SUMMARY
A multi-model database is a single platform that stores and queries different types of data, allowing teams to avoid juggling multiple specialized systems. This approach makes it easier to build applications that rely on varied datasets, from customer profiles to real-time analytics. The rise of NoSQL and the demand for flexible, scalable architectures have driven the evolution of multi-model databases, which now combine models such as document, key-value, graph, and relational. These platforms offer capabilities such as unified querying, schema flexibility, integrated search, and strong performance across diverse workloads. As a result, multi-model databases are increasingly used to simplify infrastructure, support complex use cases, and accelerate the development of modern, data-driven applications.
What is a multi-model database?
A multi-model database is a platform that supports multiple data models, such as document, key-value, graph, relational, and more, within a single, unified engine. Unlike single-model databases that focus on one structure, multi-model databases allow organizations to store, manage, and query different types of data without relying on multiple systems. This flexibility allows teams to handle use cases ranging from real-time analytics and content management to recommendation engines and customer 360 views. By consolidating multiple models into one platform, multi-model databases reduce data silos, simplify architecture, and allow for more agile application development.
Continue reading this resource to explore the evolution of multi-model databases, how they differ from traditional databases, their capabilities, common use cases, potential challenges, and leading platforms in the market.
- A brief history of multi-model databases
- Multi-model database capabilities
- Multi-model databases vs. traditional databases
- Use cases for multi-model databases
- Multi-model database challenges
- Multi-model database examples
- Key takeaways and related resources
- FAQs
A brief history of multi-model databases
Multi-model databases materialized in response to the limitations of early relational systems, which struggled to handle growing, diverse data types. As web applications, mobile experiences, and real-time analytics became more demanding, businesses needed database architectures that could store and process structured, semi-structured, and unstructured data without the rigid schemas of traditional SQL databases. This shift led to the rise of NoSQL systems in the late 2000s, offering key-value, document, graph, and columnar data models for different use cases.
As NoSQL adoption grew, companies found they had to deploy multiple specialized databases to meet varying application requirements, leading to operational complexity and data fragmentation. To combat these challenges, multi-model databases evolved to integrate multiple NoSQL and sometimes relational data models into a single engine. By unifying document, key-value, graph, and search capabilities into a single platform, multi-model databases reduced the need for separate systems, improved developer productivity, and delivered the scalability required for distributed, cloud-native applications.
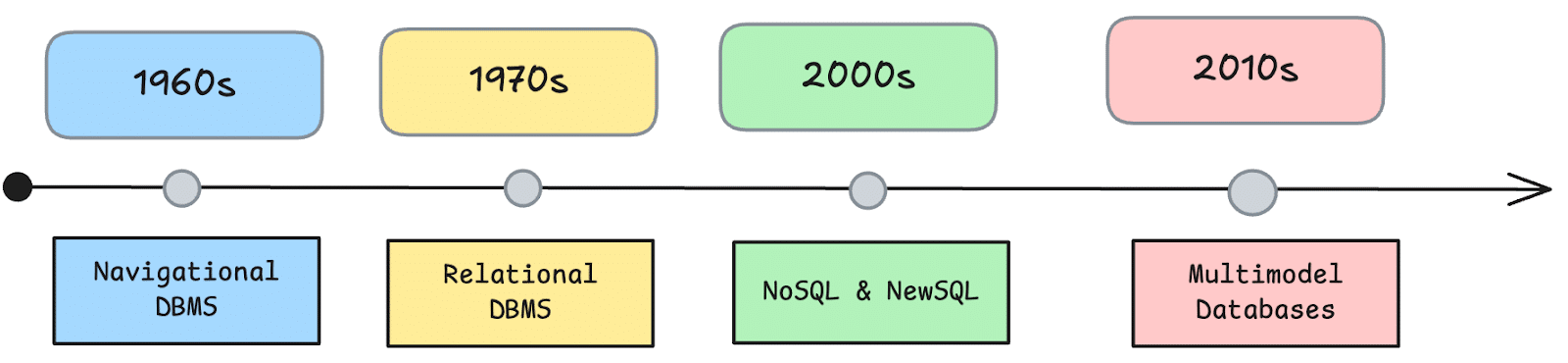
Timeline of database development
Multi-model database capabilities
Unlike traditional databases that specialize in one model, multi-model databases support multiple data types and models within a single, unified platform. By eliminating the need to integrate multiple specialized databases, they simplify development and make it easier for organizations to manage diverse, rapidly changing data. Here are some of the capabilities that make this possible:
- Support for multiple data models: Multi-model databases natively handle key-value, document, graph, relational, and sometimes time-series data in one system.
- Unified query engine: They allow developers and analysts to access and query data across models without switching tools or rewriting code.
- High performance and scalability: Optimized architectures support large-scale workloads and real-time use cases.
- Flexible schema management: Multi-model systems allow for structured, semi-structured, and unstructured data.
- Advanced indexing and search: They improve query speed and accuracy across different data types.
- Integrated analytics: These platforms support real-time and batch analytics directly within the database environment.
- Strong consistency and availability options: Multi-model databases balance performance and reliability based on application needs.
- Developer-friendly tooling: They provide SDKs, APIs, and integrations to simplify the development of modern, data-driven applications.
Multi-model databases vs. traditional databases
Multi-model databases and traditional databases handle and store data differently, which affects flexibility, performance, and scalability. Traditional databases typically focus on a single data model, such as relational, requiring separate systems to support additional formats. In contrast, multi-model databases consolidate multiple models into a single platform. Understanding the differences between the two helps organizations choose the right database for their data strategy. Here’s a comparison table to help simplify your decision:
| Aspect | Multi-model databases | Traditional databases |
|---|---|---|
| Data model support | Supports multiple models (document, key-value, graph, relational, etc.) in one system | Typically limited to one model (e.g., relational or key-value) |
| Flexibility | Adapts to changing data structures and diverse workloads | Requires rigid schemas and may need separate databases for different data types |
| Integration complexity | Simplifies architecture by reducing the need for multiple systems | Often needs external integration between different database types |
| Querying | Unified query layer supports multiple data models | Queries are designed for a specific data model |
| Performance | Optimized for diverse workloads with built-in scalability | May require additional scaling solutions or specialized systems |
| Development speed | Speeds up development by reducing the need to manage multiple platforms | Slower when working with diverse data sources |
| Use cases | Ideal for real-time analytics, complex applications, and hybrid workloads | Well suited for stable, structured, and transactional workloads |
| Cost and maintenance | Lowers operational overhead by consolidating systems | May require more resources to manage multiple specialized databases |
Use cases for multi-model databases
Multi-model databases are built to handle a variety of data types and workloads within a single platform, making them ideal for modern, data-intensive applications. Their ability to support multiple data models positions them well for industries and applications that demand both flexibility and high performance. Some of the specific ways organizations can use these platforms include:
- Real-time analytics: Combine structured and unstructured data to deliver fast, actionable insights without complex data pipelines.
- Customer 360 views: Unify customer data from multiple sources, such as CRM systems, web activity, and transactions, into a single, cohesive model.
- IoT and edge applications: Efficiently store and process high-velocity sensor data alongside relational metadata.
- Fraud detection and risk management: Use graph and document models together to identify complex relationships and detect anomalies in real time.
- Content management systems: Manage documents, metadata, and user interactions in a single environment without needing separate databases.
- E-commerce personalization: Leverage graph and key-value data to deliver personalized recommendations and improve user experience.
- Supply chain optimization: Integrate real-time tracking, logistics data, and transactional information for better visibility and business decisions.
Multi-model database challenges
While multi-model databases offer flexibility and performance advantages, they also introduce new complexities that organizations need to consider. Managing multiple data models within a single platform can create unique operational, architectural, and skill-related challenges. Understanding these potential pain points early on is essential for successful planning, implementation, and scaling.
Key challenges include:
- Operational complexity: Supporting multiple data models often requires more sophisticated configuration, maintenance, and monitoring.
- Performance tuning: Optimizing queries and workloads across different models can be more difficult than tuning a single-model database.
- Skill set requirements: Teams may need broader expertise to manage various data models, query languages, and indexing strategies.
- Integration with existing systems: Adopting a multi-model database may require rethinking data pipelines and application architectures.
- Cost and resource management: Running a single platform that supports multiple workloads can demand significant infrastructure and careful resource allocation.
- Vendor and ecosystem maturity: Not all multi-model solutions offer the same level of tooling, support, or community resources as traditional databases.
- Security and governance: Managing data protection, access controls, and compliance across multiple models adds additional layers of complexity.
While these challenges require thoughtful planning, they also present opportunities to build more resilient, scalable, and future-ready data systems. With the right strategy, skilled teams, and proper governance, organizations can turn these complexities into strengths.
Multi-model database examples
Here are some examples of multi-model platforms that simplify operations and give teams the freedom to build scalable applications:
- Couchbase: A distributed NoSQL database that supports document, key-value, and full-text search models, designed for high performance and real-time applications.
- ArangoDB: A native multi-model database that combines graph, document, and key-value data models with a single query language.
- OrientDB: A Java-based platform that blends graph and document models, often used for complex relationships and analytics.
- MarkLogic: An enterprise-grade database supporting document, graph, and relational data models, often used for large-scale data integration.
- Azure Cosmos DB: A globally distributed database service that supports multiple APIs and models, including key-value, document, and graph.
- Datastax Astra DB: A cloud-native platform built on Apache Cassandra that extends support to multiple data models for flexible application development.
Key takeaways and related resources
As data environments grow and change, multi-model databases have become a key tool for simplifying infrastructure and increasing agility. By combining multiple data models into a single platform, they’ve helped reduce the need for separate systems and made it easier to build fast, scalable applications. These databases have also helped organizations tap into value from their data that they may not have had insight into otherwise. Here are the most important takeaways about multi-model databases to remember from this guide:
Key takeaways
- Multi-model databases support multiple data models within a single engine, reducing the need to manage separate systems.
- They evolved from the limitations of traditional databases to meet demands for flexibility and scalability.
- Their core capabilities include unified querying, high performance, flexible schema management, and integrated analytics.
- Unlike traditional databases, multi-model platforms simplify architecture, improve agility, and support diverse workloads.
- They power use cases that range from real-time analytics and IoT to personalization and fraud detection.
- Challenges like operational complexity and performance tuning can be overcome with a well-thought-out strategy.
- Platforms like Couchbase, ArangoDB, and Azure Cosmos DB are shaping how organizations build modern applications.
To learn more about different types of databases, you can visit our concepts hub and review the resources listed below:
Related resources
- How Multimodel Databases Can Reduce Data Sprawl – Blog
- Updating Sensor Data: Exploring Couchbase’s Multi-Model Options – Blog
- Types of Databases – Concepts
- Six Types of Data Models (With Examples) – Blog
- NoSQL Explained: What It Is, How It Works & Why It Matters – Resources
FAQs
What types of data models can a multi-model database support? A multi-model database can natively handle document, key-value, graph, relational, and sometimes time-series data within a single platform.
How does a multi-model database handle performance and scalability? It uses optimized architectures, indexing, and built-in scalability features to manage diverse workloads and support high-performance applications.
Is a multi-model database suitable for enterprise applications? Yes, multi-model databases are well suited for enterprise applications that require flexibility, real-time analytics, and integration of multiple data types.
How does security work in a multi-model database? They provide comprehensive security features, including access controls, encryption, and compliance support, across all data models.
Can I easily migrate from a single-model database to a multi-model system? Migration is possible but typically requires planning, data mapping, and adjustments to queries or application logic to leverage multiple models effectively.
Start building
Check out our developer portal to explore NoSQL, browse resources, and get started with tutorials.
Use Capella free
Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.
Get in touch
Want to learn more about Couchbase offerings? Let us help.