Query syntax is limited. Queries are unlimited.
Predicate pushdown, group by pushdown, offset pagination, keyset pagination, join optimization, search optimization, we’ve discussed it all. Still, it’s important to understand the default, simple — albeit slow — execution flow of the query.
Lukas Eder has explained the true order of SQL execution. Because N1QL is inspired from SQL and follows it closely, that explanation holds here as well. I highly recommend reading it.
With N1QL, you can use the visual explain to see the plan structure and the data flow. This is an easy way to understand the order of execution before you optimize for performance by creating indexes. I’ve used the built-in travel sample and hence forced the primary scan with the USE INDEX hint.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT hotel.name, hotel.country, COUNT(hr.ratings.Service) csr, RANK() OVER(ORDER BY COUNT(hr.ratings.Service) ), DENSE_RANK() OVER(ORDER BY COUNT(hr.ratings.Service)) FROM `travel-sample` AS hotel USE INDEX (def_primary) INNER JOIN `travel-sample` AS airport ON (hotel.country = airport.country) LEFT OUTER UNNEST hotel.reviews AS hr WHERE hotel.type = "hotel" AND airport.type = "airport" AND hr.ratings.Service >= 4 GROUP BY hotel.name, hotel.country HAVING COUNT(hr.ratings.Service) > 0 ORDER BY COUNT(hr.ratings.Service) OFFSET 0 LIMIT 10 |
Here’s the visual plan. The plan execution and the data flow is bottom up. Starts with primary index scan and a secondary index scan, ends up with the LIMIT pagination operator before returning the results to the application.
The visual explain is interactive. You can click on each operator to see the parameters set for that operator by the optimizer, as shown for some of the operators below.
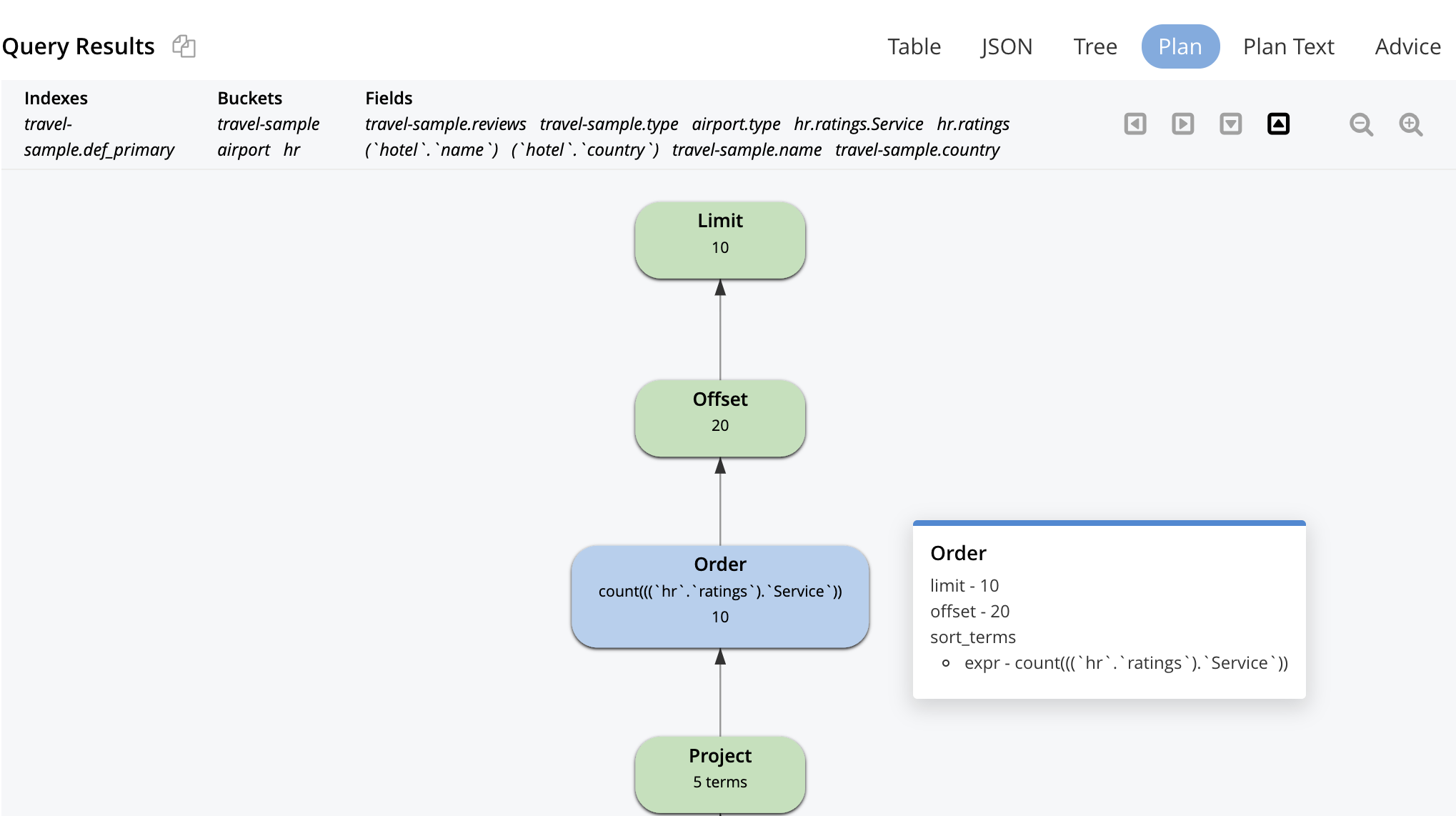
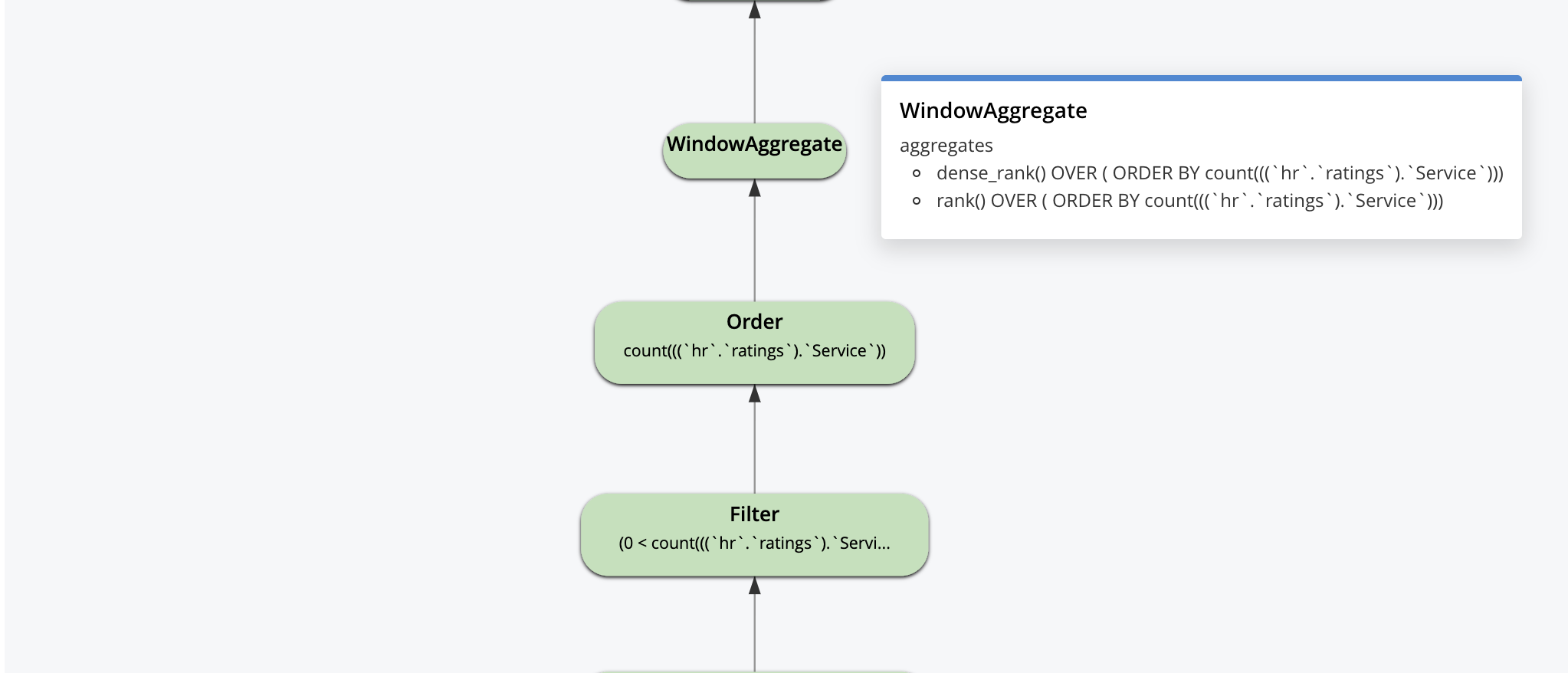
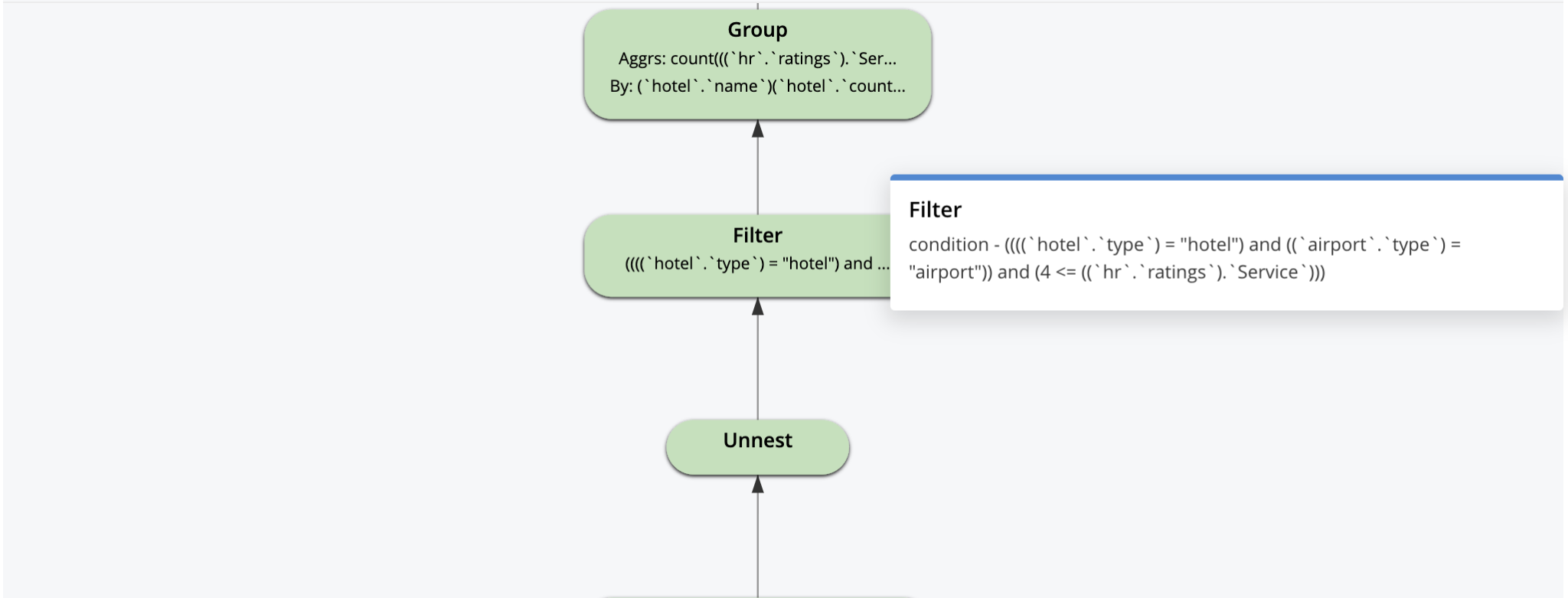
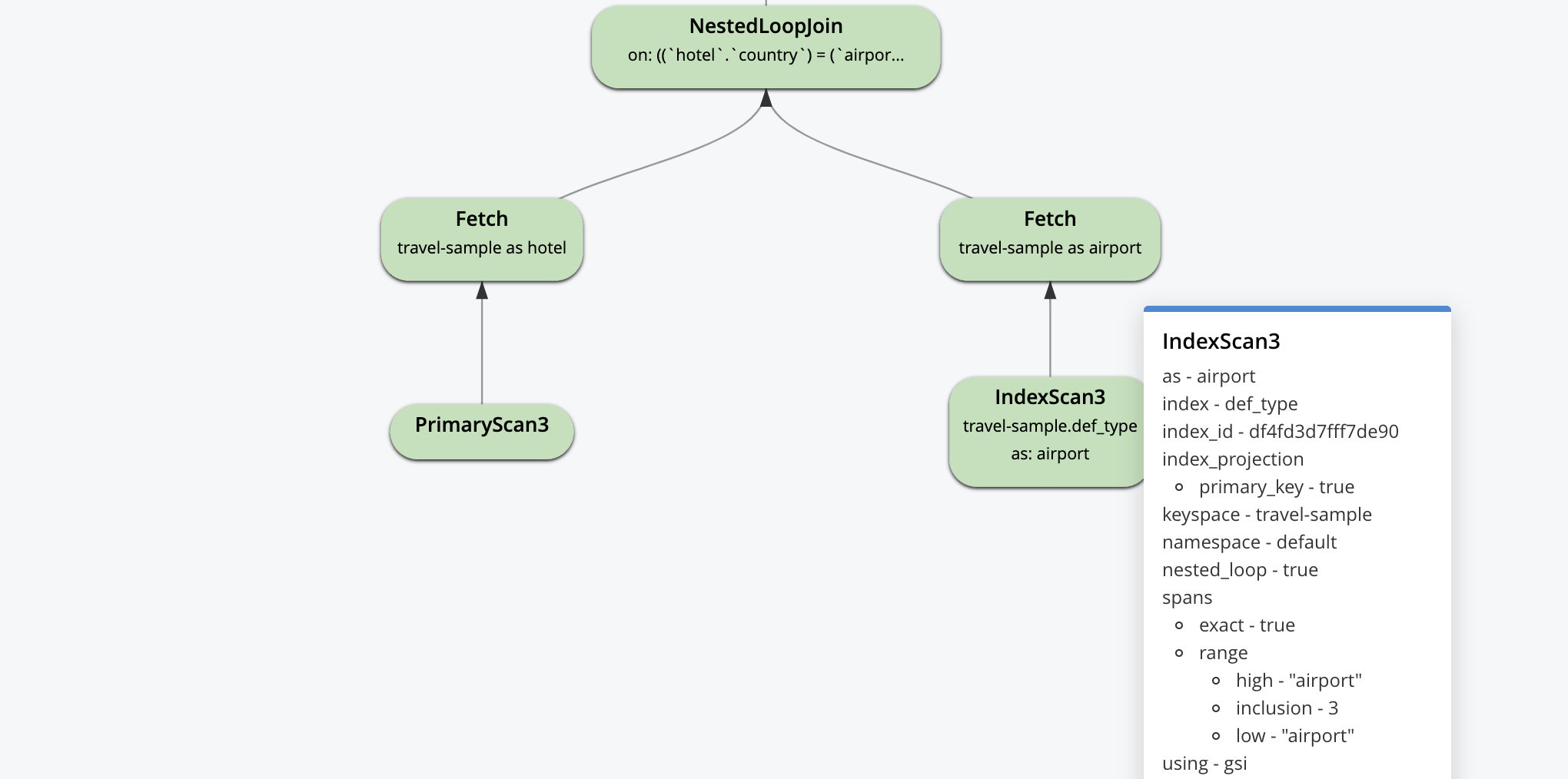
The query plan starts with this, logically. Every optimization on top of this is thought by people/tools and selected by the optimizer to construct a dataflow machine for every query. The goal of the optimizer is create machines that do as little work as possible and still deliver the correct results.