REpresentational State Transfer, commonly known as “REST”, describes a standard for programmatic communication with backend data services over the web.
A REST API is a programming interface that uses HTTP requests to POST (create), GET (read), PUT (update), and DELETE data (known as “CRUD operations”) via a basic URL endpoint similar to https://sample.com/api/products. Developers build apps that interact with the API via HTTP requests to the endpoint.
Think of REST API endpoints as encapsulations of queries that are exposed for developers to interact with a source of data. The abstraction of complexity makes using REST easy—it’s just a URL, but keep in mind that only those queries that the API authors have thought of and exposed are available to the masses, manipulating data beyond those queries requires programming.
Because of their simplicity, and the fact that nearly every major software solution offers REST access, leveraging REST APIs for data has become a popular approach to web app development.
Why REST in the first place?
REST APIs are a great option for many apps, especially those that are less complex with basic requirements for fetching and updating records.
For example, an app that shows “locations near me” for a retailer might pass user location coordinates to a REST endpoint such as “https://sample.com/api/locations/?=___”, which returns store addresses within a given radius of that location. All the information that the app needs for the “locations near me” feature is delivered via a simple GET call. For these types of reasons, REST is good when app data needs can be fulfilled with general access to entities.
But if your app requires more logic for data handling, such as those that frequently modify entities such as users, accounts or inventories, you probably need more granular control of the data than many REST APIs alone can provide. This forces developers into situations where they have to code around the limitations of REST to get the precise data that the app requires, doing things like filtering and merging data in code, which takes more time and inevitably erodes app efficiency.
What’s more, because the app is mobile you also need to contend with connectivity issues when relying on REST APIs over the web for data, not a trivial task.
This is where you will likely begin to hit the REST API pain points…
Pain points of using REST
Lack of schema and data type validation
Every REST API is built specific to the entities that it exposes, and therefore there is no standard protocol for schema validation or expected data types. This means developers must be aware of these details and work around them, or suffer the consequences in app instability and crashes.
For example, you could send a request for a list of products using “GET /products”, but there is no way to validate that the endpoint exists. This is especially troublesome when you use an endpoint that was available in previous versions of an API that is no longer available in newer versions.
And even if the endpoint exists, there’s no way to validate the entity details that it returns. For example, a given product in the returned list of products may have been modified or deleted by another client since the list was requested.
Data types can also differ for the same data between endpoints, depending on how each was implemented. For example, both of these endpoint requests will return the same data, but with slight differences:
| Request | Response |
| GET /products/123 | { Price: 10.95, Currency: “USD” } |
| GET /inventory/product/123 | { Price: “10.95”, Currency: “USD” } |
In this example one response returns the product price as a double, and the other returns the product price as a string. These are the sorts of data type mismatches that can cause apps to become unstable or crash.
Back-and-forth data transformation
Handling data types requires an endless cycle of transforming entity data into what each end of the connection expects. For example, for an app to leverage a REST API, the communication flow would look a bit like this:
|
|
| 2. Serialize data into JSON |
|
| 3. Transport via HTTP |
|
| 4. Decode data on backend |
|
| 5. CRUD operation on database |
|
Throughout the process flow, data is transformed time and time again as it passes from the database to the application and back. This is where there is the highest risk of a request or response containing data the other party is not expecting, leading to instability or crash. And the problem is only exacerbated by the lack of schema validation and strict data typing in REST.
Translating business domain logic to a to a simple transport model
If you develop following the domain model, you design entities carefully and intentionally to fit the product feature requirements and follow the business logic of the intended use cases for your app.
But, in order to leverage a REST API, you have to reimagine your carefully designed business domain in terms of CRUD operations on entities. What might be a single atomic action in your app – for example creating a new account – may actually require a series of multiple requests to the REST API.
As such, in order to leverage REST you need to wrap your model to fit the API, and in the process tend to lose the richness and expressiveness of your model.
Dealing with an inherently unreliable Internet
The first fallacy in the list of fallacies of distributed computing is The Network Is Reliable. L Peter Deutsch and his colleagues at Sun who authored the list, said this about apps that over-rely on a solid network connection:
“Software applications are written with little error-handling on networking errors. During a network outage, such applications may stall or infinitely wait for an answer packet, permanently consuming memory or other resources. When the failed network becomes available, those applications may also fail to retry any stalled operations or require a (manual) restart.”
If you use mobile apps regularly, and also change locations frequently, such as when commuting or traveling, you’ve no doubt experienced the frustration of internet dead-zones that affect those apps.
As a developer, how you handle network availability has huge implications on app UX. There are many potential points of failure introduced by network issues, and any number of ways to try and address them, but the bottom line is you have to implement the communication logic and error handling yourself, which can make even the simplest of tasks extremely complex.
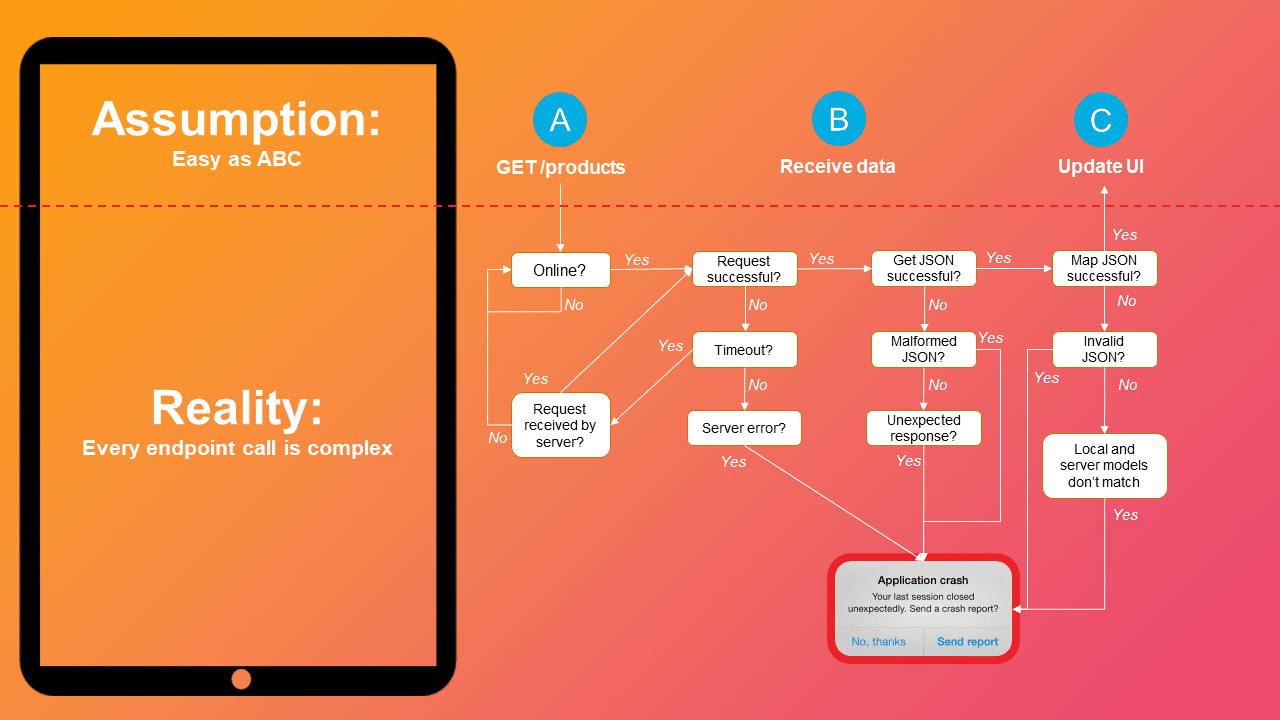
Consider this flowchart for requesting a list of products from a REST endpoint:
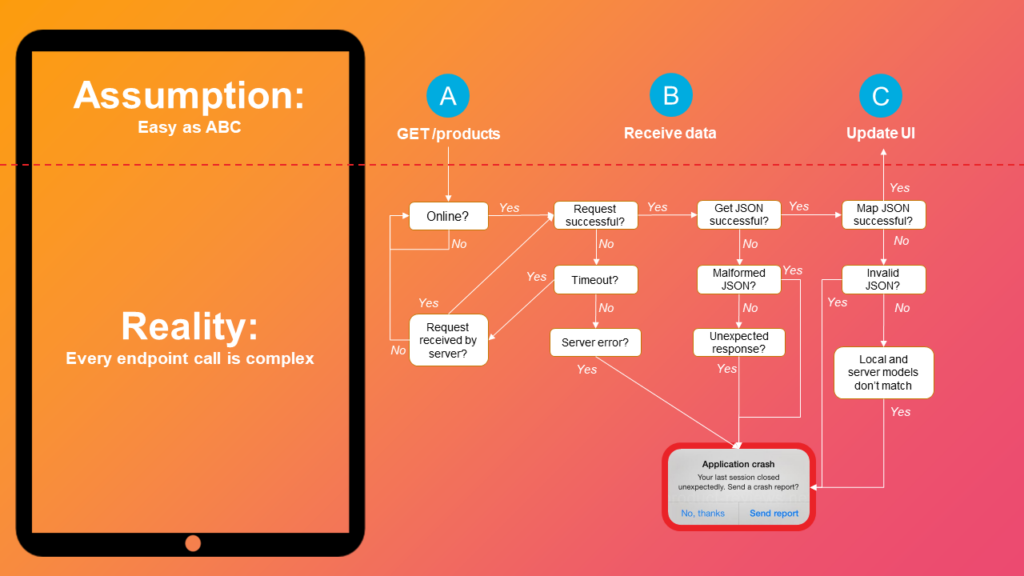
On initial app design, the action seems easy to achieve with REST: issue the request, get back the response, update the UI.
But the reality is, for each request there are a handful of possible states that have to be accounted for and handled, all starting with network availability. While the number of decision points may seem manageable at first glance, notice how many paths lead to failure, and this is just for a single request.
Now, consider that many actions in your app will require multiple dependent requests to be issued in rapid succession, each needing to traverse the decision points in the flowchart. Now multiply this process by the number of requests your app typically makes, and it becomes easy to see how this exponentially drives up the likelihood of a crash.
In this scenario, how do you recover if the last in a series of dependent requests fails? Do you retry the request until it succeeds? Do you roll back the previous requests in the series? Do you ignore the failure altogether? These are the sorts of development challenges that network dependencies can introduce.
Are the challenges of REST insurmountable? Well, no, but……
Talented developers can always figure out workarounds for issues and challenges. But this takes time and adds complexity to the app code, and it likely adds more resource consumption to the app’s operational footprint, slowing it down and making it consume more device battery life. The real question is not “how to get around the issue?”, it’s “at what cost?”
Micro-services can help automate repetitive tasks when using REST, and API authors are using increasingly creative means to deliver endpoints with GET parameters and custom POST JSON payloads, as well as endpoints that handle requests in bulk.
These sorts of approaches do address some of the headaches when using REST, but the pain points discussed in this post remain constant:
- Lack Of Schema And Data Type Validation
- Back-and-forth Data Transformation
- Translating Business Domain Logic To A Simple Transport Model
- Dealing With An Inherently Unreliable Internet
The Couchbase Mobile database platform
Couchbase Mobile solves the REST API pain points by eliminating the need to use REST for data altogether. It is a comprehensive data storage and sync solution for mobile and IoT apps that includes a cloud database for scale and resilience, an embedded database for on-device data processing that removes dependencies on a network for data access, and a data synchronization gateway that automatically syncs data changes between the backend database and other app clients for data consistency.

The Couchbase Mobile stack includes:
Couchbase Capella – A fully managed cloud NoSQL database-as-a-service (DBaaS) with SQL, search, analytics, and eventing support.
Capella App Services – Fully managed service for bidirectional sync, authentication, and access control for mobile and edge apps.
Couchbase Lite – An embedded mobile NoSQL database with support for SQL, built-in peer-to-peer sync, and broad mobile platform support, including iOS (Swift, Obj-C), Android (Java, Kotlin), Windows (C#, .NET), and custom embedded devices/IoT (C-API).
Capella App Services acts as the binding ingredient in the stack, providing websockets-based synchronization of data between the backend Capella database, edge data centers, and Couchbase Lite embedded apps on edge devices. The use of websockets arguably provides a superior means of data transport than REST for mobile apps with heavy loads of high volume data. With App Services, data changes are instantly and automatically replicated across the app ecosystem as connectivity allows, while during network disruptions, apps continue to operate thanks to the embedded Couchbase Lite database.
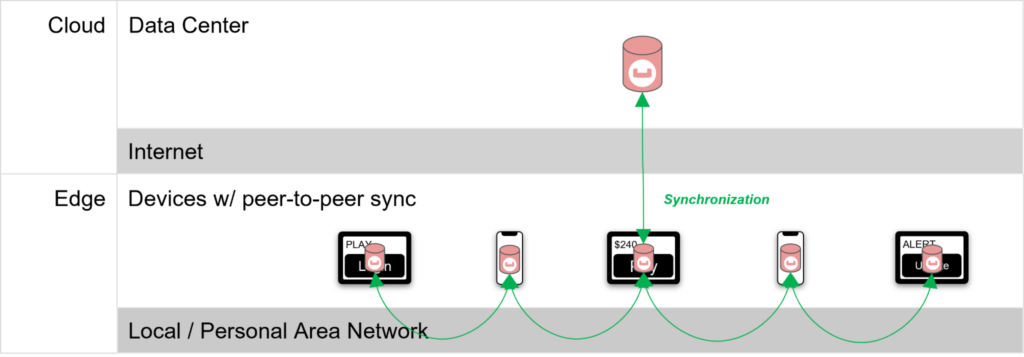
Couchbase Lite peer-to-peer sync
In addition to syncing data between the cloud and the edge via App Services, Couchbase Lite can also sync data peer-to-peer over local and personal area networks.
The Couchbase Lite Peer-to-Peer sync feature allows data to be synchronized directly between devices without a central control point, enabling collaboration in isolation where groups of devices running Couchbase Lite embedded apps can share data amongst themselves without regard for cloud access or internet connectivity. When internet connectivity does become available, Couchbase Lite clients can then sync to the cloud leveraging App Services.
The Couchbase advantage
Using Couchbase, you share the same data entities from the cloud database to the apps running on mobile devices, and you leverage a simple standard way to perform CRUD operations on that data: SQL. Because the data processing is embedded to your code, you no longer have to rely on networks for access, and you eliminate the need to transform data back-n-forth between the transport layer, the data layer and the UI.
With Couchbase you get:
Offline-first functionality – Apps work all the time thanks to the embedded local database, and changes are automatically synced to the cloud database and other app clients when there is network connectivity.
Easier development – Construct your business logic and work with data entities using your programming language of choice. No more limiting of your business domains to satisfy the requirements of a communication layer, and no more endless back-n-forth data transformations.
Rock-solid security – Couchbase Mobile provides authentication, role-based access control, AES 256 encryption at rest, and TLS 1.2 encryption on the wire.
End-to-end data sync – Don’t lose time building a caching feature, use an off-the-shelf data sync solution instead and free your team up to work on making the app front end the best it can be. Couchbase uses websockets, which is much more reliable and resilient than REST, to sync data instantly between the cloud and mobile devices, even across platforms.
Try Couchbase Mobile free
With Couchbase Mobile, you can remove the REST pain points from the equation, simplifying mobile app development, reducing dependencies on network connectivity, and improving the overall speed, efficiency and responsiveness of your app.
Don’t lose another minute of sleep using REST to build your mobile apps, get started with Couchbase for easier development, better performance, faster responsiveness and offline first functionality.
- Learn more about Couchbase Mobile here.
- See how Capella App Services offers hosted backend data sync here.
- Sign up for a FREE TRIAL of Couchbase Capella DBaaS and App Services here.
Leave a comment
You must be logged in to post a comment.