

Read the pagination background in my previous article: https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
Pagination is the task of dividing the potential result into pages and retrieving the required pages, one by one on demand. Using OFFSET and LIMIT is the easy way to write pagination into database queries. Together, OFFSET and LIMIT, make the pagination clause of the SELECT statement. Pagination is a common application job and its implementation has a major impact on the customer experience. Let’s look at the issues and solutions with Couchbase N1QL in detail.
Markus Winand from https://use-the-index-luke.com/ argues it may not be the most efficient. He also suggests, when possible, using keyset pagination approach instead of OFFSET pagination. For this article, I’m going to use the example queries modeled on his article, https://use-the-index-luke.com/no-offset to show what OFFSET optimizations we’ve done, when and how to exploit the keyset pagination in N1QL.
Since Couchbase ships with a travel-sample dataset, we’ll use it to write our pagination queries.
- GET THE FIRST PAGE
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM `travel–sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 0 LIMIT 10; CREATE INDEX ixtopic ON `travel–sample`(type); |
For this query, using the index ixtopic, the query engine executes in a simple way. The query engine gets all the qualified keys from the index, then gets all the documents, sorts based on the ORDER BY clause and then drops the OFFSET number of documents (in this case zero) and projects LIMIT (in this case 10) number of documents.
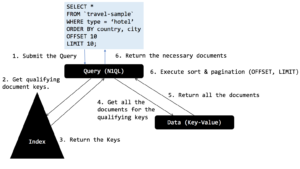
Here’s the plan showing the index and the spans.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ “index”: “ixtype”, “index_id”: “8630f5f7e05ee113”, “index_projection”: { “primary_key”: true }, “keyspace”: “travel-sample”, “namespace”: “default”, “spans”: [ { “exact”: true, “range”: [ { “high”: “”hotel“”, “inclusion”: 3, “low”: “”hotel“” } |
N1QL chooses the index ixtype and pushes the filter (type = “hotel”) to the index scan. To implement the ORDER BY clause, it fetches all the documents. In the sort phase, we recognize LIMIT 10 clause and make the sort efficient by keeping only the top 10 items.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ “#operator”: “Order”, “limit”: “10”, “sort_terms”: [ { “expr”: “(`travel-sample`.`country`)” }, { “expr”: “(`travel-sample`.`city`)” } ] }, |
Let’s look at the index scan operator efficiency with this index:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
“#operator”: “IndexScan2”, “#stats”: { “#itemsOut”: 917, “#phaseSwitches”: 3671, “execTime”: “2.646892ms”, “kernTime”: “31.095431ms”, “servTime”: “19.781593ms” }, … “#operator”: “Fetch”, “#stats”: { “#itemsIn”: 917, “#itemsOut”: 917, “#phaseSwitches”: 3787, “execTime”: “3.43324ms”, “kernTime”: “20.847541ms”, “servTime”: “69.875698ms” }, … “#operator”: “Order”, “#stats”: { “#itemsIn”: 917, “#itemsOut”: 10, “#phaseSwitches”: 1849, “execTime”: “6.519061ms”, “kernTime”: “88.307572ms” }, |
There were 917 documentkeys returned by the indexer. The query engine fetched 917 documents. Then the sort (order) operator sorted them and returned the 10 items.
2. GET THE SECOND PAGE
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel–sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 10 LIMIT 10; |
In this case, everything is same as the query1 except:
- Sort (ORDER BY) operator will return 20 documents (offset + limit).
- The new OFFSET operator will execute after the Order operator and drop the first 10 rows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
“#operator”: “Order”, “#stats”: { “#itemsIn”: 917, “#itemsOut”: 20, “#phaseSwitches”: 1859, “execTime”: “6.485904ms”, “kernTime”: “65.92484ms” }, { “#operator”: “Offset”, “#stats”: { “#itemsOut”: 10, “#phaseSwitches”: 32, “execTime”: “5.071503ms”, “kernTime”: “701ns”, “state”: “running” }, “expr”: “10”, “#time_normal”: “00:00.0050”, “#time_absolute”: 0.005071503 }, |
As the OFFSET increases, the number of documents scanned by the sort will increase as well, consuming more memory and CPU.
- Let’s improve the performance by covering the predicate and sort keys with a single index.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ixtypectcy ON `travel–sample`(type, country, city); Let’s execute our recent query again: SELECT * FROM `travel–sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 10 LIMIT 10; |
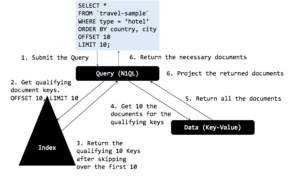
It uses the right index and creates the right filters (spans) for the index scan.Explain includes the following.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ “#operator”: “IndexScan2”, “index”: “ixtypectcy”, “index_id”: “2a2ed6573354e21”, “index_projection”: { “primary_key”: true }, “keyspace”: “travel-sample”, “limit”: “10”, “namespace”: “default”, “offset”: “10”, “spans”: [ { “exact”: true, “range”: [ { “high”: “”hotel“”, “inclusion”: 3, “low”: “”hotel“” } ] } ], |
Let’s look at the index scan operator efficiency with this index:
|
1 2 3 4 5 6 7 8 9 10 |
“#operator”: “IndexScan2”, “#stats”: { “#itemsOut”: 10, “#phaseSwitches”: 43, “execTime”: “41.786µs”, “kernTime”: “11.15µs”, “servTime”: “855.759µs” }, |
Only the required 10 document keys are returned from the index scan! The N1QL optimizer evaluates both the WHERE clause and the pagination (OFFSET, LIMIT) clause. The query optimizer decides to pushdown the pagination clause to the indexer based on the order by clause of the query and the index key order.
In this case, query predicate is: type = ‘hotel’
Order by clause is: ORDER BY country, city
Index key order is: (type, country, city)
Just by simple comparison, order by clause is not exactly the same as index key order. However, the leading key of the index (type) has an equality predicate (type = ‘hotel’). Therefore, the optimizer knows the projected document keys will be in the sorted order of (country and city).
**and the ORDER BY clause to see if it can pushdown the pagination parameters to the index scan. In this case, there is a perfect match.
The optimizer pushes both OFFSET and LIMIT in pagination to index scan and the index scan returns only the 10 document keys required no matter the OFFSET! Therefore, fetch only needs to fetch the 10 documents. Indexer does have to go through the index scan to evaluate the keys.
This query executed in about 6.81 milliseconds in my environment. Let’s paginate to subsequent pages to see the performance:
| OFFSET | LIMIT | Response Time |
| 10 | 10 | 6.81 ms |
| 20 | 10 | 7.17 ms |
| 100 | 10 | 7.02 ms |
| 400 | 10 | 9.54 ms |
| 800 | 10 | 9.08 ms |
If you want to paginate in the descending order, change the query and index to the following. The collation of the key in the index should match the collation in the query. In this case, both country and city are in DESCending order.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP INDEX `travel–sample`.ixtypectcy; CREATE INDEX ixtypectcy ON `travel–sample`(type, country DESC, city DESC); SELECT country, city FROM `travel–sample` WHERE type = “hotel” ORDER BY country DESC, city DESC OFFSET 10 LIMIT 10; |
0
Let’s now look at a query that’s not covered by the index. The query we saw earlier, we decide to retrieve the name of the hotel along with country and city. The name isn’t in the index.
1
In this case, again, the index has the data to cover the WHERE clause and the ORDER BY clause. The index scan will apply the predicate. The index order matches query order (note: there is only equality predicate on leading key. So, country and city are in order automatically). Index skips of the OFFSET number of qualified keys and returns the number of keys specified by the LIMIT clause. The engine retrieves the documents in order to maintain the order specified by ORDER BY clause.
All these little optimizations together ensure the query performance is consistent whether OFFSET is 10, 100 or 1000. The only overhead between higher OFFSET is the index scan skipping over the additional items. Index key evaluation and skipping is significantly faster than getting all the documents and sorting.
2
Let’s consider a longer running query with a potential of returning up to 24K documents.
create index idxtypeaiaid ON `travel-sample`(type, airline, airlineid)
Even when the pagination query predicates and order by is completely covered by the index, there is a limited number of cases where the pagination LIMIT and OFFSET can be pushed to the index scan in order to make this very efficient.
Here are general rules and requirements for pushing down OFFSET and LIMIT to the indexer. Note these rules are not exhaustive and complete but give you a sense of when this optimization is done.
- The query scan has to be on a single keyspace (Single reference in the FROM clause without JOINs.
- FROM
travel-samplet - FROM
travel-samplehotel INNER JOINtravel-samplelandmarks ON KEYS hotel.lmid
- FROM
Case (a) qualifies, and (b) does not.
- All the predicates in the query are pushed down to index scan (spans).
- We cannot push the predicates (col LIKE “%xyz”) to index scan. Therefore the pagination cannot be pushed down as well.
- All the predicates should be represented by a single span. If we have to do multiple index scans, post index scan processing (e.g. union scan, distinct scan in the explain), we cannot have the indexer evaluate the pagination. The query will execute without pushing the pagination clause to the index scan. Here are examples of predicate that generate single span.
- E.g. (a between 4 and 8 and a <> 12)
- (a = 5 OR a = 6)
- (a IN [4, 6, 9])
- All the predicates have to be exact.
- Exact predicates: (a = 5), (a between 9.8 and 9.99)
- Inexact predicates: (a > 5 and a > $param)
- The query cannot contain aggregation, grouping, having clauses. These do the document reduction after the After the should not eliminate any documents after the index scan (no post index scan filtering/reduction)
- The ORDER BY keys and the order of the keys should match the index key and index key order.
- CREATE INDEX i1 ON t(a, b, c);
- SELECT * FROM t WHERE a = 1 ORDER BY a, b, c;
- SELECT * FROM t WHERE a = 1 ORDER BY b, c;
- SELECT * FROM t WHERE a > 3 ORDER BY b, c
- SELECT * FROM t WHERE a > 3 ORDER BY a, b, c
- SELECT * FROM t WHERE (a LIKE “%xyz”) ORDER BY a, b, c OFFSET 10 LIMIT 5;
The case (2) is a perfect match of the order.
The case (3) doesn’t match perfectly, but the leading key has an equality filter. So, we know the results from the scan will be in the order of (b, c). Hence the pagination pushdown to the index is possible.
For the case (4), the leading key has a range predicate (a > 3) and therefore, t pagination pushdown is not possible.
For the case (5), there is a perfect match of the ORDER BY clause to the index keys. Therefore, we can push down the pagination to the indexer, even if there is range predicate on the leading key.
For the case (f), we can exploit the index order, but cannot push down the OFFSET and LIMIT because the complete predicate cannot be evaluated by the index scan. Since we get the results in the required order, after the OFFSET and LIMIT number of documents are projected, we terminate the index scan.
For simplicity, I’ve used one leading key. The statements are generalized and applicable to multiple leading keys.
Obviously, this optimizer logic is complex! See additional information in the appendix on the requirements.
OFFSET overhead:
The initial travel-sample has about 900 documents with (type = “hotel”). For experimentation, I simply increase the amount of data by inserting the same data again few times using the following query:
3
Now, let’s try this query:
4
| OFFSET | LIMIT | Response Time |
| 38000 | 10 | 28.97 ms |
As the OFFSET increases, the amount of time spent by the indexer to traverse through the index items increases. This affects both latency and throughput.
Can we improve this? Keyset pagination comes to the rescue. All the rules we mentioned for pagination optimization apply here as well. In addition, one of the predicates has to be UNIQUE so that we can clearly navigate from one page to another without duplicate documents appearing in multiple pages. With Couchbase, we’re in luck. Each document in a bucket has a unique document key. It’s referenced by META().id in the N1QL query.
The basic insight is, customers typically want the NEXT page instead of some random page from the start of the resultset. So, when you fetch each page in order, remember the last set (HIGHEST/LOWEST depending on the ORDER BY clause). Then, use that information to set the predicates and position the index for the next scan. This will avoid the wasted key processing during OFFSET.
Let’s look at an example:
CREATE INDEX ixtypectcy ON travel-sample (type, country, city, META().id);
- GET The FIRST PAGE. Note that I’ve added META().id to the index, projection and ORDER BY clause so it guarantees UNIQUE value in each of them.
5
Results:
6
This query ran in 5.14 milliseconds.
- Now, construct the query for next page WITHOUT using OFFSET:
7
How did we construct this query?
- Reuse all the predicates in the WHERE clause. (type = “hotel”).
- Now, take the keys in the ORDER BY and construct the additional predicates. So, simply take the highest value returned by the last query and add the new predicates. Don’t add the document key yet. In this case, we’re sorting in the ascending order. So, use the Greatherthan-OR-Equal-To operator.
In this case, it is: (country >= “France” AND city >= “Avignon”).
Now, to ensure unique value, we add the META().id predicate.
(META().id > “038c8a13-e1e7-4848-80ec-8819ff923602”)
This executes in 5 milliseconds with the following plan. As you go through the subsequent pages, simply repeat the steps to construct the next query and avoid the OFFSET. You can continue to go forever with similar response time!
8
SUMMARY:
You just learned how pagination works. You also learned how the Couchbase N1QL optimizer exploits the index to improve the efficiency of query pagination performance. You can use keyset pagination techniques to improve the performance of OFFSET further using the technique written.
References:
- https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- https://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/
Appendix: Optimize the query with order, offset, limit to exploit index ordering
Query ORDER BY evaluation can exploit the Index order with the indexer returning results in the required order and the query does not have to modify the order (e.g. does grouping,join). Whenever the order of record changes we need to use sort data to satisfy the ORDER BY clause.
- Index order will not be used when the from clause contains aggregates.
- Index order will not be used when GROUP BY clause present.
- Index order will not be used when JOINs, NEST, or UNNEST are used.
- Index order will not be used when DISTINCT is present.
- Index order will not be used when SET operators are used. This includes UNION, UNION ALL, INTERSECT, EXCEPT, EXCEPTALL.
- Index order will not be used when Primary Scan is involved.
- Index order will not be used when intersect or union scan is involved.
- Index order will not be used when Array Indexes are involved.
- Index order will not be used when order collation (ASC, DESC) doesn’t match with index collation.
- Index order will not be used when any order term is not matched with index keys.
- If Query exploits the Index order Order operator will not present in the EXPLAIN of the query.
OFFSET and LIMIT can be pushed to IndexScan
- when the ORDER BY is present and is able to exploit the index order
- When query ORDER BY is not present
- All the predicates are pushed to indexer as part of the spans
- Pushed spans values are exact
- Based on spans Indexer doesn’t generate false positives
- Query does not further reduce index scan results.
- If the OFFSET is pushed to indexer “offset” will appear in IndexScan section of the EXPLAIN and Offset Operator will not present at the end of the EXPLAIN.
- If the limit is pushed to indexer “limit” will appear in IndexScan section of the EXPLAIN.
Author
1 Comment
-
Hey Keshav, I am now implementing cursor pagination in couchbase, so thought I’ll take a log at this post, however, I implemented it differently than you, and wondering if I missed something.
In the example you used at the end:
SELECT country, city, META().id
FROMtravel-sampleuse index (ixtypectcy)
WHERE type = “hotel”
AND country >= “France”
AND city >= “Avignon”
AND META().id > “038c8a13-e1e7-4848-80ec-8819ff923602”
ORDER BY country, city, META().id
LIMIT 5;it looks like you skip many records since you filter on META().id > “038c8a13-e1e7-4848-80ec-8819ff923602”, however, you can have records that apply to country >= “France”
AND city >= “Avignon” with id smaller than “038c8a13-e1e7-4848-80ec-8819ff923602”
Leave a comment
You must be logged in to post a comment.