Log forwarding and processing with Couchbase is easier than ever.
We have support for log forwarding and audit log management for both Couchbase Autonomous Operator (i.e., Kubernetes) and for on-prem Couchbase Server deployments. In both cases, log processing is powered by Fluent Bit.
Why did we choose Fluent Bit? Couchbase users need logs in a common format with dynamic configuration, and we wanted to use an industry standard with minimal overhead. Fluent Bit was a natural choice.
This article covers tips and tricks for making the most of using Fluent Bit for log forwarding with Couchbase. I’ll use the Couchbase Autonomous Operator in my deployment examples. (I’ll also be presenting a deeper dive of this post at the next FluentCon.)
Before Fluent Bit, Couchbase log formats varied across multiple files. Below is a single line from four different log files:
|
1 2 3 4 |
2021-03-09T17:32:25.520+00:00 DEBU CBAS.util.MXHelper [main] ignoring exception calling RuntimeMXBean.getBootClassPath; returning null java.lang.UnsupportedOperationException: Boot class path mechanism is not supported at sun.management.RuntimeImpl.getBootClassPath(Unknown Source) ~[?:?] at org.apache.hyracks.util.MXHelper.getBootClassPath(MXHelper.java:111) [hyracks-util.jar:6.6.0-7909] |
|
1 2 3 |
{"bucket":"default","description":"The specified bucket was selected","id":20492,"name":"select bucket","peername":"127.0.0.1:56021","real_userid":{"domain":"local","user":"@ns_server"},"sockname":"127.0.0.1:11209","timestamp":"2021-03-09T20:12:17.445039Z"} [ns_server:warn,2021-03-09T17:31:55.401Z,babysitter_of_ns_1@cb.local:ns_crash_log<0.102.0>:ns_crash_log:read_crash_log:148]Couldn't load crash_log from /opt/couchbase/var/lib/couchbase/logs/crash_log_v2.bin (perhaps it's first startup): {error, enoent} |
|
1 2 3 |
[error_logger:info,2021-03-09T17:31:55.401Z,babysitter_of_ns_1@cb.local:error_logger<0.32.0>:ale_error_logger_handler:do_log:203] =========================PROGRESS REPORT========================= supervisor: {local,ns_babysitter_sup} |
|
1 |
127.0.0.1 - @ [09/Mar/2021:17:32:02 +0000] "RPCCONNECT /goxdcr-cbauth HTTP/1.1" 200 0 - Go-http-client/1.1 |
With the upgrade to Fluent Bit, you can now live stream views of logs following the standard Kubernetes log architecture which also means simple integration with Grafana dashboards and other industry-standard tools. Below is a screenshot taken from the example Loki stack we have in the Fluent Bit repo.
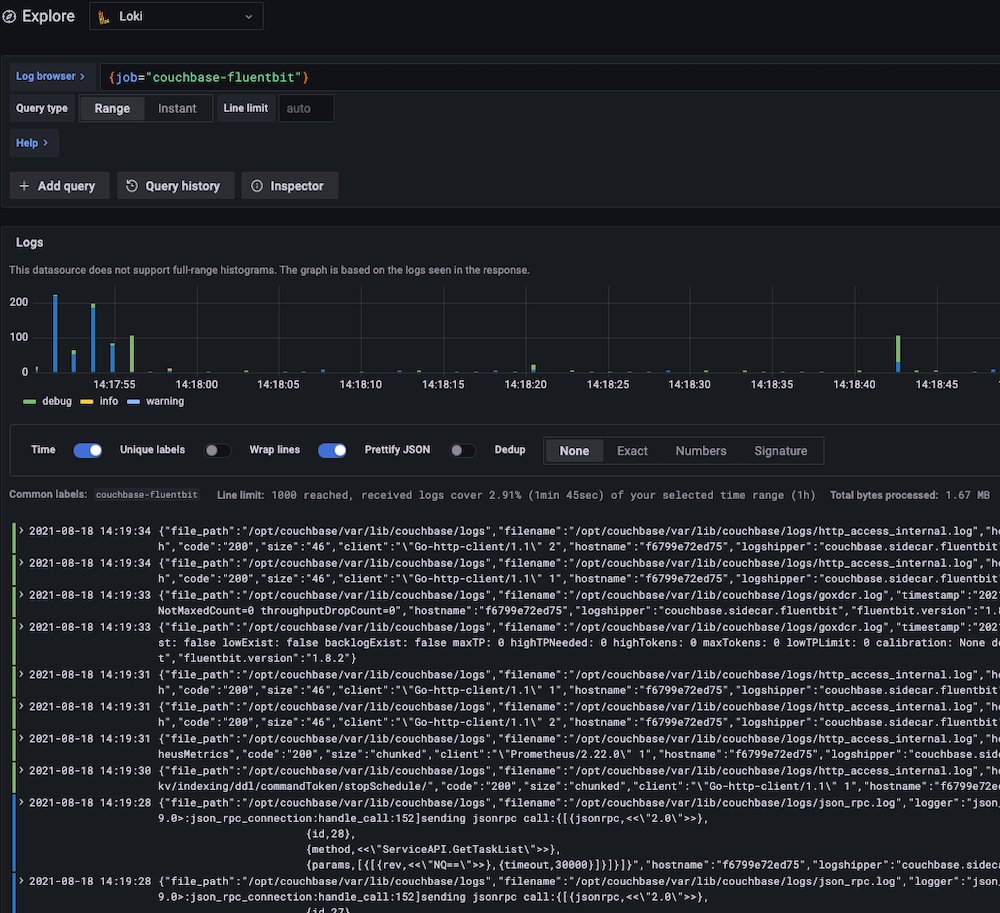
Whether you’re new to Fluent Bit or an experienced pro, I hope this article helps you navigate the intricacies of using it for log processing with Couchbase.
What’s Your Main Question or Challenge with Fluent Bit?
Skip directly to your particular challenge or question with Fluent Bit using the links below or scroll further down to read through every tip and trick.
How do I ask questions, get guidance or provide suggestions on Fluent Bit? Engage with and contribute to the OSS community.
How do I figure out what’s going wrong with Fluent Bit? Use the stdout plugin and up your log level when debugging.
How can I tell if my parser is failing? If you see the default log key in the record then you know parsing has failed.
Why is my regex parser not working? Verify and simplify, particularly for multi-line parsing.
How do I restrict a field (e.g., log level) to known values? Constrain and standardise output values with some simple filters.
How do I add optional information that might not be present? Use the record_modifier filter – not the modify filter – if you want to include optional information.
How do I identify which plugin or filter is triggering a metric or log message? Use aliases.
How do I complete special or bespoke processing (e.g., partial redaction)? Use the Lua filter: It can do everything!.
How do I check my changes or test if a new version still works? Provide automated regression testing.
How do I test each part of my configuration? Separate your configuration into smaller chunks. (Bonus: this allows simpler custom reuse).
How do I use Fluent Bit with Red Hat OpenShift?
I answer these and many other questions in the article below. Let’s dive in.
What Is (and Why) Fluent Bit?
So, what’s Fluent Bit? Fluent Bit is the daintier sister to Fluentd, which are both Cloud Native Computing Foundation (CNCF) projects under the Fluent organisation.
Fluent Bit essentially consumes various types of input, applies a configurable pipeline of processing to that input and then supports routing that data to multiple types of endpoints.
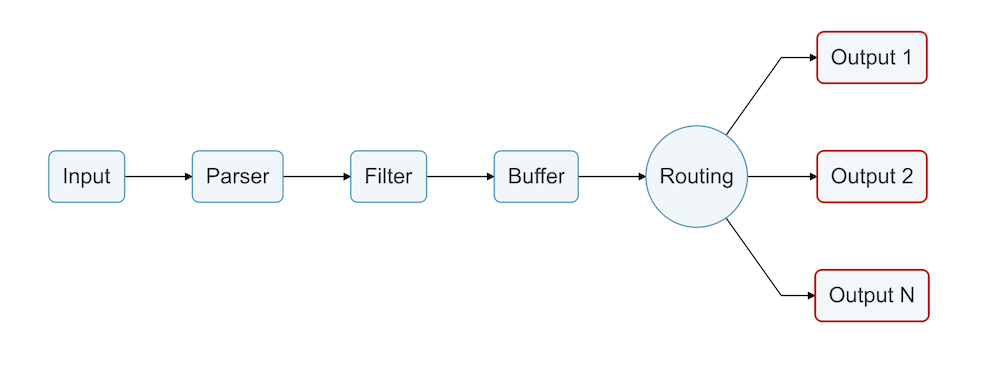
When it comes to Fluentd vs Fluent Bit, the latter is a better choice than Fluentd for simpler tasks, especially when you only need log forwarding with minimal processing and nothing more complex.
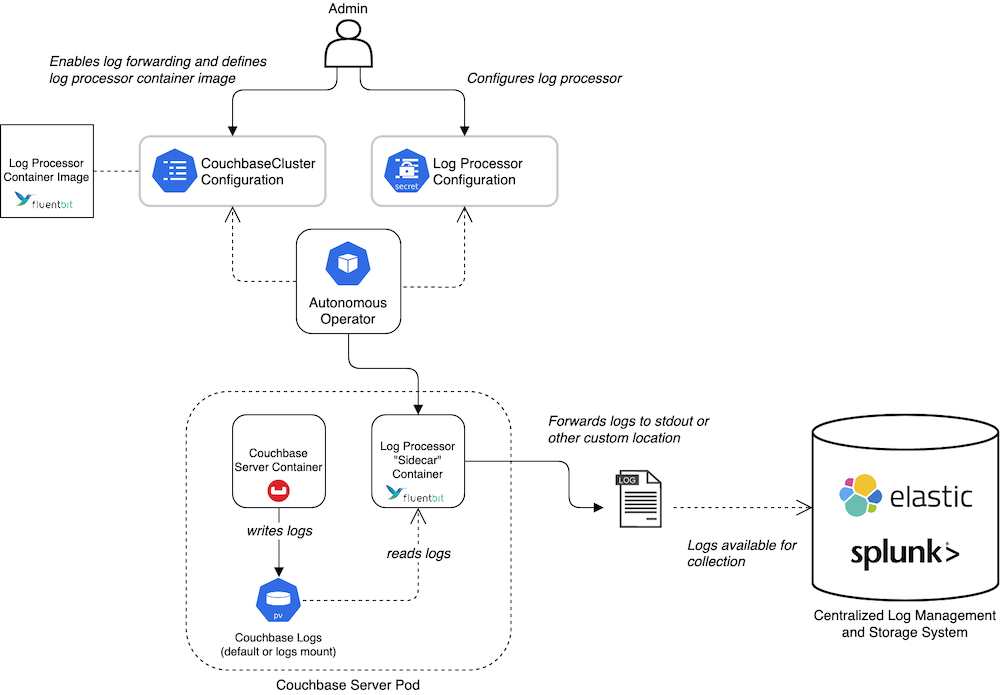
We had evaluated several other options before Fluent Bit, like Logstash, Promtail and rsyslog, but we ultimately settled on Fluent Bit for a few reasons. First, it’s an OSS solution supported by the CNCF and it’s already used widely across on-premises and cloud providers. Second, it’s lightweight and also runs on OpenShift. Third – and most importantly – it has extensive configuration options so you can target whatever endpoint you need.
(See my previous article on Fluent Bit or the in-depth log forwarding documentation for more info.)
Tip #1: Connect with the OSS Community
My first recommendation for using Fluent Bit is to contribute to and engage with its open source community.
Almost everything in this article is shamelessly reused from others, whether from the Fluent Slack, blog posts, GitHub repositories or the like. At the same time, I’ve contributed various parsers we built for Couchbase back to the official repo, and hopefully I’ve raised some helpful issues!
The Fluent Bit OSS community is an active one. Its maintainers regularly communicate, fix issues and suggest solutions. For example, FluentCon EU 2021 generated a lot of helpful suggestions and feedback on our use of Fluent Bit that we’ve since integrated into subsequent releases. (FluentCon is typically co-located at KubeCon events.)
Tip #2: Debugging When Everything Is Broken
In the Fluent Bit community Slack channels, the most common questions are on how to debug things when stuff isn’t working. My two recommendations here are:
- Use the
stdoutplugin. - Increase the log level for Fluent Bit.
My first suggestion would be to simplify. Most Fluent Bit users are trying to plumb logs into a larger stack, e.g., Elastic-Fluentd-Kibana (EFK) or Prometheus-Loki-Grafana (PLG). To start, don’t look at what Kibana or Grafana are telling you until you’ve removed all possible problems with plumbing into your stack of choice.
Use the stdout plugin to determine what Fluent Bit thinks the output is. Then, iterate until you get the Fluent Bit multiple output you were expecting. It’s a lot easier to start here than to deal with all the moving parts of an EFK or PLG stack.
My second debugging tip is to up the log level. This step makes it obvious what Fluent Bit is trying to find and/or parse. In many cases, upping the log level highlights simple fixes like permissions issues or having the wrong wildcard/path.
Considerations for Helm Health Checks
If you’re using Helm, turn on the HTTP server for health checks if you’ve enabled those probes.
Helm is good for a simple installation, but since it’s a generic tool, you need to ensure your Helm configuration is acceptable. If you enable the health check probes in Kubernetes, then you also need to enable the endpoint for them in your Fluent Bit configuration.
More recent versions of Fluent Bit have a dedicated health check (which we’ll also be using in the next release of the Couchbase Autonomous Operator).
Tip #3: Turning Water into Wine with Parsing
Usually, you’ll want to parse your logs after reading them. I use the tail input plugin to convert unstructured data into structured data (per the official terminology).
Failure Is Not an Option
When it comes to Fluent Bit troubleshooting, a key point to remember is that if parsing fails, you still get output. The Fluent Bit parser just provides the whole log line as a single record. This fall back is a good feature of Fluent Bit as you never lose information and a different downstream tool could always re-parse it.
One helpful trick here is to ensure you never have the default log key in the record after parsing. If you see the log key, then you know that parsing has failed. It’s not always obvious otherwise.
Tip #4: You Can’t Handle the (Multi-Line Parsing) Truth
Multi-line parsing is a key feature of Fluent Bit. Some logs are produced by Erlang or Java processes that use it extensively.
The goal with multi-line parsing is to do an initial pass to extract a common set of information. For Couchbase logs, we settled on every log entry having a timestamp, level and message (with message being fairly open, since it contained anything not captured in the first two).
The name of the log file is also used as part of the Fluent Bit tag. We implemented this practice because you might want to route different logs to separate destinations, e.g. the audit log tends to be a security requirement:
|
1 2 3 4 5 |
@include /fluent-bit/etc/fluent-bit.conf [OUTPUT] Name s3 Match couchbase.log.audit ... |
As shown above (and in more detail here), this code still outputs all logs to standard output by default, but it also sends the audit logs to AWS S3.
Let’s look at another multi-line parsing example with this walkthrough below (and on GitHub here):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[INPUT] Name tail Alias erlang_tail # ^See note 1 below Path ${COUCHBASE_LOGS}/babysitter.log,${COUCHBASE_LOGS}/couchdb.log,${COUCHBASE_LOGS}/debug.log,${COUCHBASE_LOGS}/json_rpc.log,${COUCHBASE_LOGS}/metakv.log,${COUCHBASE_LOGS}/ns_couchdb.log,${COUCHBASE_LOGS}/reports.log Multiline On Parser_Firstline couchbase_erlang_multiline Refresh_Interval 10 # ^See note 2 Skip_Long_Lines On # ^See note 3 Skip_Empty_Lines On # ^See note 4 Path_Key filename # ^See note 5 # We want to tag with the name of the log so we can easily send named logs to different output destinations. # This requires a bit of regex to extract the info we want. Tag couchbase.log. Tag_Regex ${COUCHBASE_LOGS}/(?[^.]+).log$ # ^See note 6 |
Notes:
[1] Specify an alias for this input plugin. This is really useful if something has an issue or to track metrics.
[2] The list of logs is refreshed every 10 seconds to pick up new ones.
[3] If you hit a long line, this will skip it rather than stopping any more input. Remember that Fluent Bit started as an embedded solution, so a lot of static limit support is in place by default.
[4] A recent addition to 1.8 was empty lines being skippable. This option is turned on to keep noise down and ensure the automated tests still pass.
[5] Make sure you add the Fluent Bit filename tag in the record. This is useful downstream for filtering.
[6] Tag per filename. In this case we use a regex to extract the filename as we’re working with multiple files.
One obvious recommendation is to make sure your regex works via testing. You can use an online tool such as:
-
- Rubular
- RegEx101
- Calyptia (Calyptia also has a visualiser tool, and I have a script to deal with included files to scrape it all into a single pastable file.)
It’s important to note that there are as always specific aspects to the regex engine used by Fluent Bit, so ultimately you need to test there as well. For example, make sure you name groups appropriately (alphanumeric plus underscore only, no hyphens) as this might otherwise cause issues.
Tip: If the regex is not working – even though it should – simplify things until it does.
The previous Fluent Bit multi-line parser example handled the Erlang messages, which looked like this:
|
1 2 |
[ns_server:info,2021-03-09T17:31:55.351Z,babysitter_of_ns_1@cb.local:<0.92.0>:ns_babysitter:init_logging:136]Brought up babysitter logging [ns_server:debug,2021-03-09T17:31:55.373Z,babysitter_of_ns_1@cb.local:<0.92.0>:dist_manager:configure_net_kernel:293]Set net_kernel vebosity to 10 -> 0 |
This snippet above only shows single-line messages for the sake of brevity, but there are also large, multi-line examples in the tests. Remember that the parser looks for the square brackets to indicate the start of each possibly multi-line log message:
|
1 2 3 4 5 6 7 |
[PARSER] Name couchbase_erlang_multiline Format regex Regex \[(?\w+):(?\w+),(?\d+-\d+-\d+T\d+:\d+:\d+.\d+Z),(?.*)$ Time_Key timestamp Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On |
Timestamp Parsing Complications & Considerations
Unfortunately, you can’t have a full regex for the timestamp field. If you have varied datetime formats, it will be hard to cope. For example, you can find the following timestamp formats within the same log file:
|
1 2 |
2021-03-09T17:32:15.545+00:00 [INFO] Using ... 2021/03/09 17:32:15 audit: ... |
At the time of the 1.7 release, there was no good way to parse timestamp formats in a single pass. So for Couchbase logs, we engineered Fluent Bit to ignore any failures parsing the log timestamp and just used the time-of-parsing as the value for Fluent Bit. The actual time is not vital, and it should be close enough.
Multi-format parsing in the Fluent Bit 1.8 series should be able to support better timestamp parsing. But as of this writing, Couchbase isn’t yet using this functionality. The snippet below shows an example of multi-format parsing:
|
1 2 3 4 5 6 7 8 9 10 |
# Cope with two different log formats, e.g.: # 2021/03/09 17:32:15 cbauth: ... # 2021-03-09T17:32:15.303+00:00 [INFO] ... # https://rubular.com/r/XUt7xQqEJnrF2M [PARSER] Name couchbase_simple_log_mixed Format regex Regex ^(?\d+(-|/)\d+(-|/)\d+(T|\s+)\d+:\d+:\d+(\.\d+(\+|-)\d+:\d+|))\s+((\[)?(?\w+)(\]|:))(?.*)$ Time_Key timestamp Time_Keep On |
Another thing to note here is that automated regression testing is a must!
Tip #5: Panning for Gold with Filtering
I’m a big fan of the Loki/Grafana stack, so I used it extensively when testing log forwarding with Couchbase.
One issue with the original release of the Couchbase container was that log levels weren’t standardized: you could get things like INFO, Info, info with different cases or DEBU, debug, etc. with different actual strings for the same level. This lack of standardization made it a pain to visualize and filter within Grafana (or your tool of choice) without some extra processing.
Based on a suggestion from a Slack user, I added some filters that effectively constrain all the various levels into one level using the following enumeration: UNKNOWN, DEBUG, INFO, WARN, ERROR. These Fluent Bit filters first start with the various corner cases and are then applied to make all levels consistent.
Here’s how it works: Whenever a field is fixed to a known value, an extra temporary key is added to it. This temporary key excludes it from any further matches in this set of filters. The temporary key is then removed at the end. See below for an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[FILTER] Name modify Alias handle_levels_uppercase_error_modify Match couchbase.log.* Condition Key_value_matches level (?i:ERRO\w*) Set level ERROR # Make sure we don't re-match it Condition Key_value_does_not_equal __temp_level_fixed Y Set __temp_level_fixed Y … # Remove all "temp" vars here [FILTER] Name modify Alias handle_levels_remove_temp_vars_modify Match couchbase.log.* Remove_regex __temp_.+ |
In the end, the constrained set of output is much easier to use.
Tip #6: How to Add Optional Information
One thing you’ll likely want to include in your Couchbase logs is extra data if it’s available.
For my own projects, I initially used the Fluent Bit modify filter to add extra keys to the record. However, if certain variables weren’t defined then the modify filter would exit.
I discovered later that you should use the record_modifier filter instead. This filters warns you if a variable is not defined, so you can use it with a superset of the information you want to include.
In summary: If you want to add optional information to your log forwarding, use record_modifier instead of modify.
I’ve included an example of record_modifier below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[FILTER] Name record_modifier Alias common_info_modifier Match couchbase.log.* Record hostname ${HOSTNAME} Record logshipper couchbase.sidecar.fluentbit # These should be built into the container Record couchbase.logging.version ${COUCHBASE_FLUENTBIT_VERSION} Record fluentbit.version ${FLUENTBIT_VERSION} # The following are set by the operator from the pod meta-data, they may not exist on normal containers Record pod.namespace ${POD_NAMESPACE} Record pod.name ${POD_NAME} Record pod.uid ${POD_UID} # The following come from kubernetes annotations and labels set as env vars so also may not exist Record couchbase.cluster ${couchbase_cluster} Record couchbase.operator.version ${operator.couchbase.com/version} Record couchbase.server.version ${server.couchbase.com/version} Record couchbase.node ${couchbase_node} Record couchbase.node-config ${couchbase_node_conf} Record couchbase.server ${couchbase_server} # These are config dependent so will trigger a failure if missing but this can be ignored Record couchbase.analytics ${couchbase_service_analytics} Record couchbase.data ${couchbase_service_data} Record couchbase.eventing ${couchbase_service_eventing} Record couchbase.index ${couchbase_service_index} Record couchbase.query ${couchbase_service_query} Record couchbase.search ${couchbase_service_search} |
I also use the Nest filter to consolidate all the couchbase.* and pod.* information into nested JSON structures for output. By using the Nest filter, all downstream operations are simplified because the Couchbase-specific information is in a single nested structure, rather than having to parse the whole log record for everything. This is similar for pod information, which might be missing for on-premise information.
Tip #7: Use Aliases
Another valuable tip you may have already noticed in the examples so far: use aliases.
When you use an alias for a specific filter (or input/output), you have a nice readable name in your Fluent Bit logs and metrics rather than a number which is hard to figure out. I recommend you create an alias naming process according to file location and function.
The Fluent Bit documentation shows you how to access metrics in Prometheus format with various examples.
Running with the Couchbase Fluent Bit image shows the following output instead of just tail.0, tail.1 or similar with the filters:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# HELP fluentbit_filter_drop_records_total Fluentbit metrics. # TYPE fluentbit_filter_drop_records_total counter fluentbit_filter_drop_records_total{name="common_info_modifier"} 0 1629194033696 fluentbit_filter_drop_records_total{name="couchbase_common_info_nest"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_filenames_add_missing_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_add_info_missing_level_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_add_unknown_missing_level_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_check_for_incorrect_level"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_remove_temp_vars_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_debug_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_error_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_info_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_warn_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_filename_in_log_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_message_unknown_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_msg_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_tail_filename_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_ts_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="parser.16"} 0 1629194033696 fluentbit_filter_drop_records_total{name="pod_common_info_nest"} 0 1629194033696 # HELP fluentbit_input_bytes_total Number of input bytes. # TYPE fluentbit_input_bytes_total counter fluentbit_input_bytes_total{name="audit_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="erlang_tail"} 691360 1629194033696 fluentbit_input_bytes_total{name="http_tail"} 4302 1629194033696 fluentbit_input_bytes_total{name="java_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="memcached_tail"} 10623 1629194033696 fluentbit_input_bytes_total{name="prometheus_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="rebalance_process_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="simple_mixed_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="simple_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="xdcr_tail"} 26544 1629194033696 |
And if something goes wrong in the logs, you don’t have to spend time figuring out which plugin might have caused a problem based on its numeric ID.
Another Consideration with Aliases
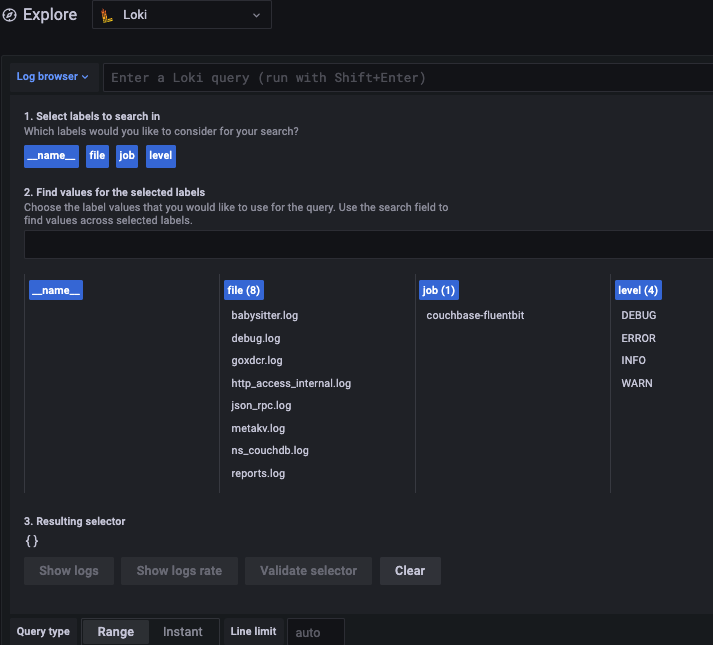
If you’re using Loki, like me, then you might run into another problem with aliases.
In my case, I was filtering the log file using the filename. While the tail plugin auto-populates the filename for you, it unfortunately includes the full path of the filename. But Grafana shows only the first part of the filename string until it is clipped off which is particularly unhelpful since all the logs are in the same location anyway.
The end result is a frustrating experience, as you can see below.
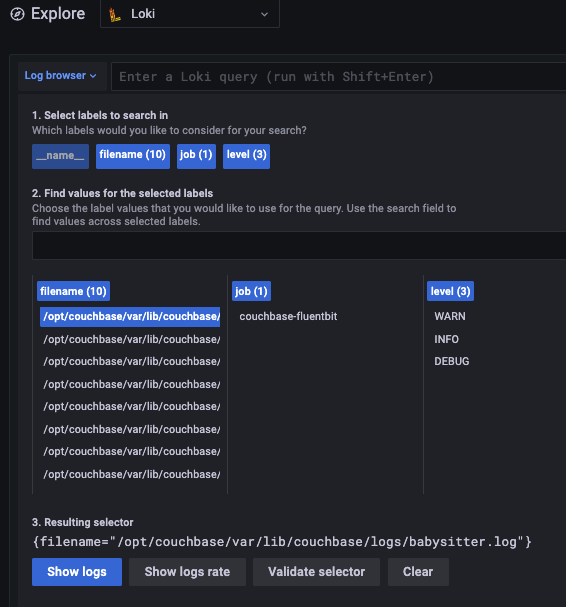
To solve this problem, I added an extra filter that provides a shortened filename and keeps the original too. This filter requires a simple parser, which I’ve included below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[PARSER] Name couchbase_filename_shortener Format regex Regex ^(?.*)/(?.*)$ [FILTER] Name parser Match couchbase.log.* Key_Name filename Parser couchbase_filename_shortener # Do not overwrite original field Preserve_Key On # Keep everything else Reserve_Data On |
With this parser in place, you get a simple filter with entries like audit.log, babysitter.log, etc. instead of full-path prefixes like /opt/couchbase/var/lib/couchbase/logs/.
Tip #8: Lua Filter: All Your (Couch)base Are Belong to Us
The Fluent Bit Lua filter can solve pretty much every problem. The question is, though, should it?
The Couchbase Fluent Bit image includes a bit of Lua code in order to support redaction via hashing for specific fields in the Couchbase logs. The goal of this redaction is to replace identifiable data with a hash that can be correlated across logs for debugging purposes without leaking the original information. Using a Lua filter, Couchbase redacts logs in-flight by SHA-1 hashing the contents of anything surrounded by <ud>..</ud> tags in the log message.
At FluentCon EU this year, Mike Marshall presented on some great pointers for using Lua filters with Fluent Bit including a special Lua tee filter that lets you tap off at various points in your pipeline to see what’s going on. It’s a generic filter that dumps all your key-value pairs at that point in the pipeline, which is useful for creating a before-and-after view of a particular field.
Tip #9: Test, Test and Test Again
Given all of these various capabilities, the Couchbase Fluent Bit configuration is a large one. Check out the image below showing the 1.1.0 release configuration using the Calyptia visualiser.
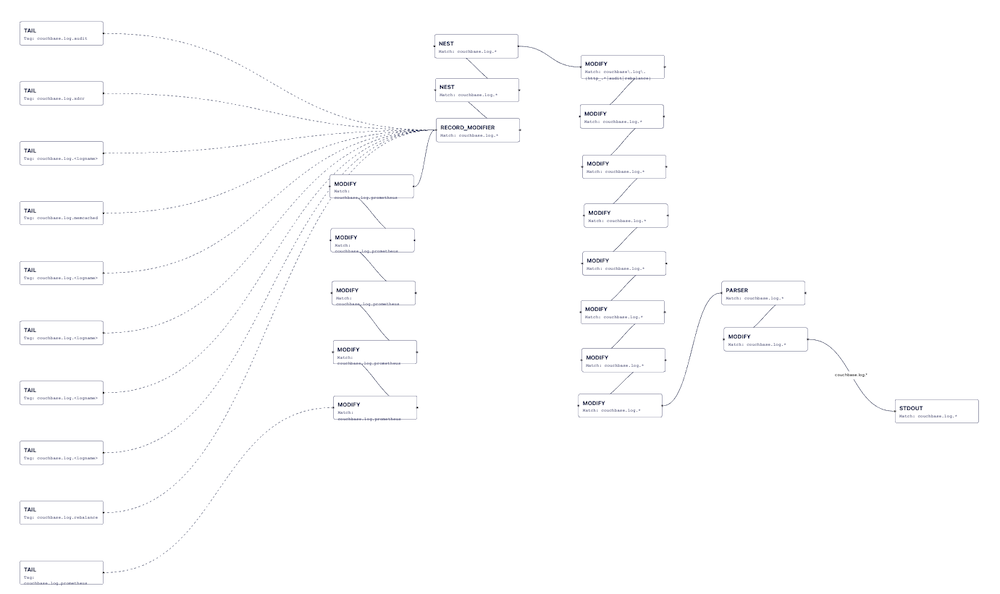
Given this configuration size, the Couchbase team has done a lot of testing to ensure everything behaves as expected. From all that testing, I’ve created example sets of problematic messages and the various formats in each log file to use as an automated test suite against expected output. I also built a test container that runs all of these tests; it’s a production container with both scripts and testing data layered on top. As the team finds new issues, I’ll extend the test cases.
These tools also help you test to improve output. For example, if you’re shortening the filename, you can use these tools to see it directly and confirm it’s working correctly.
Tip #10: Separate Your Areas of Concern
Each part of the Couchbase Fluent Bit configuration is split into a separate file. There’s one file per tail plugin, one file for each set of common filters, and one for each output plugin. I’ve engineered it this way for two main reasons:
- Simple reuse of different configurations
- Testing
Couchbase provides a default configuration, but you’ll likely want to tweak what logs you want parsed and how. You can just @include the specific part of the configuration you want, e.g. if you just want audit logs parsing and output then you can just include that only. There’s no need to write configuration directly, which saves you effort on learning all the options and reduces mistakes.
This split-up configuration also simplifies automated testing. For example, you can just include the tail configuration, then add a read_from_head to get it to read all the input. I’ve shown this below
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
cat > "$testConfig" << __FB_EOF @include /fluent-bit/test/conf/test-service.conf # Now we include the configuration we want to test which should cover the logfile as well. # We cannot exit when done as this then pauses the rest of the pipeline so leads to a race getting chunks out. # https://github.com/fluent/fluent-bit/issues/3274 # Instead we rely on a timeout ending the test case. @include $i Read_from_head On @include /fluent-bit/test/conf/test-filters.conf @include /fluent-bit/test/conf/test-output.conf __FB_EOF |
One warning here though: make sure to also test the overall configuration together. I recently ran into an issue where I made a typo in the include name when used in the overall configuration. Adding a call to --dry-run picked this up in automated testing, as shown below:
|
1 |
if "${COUCHBASE_LOGS_BINARY}" --dry-run --config="$i"; then |
This validates that the configuration is correct enough to pass static checks. Keep in mind that there can still be failures during runtime when it loads particular plugins with that configuration. In those cases, increasing the log level normally helps (see Tip #2 above).
Expect the Unexpected during Testing
When you’re testing or troubleshooting in Fluent Bit, it’s important to remember that every log message should contain certain fields (like message, level, and timestamp) and not others (like log).
This distinction is particularly useful when you want to test against new log input but do not have a golden output to diff against. For example, when you’re testing a new version of Couchbase Server and it’s producing slightly different logs. My recommendation is to use the Expect plugin to exit when a failure condition is found and trigger a test failure that way.
Unfortunately Fluent Bit currently exits with a code 0 even on failure, so you need to parse the output to check why it exited. You should also run with a timeout in this case rather than an exit_when_done. Otherwise, you’ll trigger an exit as soon as the input file reaches the end which might be before you’ve flushed all the output to diff against:
|
1 2 3 4 |
timeout -s 9 "${EXPECT_TEST_TIMEOUT}" "${COUCHBASE_LOGS_BINARY}" --config "$testConfig" > "$testLog" 2>&1 # Currently it always exits with 0 so we have to check for a specific error message. # https://github.com/fluent/fluent-bit/issues/3268 if grep -iq -e "exception on rule" -e "invalid config" "$testLog" ; then |
I also have to keep the test script functional for both Busybox (the official Debug container) and UBI (the Red Hat container) which sometimes limits the Bash capabilities or extra binaries used.
Tip #11: How to Use Fluent Bit with Red Hat OpenShift
There is a Couchbase Autonomous Operator for Red Hat OpenShift which requires all containers to pass various checks for certification. One of these checks is that the base image is UBI or RHEL.
The Couchbase team uses the official Fluent Bit image for everything except OpenShift, and we build it from source on a UBI base image for the Red Hat container catalog. We build it from source so that the version number is specified, since currently the Yum repository only provides the most recent version. Plus, it’s a CentOS 7 target RPM which inflates the image if it’s deployed with all the extra supporting RPMs to run on UBI 8.
There’s an example in the repo that shows you how to use the RPMs directly too.
Conclusion
I hope these tips and tricks have helped you better use Fluent Bit for log forwarding and audit log management with Couchbase.
We chose Fluent Bit so that your Couchbase logs had a common format with dynamic configuration. We also wanted to use an industry standard with minimal overhead to make it easy on users like you.
If you’re interested in learning more, I’ll be presenting a deeper dive of this same content at the upcoming FluentCon. I hope to see you there.
Download Couchbase Server 7 today
