria um namespace para o serviço. Ele usa um segredo para a senha do Couchbase. O serviço é implantado com 4 réplicas inicialmente. Como é um microsserviço sem estado, ele pode ser ampliado e reduzido conforme necessário. O tráfego é direcionado para o serviço com um balanceador de carga. Como o ambiente Kubernetes usado foi integrado a um provedor de nuvem, cada implantação também provisionou um balanceador de carga de nuvem para o serviço.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
Versão da API: v1 gentil: Namespace metadados: nome: demopia --- Versão da API: v1 gentil: Secreto metadados: nome: demopia-segredos espaço de nome: demopia tipo: Opaco dados: adminPassword: aBcDeFgH= --- Versão da API: aplicativos/v1 gentil: Implantação metadados: nome: demopia espaço de nome: demopia especificação: réplicas: 4 seletor: matchLabels: aplicativo: demopia estratégia: tipo: RollingUpdate rollingUpdate: maxUnavailable: 25% maxSurge: 1 modelo: metadados: rótulos: aplicativo: demopia especificação: contêineres: - nome: demopia imagem: mminichino/demopia:1.0.5 imagePullPolicy: Sempre portos: - nome: aplicativo-porto containerPort: 8080 env: - nome: BASE DE SOFÁ_HOST valor: 1.2.3.4 - nome: BASE DE SOFÁ_USUÁRIO valor: Administrador - nome: BASE DE SOFÁ_SENHA valueFrom: secretKeyRef: nome: demopia-segredos chave: adminPassword - nome: BASE DE SOFÁ_BUCKET valor: aplicativo_amostra --- Versão da API: v1 gentil: Serviço metadados: nome: demopia-serviço espaço de nome: demopia rótulos: aplicativo: demopia especificação: seletor: aplicativo: demopia portos: - nome: http porto: 8080 porta de destino: 8080 tipo: Balanceador de carga |
Usando os arquivos YAML de implantação, o serviço pode ser implantado e dimensionado conforme necessário com a CLI do Kubernetes. Opcionalmente, se esse fosse um ambiente de produção real, ferramentas como dimensionamento automático e balanceamento de carga avançado poderiam ser usadas para controlar e acessar a implantação.
|
1 2 |
$ kubectl aplicar -f demopia.yaml $ kubectl escala implantação --réplicas=8 demopia -n demopia |
Resultados de desempenho do cluster
Antes de testar os serviços, o cluster do Couchbase foi testado a partir do cluster do Kubernetes para criar uma linha de base. Foi usada a carga de trabalho B do YCSB (que é principalmente de valor-chave obter operações) e produziu 156.094 operações/s. O teste de API foi feito com o Apache JMeter. A chamada de API de ID foi usada para manter a simplicidade, e o gerador de números aleatórios do JMeter foi aproveitado para criar execuções de teste em perfis de usuários aleatórios. O cenário de teste foi limitado por tempo, com um tempo de execução de três minutos, em que geraria carga irrestrita contra o serviço de balanceador de carga solicitando perfis de usuário aleatórios sem aumento (a carga foi constante durante toda a duração do teste).
Para o primeiro conjunto de testes, os parâmetros de teste do JMeter permaneceram inalterados, e o que variou foi a escala das três implementações de API. Os testes começaram com 4 pods para cada implementação e foram ampliados para 8 e, finalmente, 16 pods. Todas as implementações escalonaram a taxa de transferência à medida que os pods eram escalonados na implementação.
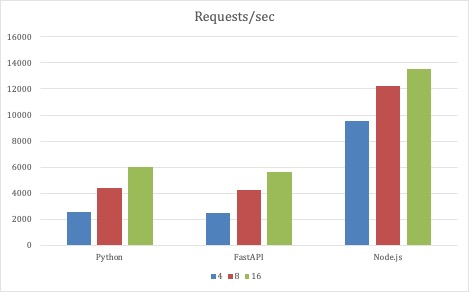
O Node.js foi o que se saiu melhor com essa estratégia de teste, pois teve a menor latência média. Um milissegundo não é muita latência, nem 12 milissegundos. Mas com um número fixo de threads de gerador criando mais de 1 milhão de solicitações em três minutos, os milissegundos têm um efeito cumulativo. No entanto, lembre-se de que este é um teste extremo. Esses são apenas pontos de dados. O que foi surpreendente foi que o serviço Python de código completo acompanhou o ritmo da implementação da FastAPI.
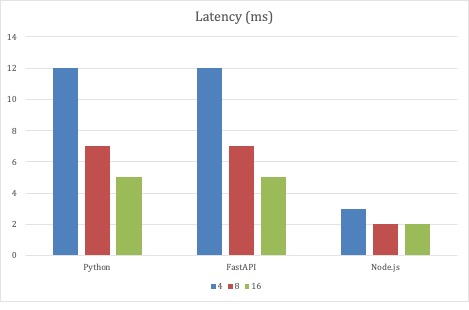
Como o primeiro cenário de teste demonstrou que as implementações de código completo do Python e da FastAPI eram dimensionáveis, a segunda rodada de testes dimensionou o número de threads de solicitação com um número fixo de 32 pods de serviço. Com esse cenário de teste, os serviços baseados em Python puderam ser dimensionados para quase 10.000 solicitações por segundo.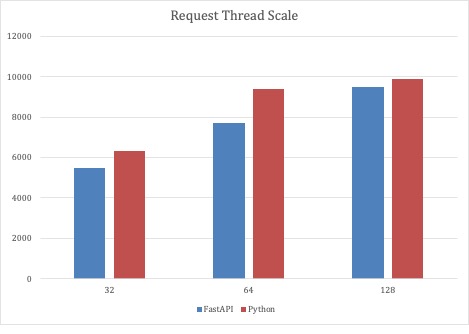
Conclusões
Acho que o Python é uma excelente opção para serviços de carga moderada. Com todos os testes realizados, os nós do cluster do Kubernetes tinham ampla CPU e memória disponíveis, portanto, havia bastante espaço para dimensionar o serviço conforme necessário. Para implementações que exigem escala maciça com a menor latência, o Node.js pode ser uma opção melhor. O Couchbase oferece suporte a todas as linguagens predominantes, portanto, assim como consegui codificar facilmente três implementações de microsserviço, qualquer pessoa pode usar várias linguagens e estruturas e integrar o Couchbase com facilidade.
Próximo
Na próxima publicação desta série do blog, falarei sobre a geração de dados de teste aleatórios para o esquema de microsserviço. Aqui estão os links para os recursos mencionados nesta postagem:
- Crie um microsserviço Python com o Couchbase - Parte 1
- Parte 2 - Código-fonte do microsserviço para o perfil do usuário
- Oferta do Capella Couchbase Cloud
- Operador autônomo do Couchbase
Fato engraçado aleatório
Os códigos de resposta HTTP são definidos de acordo com a especificação do protocolo. O intervalo 400 é reservado para situações em que o erro parece ter sido causado pelo cliente. O HTTP 418 é o erro "I'm a teapot" (Sou um bule de chá) e a especificação afirma que o código de resposta de erro do cliente "I'm a teapot" (Sou um bule de chá) indica que o servidor se recusa a preparar café porque é, permanentemente, um bule de chá. Uma combinação de café e bule que esteja temporariamente sem café deve retornar 503."

Postagem legal!
Acho que o fastapi sofre muito com o serializador padrão, e o pydantic, embora seja razoavelmente rápido, está fazendo a validação dos dados de saída e, provavelmente, está consumindo muito tempo.