En parte 1 vimos cómo scrapear Twitter, convertir tweets en documentos JSON, obtener una representación incrustada de ese tweet, almacenarlo todo en Couchbase y cómo ejecutar una búsqueda vectorial. Estos son los primeros pasos de una arquitectura de Generación Aumentada de Recuperación que podría resumir un hilo de Twitter. El siguiente paso es utilizar un Modelo de Lenguaje Grande. Podemos pedirle que resuma el hilo, y podemos enriquecer el contexto de la petición gracias a la Búsqueda Vectorial.
LangChain y Streamlit
Entonces, ¿cómo hacer que todo esto funcione con un LLM? Ahí es donde el proyecto LangChain puede ayudar. Su objetivo es permitir a los desarrolladores crear aplicaciones basadas en LLM. Ya tenemos algunos ejemplos disponibles en GitHub que muestran nuestro módulo LangChain. Como esta demo de RAG que permite al usuario subir un PDF, vectorizarlo, almacenarlo en Couchbase y utilizarlo en un chatbot. Ese está en JavaScript, pero también hay un Versión Python.
Resulta que esto es exactamente lo que quiero hacer, salvo que utiliza un PDF en lugar de una lista de tweets. Así que lo bifurqué y empezó a jugar con él aquí. Aquí, Nithish está usando un par de librerías interesantes, LangChain por supuesto, y Streamlit. ¡Otra cosa interesante que aprender! Streamlit es como un PaaS, código reducido y ciencia de datos servicio. Permite desplegar aplicaciones basadas en datos muy fácilmente, con un mínimo de código, de una forma muy, muy opinable.
Configuración
Vamos a dividir el código en trozos más pequeños. Podemos empezar con la configuración. El siguiente método se asegura de que las variables de entorno correctas están configuradas, y detiene el despliegue de la aplicación si no lo están.
En comprobar_variable_entorno es llamado varias veces para asegurarse de que se ha establecido la configuración necesaria, y si no se detendrá la aplicación.
|
1 2 3 4 5 |
def comprobar_variable_entorno(nombre_variable): """Comprobar si la variable de entorno está establecida""" si nombre_variable no en os.environ: st.error(f"La variable de entorno {variable_name} no está configurada. Por favor, añádala al archivo secrets.toml") st.stop() |
|
1 2 3 4 5 6 7 8 |
comprobar_variable_entorno("OPENAI_API_KEY") # La clave de la API OpenApi que he creado y utilizado anteriormente comprobar_variable_entorno("DB_CONN_STR") # Una cadena de conexión para conectarse a Couchbase, como couchbase://localhost o couchbases://cb.abab-abab.cloud.couchbase.com comprobar_variable_entorno("DB_USERNAME) # Nombre de usuario comprobar_variable_entorno("DB_PASSWORD") # Y contraseña para conectarse a Couchbase comprobar_variable_entorno("DB_BUCKET") # El nombre del bucket que contiene nuestros ámbitos y colecciones comprobar_variable_entorno("DB_SCOPE") Ámbito # comprobar_variable_entorno("DB_COLLECTION") # y el nombre de la colección, se puede pensar en una colección como una tabla en RDBMS comprobar_variable_entorno("INDEX_NAME") # Nombre del índice del vector de búsqueda |
Esto significa que todo lo que hay ahí es necesario. Una conexión a OpenAI y a Couchbase. Hablemos rápidamente de Couchbase. Es un JSON, base de datos distribuida multi-modelo con una caché integrada. Puedes usarla como K/V, SQL, Búsqueda de texto completo, Series temporales, Analítica, y hemos añadido fantásticas nuevas características en 7.6: CTEs recursivas para hacer consultas gráficas, o la que más nos interesa hoy, Búsqueda vectorial. La forma más rápida de probarlo es ir a nube.couchbase.comHay un periodo de prueba de 30 días, sin necesidad de tarjeta de crédito.
A partir de ahí puedes seguir los pasos y configurar tu nuevo cluster. Configura un bucket, scope, collection e index, un usuario y asegúrate de que tu cluster está disponible desde el exterior y podrás pasar a la siguiente parte. Conseguir una conexión a Couchbase desde la app. Se puede hacer con estas dos funciones. Puedes ver que están anotadas con @st.cache_resource. Se utiliza para almacenar en caché el objeto desde la perspectiva de Streamlit. Lo hace disponible para otras instancias o repeticiones. Aquí está el extracto del documento
Decorador para almacenar en caché funciones que devuelven recursos globales (por ejemplo, conexiones a bases de datos, modelos ML).
Los objetos almacenados en caché se comparten entre todos los usuarios, sesiones y repeticiones. Deben ser seguros porque se puede acceder a ellos desde varios subprocesos simultáneamente. Si la seguridad de los subprocesos es un problema, considere el uso de st.session_state para almacenar recursos por sesión.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
de langchain_community.vectorstores importar CouchbaseVectorStore de langchain_openai importar OpenAIEmbeddings @st.recurso_cache(show_spinner="Conectarse a Vector Store") def get_vector_store( _cluster, db_bucket, db_scope, db_collection, _embedding, nombre_índice, ): """Devolver el almacén vectorial Couchbase""" vector_store = CouchbaseVectorStore( grupo=_cluster, nombre_cubo=db_bucket, nombre_ámbito=db_scope, nombre_colección=db_collection, incrustación=_embedding, nombre_índice=nombre_índice, texto_clave ) devolver vector_tienda @st.recurso_cache(show_spinner="Conexión a Couchbase") def connect_to_couchbase(cadena_de_conexión, db_username, db_contraseña): """Conectarse a couchbase"""" de couchbase.grupo importar Grupo de couchbase.auth importar PasswordAuthenticator de couchbase.opciones importar ClusterOptions de datetime importar timedelta auth = PasswordAuthenticator(db_username, db_contraseña) opciones = ClusterOptions(auth) conectar_cadena = cadena_de_conexión grupo = Grupo(conectar_cadena, opciones) # Espere hasta que el clúster esté listo para su uso. grupo.wait_until_ready(timedelta(segundos=5)) devolver grupo |
Así que con esto tenemos una conexión al clúster Couchbase y una conexión a la envoltura del almacén vectorial LangChain Couchbase.
connect_to_couchbase(connection_string, db_username, db_password) crea la conexión al cluster Couchbase. get_vector_store(_cluster, db_bucket, db_scope, db_collection, _embedding, index_name,) crea el CouchabseVectorStore wrapper. Contiene una conexión al clúster, la información del bucket/ámbito/colección para almacenar los datos, el nombre del índice para asegurarnos de que podemos consultar los vectores, y una propiedad de incrustación.
Aquí se refiere a la función OpenAIEmbeddings. Recogerá automáticamente el OPENAI_API_KEY y permitir a LangChain utilizar la API de OpenAI con la clave. Cada llamada a la API será transparente para LangChain. Lo que también significa que cambiar de proveedor de modelos debería ser bastante transparente a la hora de gestionar la incrustación.
Escribir documentos LangChain en Couchbase
Ahora, donde ocurre la magia, donde obtenemos los tweets, los parseamos como JSON, creamos la incrustación y escribimos el documento JSON en la colección específica de Couchbase. Gracias a Steamlit podemos configurar un widget de subida de archivos y ejecutar una función asociada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
importar archivo temporal importar os de langchain.docstore.documento importar Documento def save_tweet_to_vector_store(archivo_cargado, vector_store): si archivo_cargado es no Ninguno: datos = json.carga(archivo_cargado) # Analiza el archivo cargado en JSON, esperando un array de objetos docs = [] ids = [] para tuitee en datos: # Para todos los tweets JSON texto = tuitee[texto] texto_completo = tuitee[texto_completo] id = tuitee[id] # Crear el Documento Langchain, con un campo de texto y metadatos asociados. si texto_completo es no Ninguno: doc = Documento(contenido_página=texto_completo, metadatos=tuitee) si no: doc = Documento(contenido_página=texto, metadatos=tuitee) docs.añadir(doc) ids.añadir(id) # Crear una matriz similar para Couchbase doc IDs, si no se proporciona, uuid se generará automáticamente vector_store.añadir_documentos(documentos = docs, ids = ids) # Almacenar todos los documentos e incrustaciones st.información(f"tweet y respuestas cargados en almacén vectorial en {len(docs)} documentos") |
Parece algo similar al código de la parte 1, excepto que toda la creación de la incrustación es gestionada de forma transparente por LangChain. El campo de texto será vectorizado, los metadatos serán añadidos al doc de Couchbase. Se verá así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "texto": "@kelseyhightower ¡CALCETINES! Tiraré millones de dólares a la primera empresa que me ofrezca calcetines: ¡No tengo millones de dólares! \Creo que tengo un problema"., "incrustación": [ -0.0006439118069540552, -0.021693240183757154, 0.026031888593037636, -0.020210755239867904, -0.003226784468532888, ....... -0.01691936794757287 ], "metadatos": { "fecha_creada": "Thu Apr 04 16:15:02 +0000 2024", "id": "1775920020377502191", "texto_completo": null, "texto": "@kelseyhightower ¡CALCETINES! Tiraré millones de dólares a la primera empresa que me ofrezca calcetines: ¡No tengo millones de dólares! \Creo que tengo un problema"., "lang": "es", "in_reply_to": "1775913633064894669", "quote_count": 1, "reply_count": 3, "cuenta_favoritos": 23, "view_count": "4658", "hashtags": [], "usuario": { "id": "4324751", "nombre": "Josh Long", "nombre_de_pantalla": "starbuxman", " url ": "https://t.co/PrSomoWx53" } } |
A partir de ahora tenemos funciones para gestionar la subida de tweets, vectorizar los tweets y almacenarlos en Couchbase. Es hora de utilizar Streamlit para construir la aplicación real y gestionar el flujo de chat. Vamos a dividir esa función en varios trozos.
Escribir una aplicación Streamlit
Empezando por la declaración principal y la protección de la app. No quieres que nadie la use, y usar tus créditos OpenAI. Gracias a Streamlit se puede hacer con bastante facilidad. Aquí configuramos una protección por contraseña usando el LOGIN_PASSWORD env. Y también configuramos la página global gracias a la variable set_page_config método. Esto le dará un simple formulario para introducir la contraseña, y una simple página.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
si nombre == "__main__": # Autorización si "auth" no en st.estado_sesión: st.estado_sesión.auth = Falso st.set_page_config( título_página="Chatea con una exportación de tuits usando Langchain, Couchbase y OpenAI", page_icon="🤖", diseño="centrado", initial_sidebar_state="auto", elementos_menú=Ninguno, ) AUTH = os.getenv("LOGIN_PASSWORD") comprobar_variable_entorno("LOGIN_PASSWORD") Autenticación # usuario_pwd = st.entrada_texto("Introducir contraseña", tipo="contraseña") pwd_submit = st.botón("Enviar") si pwd_submit y usuario_pwd == AUTH: st.estado_sesión.auth = Verdadero elif pwd_submit y usuario_pwd != AUTH: st.error("Contraseña incorrecta") |
Para ir un poco más allá podemos añadir las comprobaciones de variables de entorno, la configuración de OpenAI y Couchbase, y un simple título para iniciar el flujo de la app.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
si st.estado_sesión.auth: # Cargar variables de entorno DB_CONN_STR = os.getenv("DB_CONN_STR") NOMBRE DE USUARIO DE BASE DE DATOS = os.getenv("DB_USERNAME) DB_PASSWORD = os.getenv("DB_PASSWORD") DB_BUCKET = os.getenv("DB_BUCKET") DB_SCOPE = os.getenv("DB_SCOPE") DB_COLECCIÓN = os.getenv("DB_COLLECTION") NOMBRE_DEL_ÍNDICE = os.getenv("INDEX_NAME") # Asegúrese de que todas las variables de entorno están configuradas comprobar_variable_entorno("OPENAI_API_KEY") comprobar_variable_entorno("DB_CONN_STR") comprobar_variable_entorno("DB_USERNAME) comprobar_variable_entorno("DB_PASSWORD") comprobar_variable_entorno("DB_BUCKET") comprobar_variable_entorno("DB_SCOPE") comprobar_variable_entorno("DB_COLLECTION") comprobar_variable_entorno("INDEX_NAME") # Utilizar OpenAI Embeddings incrustación = OpenAIEmbeddings() # Conectarse al almacén vectorial Couchbase grupo = connect_to_couchbase(DB_CONN_STR, NOMBRE DE USUARIO DE BASE DE DATOS, DB_PASSWORD) vector_store = get_vector_store( grupo, DB_BUCKET, DB_SCOPE, DB_COLECCIÓN, incrustación, NOMBRE_DEL_ÍNDICE, ) st.título("Chatear con X") |
Streamlit tiene una buena integración de espacio de código, realmente te animo a usarlo, hace que el desarrollo sea realmente fácil. Y nuestro plugin VSCode puede ser instalado, para que puedas navegar por Couchbase y ejecutar consultas.
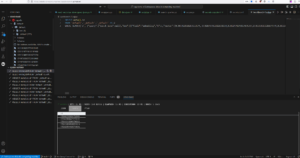
Ejecutar consulta de búsqueda vectorial SQL++ desde el espacio de código
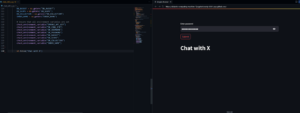
Una aplicación Basic Streamlit abierta en Codespace
Crear cadenas LangChain
Después viene la configuración de la cadena. Aquí es donde LangChain brilla. Aquí es donde podemos configurar la retriever. Va a ser utilizado por LangChain para consultar Couchbase para todos los tweets vectorizados. Entonces es el momento de construir el prompt RAG. Puedes ver que la plantilla toma un {contexto} y {pregunta} parámetro. Creamos un objeto Chat prompt a partir de la plantilla.
Después viene la elección del LLM, aquí elegí GPT4. Y por último la creación de la cadena.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Utilizar el almacén de vectores couchbase como recuperador para RAG retriever = vector_store.as_retriever() # Construye el prompt para el RAG plantilla = """Eres un bot de ayuda. Si no puedes responder basándote en el contexto proporcionado, responde con una respuesta genérica. Responde a la pregunta con la mayor sinceridad posible utilizando el contexto que se indica a continuación: {contexto} Pregunta: {pregunta}""" consulte = ChatPromptTemplate.desde_plantilla(plantilla) # Utilizar OpenAI GPT 4 como LLM para el GAR llm = ChatOpenAI(temperatura=0, modelo="gpt-4-1106-preview", streaming=Verdadero) # Cadena RAG cadena = ( {"contexto": retriever, "pregunta": RunnablePassthrough()} | consulte | llm | StrOutputParser() ) |
La cadena se construye a partir del modelo elegido, el contexto y los parámetros de consulta, el objeto prompt y un objeto StrOuptutParser. Su función es analizar la respuesta LLM y enviarla de vuelta como una cadena streamable/chunkable. La dirección RunnablePassthrough llamado para el parámetro de la pregunta se utiliza para asegurarse de que se pasa al prompt 'tal cual' pero puedes utilizar otros métodos para cambiar/sanitizar la pregunta. Eso es todo, una arquitectura RAG. Dando un contexto adicional a una pregunta LLM para obtener una mejor respuesta.
También podemos construir una cadena sin él para comparar los resultados:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Salida OpenAI pura sin RAG plantilla_sin_arrastre = """Eres un bot muy útil. Responde a la pregunta con la mayor sinceridad posible. Pregunta: {pregunta}""" prompt_without_rag = ChatPromptTemplate.desde_plantilla(plantilla_sin_arrastre) llm_without_rag = ChatOpenAI(modelo="gpt-4-1106-preview") cadena_sin_arrastre = ( {"pregunta": RunnablePassthrough()} | prompt_without_rag | llm_without_rag | StrOutputParser() ) |
No hay necesidad de contexto en la plantilla de consulta y el parámetro de cadena, y no hay necesidad de un recuperador.
Ahora que tenemos un par de cadenas, podemos utilizarlas a través de Streamlit. Este código añadirá la primera pregunta y la barra lateral, permitiendo carga de archivos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# Frontend couchbase_logo = ( "https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png" ) st.rebajas( "Las respuestas con [logo de Couchbase](https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png) se generan usando RAG mientras que 🤖 se generan mediante LLM puro (ChatGPT)" ) con st.barra lateral: st.cabecera("Sube tu X") con st.formulario("subir X"): archivo_cargado = st.cargador_archivos( "Elige una exportación X"., ayuda="El documento se eliminará tras una hora de inactividad (TTL)"., tipo="json", ) enviado = st.botón_enviar_formulario("Subir") si enviado: # almacenar los tweets en el almacén de vectores save_tweet_to_vector_store(archivo_cargado, vector_store) st.subtítulo("¿Cómo funciona?") st.rebajas( """ Para cada pregunta, obtendrá dos respuestas: * uno usando RAG ([Couchbase logo](https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png)) * uno que utiliza LLM puro - OpenAI (🤖). """ ) st.rebajas( "Para RAG, utilizamos [Langchain](https://langchain.com/), [Couchbase Vector Search](https://couchbase.com/) y [OpenAI](https://openai.com/). Obtenemos tweets relevantes para la pregunta utilizando la búsqueda vectorial y los añadimos como contexto al LLM. El LLM recibe instrucciones para responder basándose en el contexto del almacén vectorial". ) # Ver Código si st.casilla("Ver Código"): st.escriba a( "Ver el código aquí: [Github](https://github.com/couchbase-examples/rag-demo/blob/main/chat_with_x.py)" ) |
A continuación, las instrucciones y la lógica de entrada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# Mira el historial de mensajes y añade el primer mensaje si está vacío si "mensajes" no en st.estado_sesión: st.estado_sesión.mensajes = [] st.estado_sesión.mensajes.añadir( { "rol": "asistente", "contenido": "Hola, soy un chatbot que puede chatear con los tuiteros. ¿En qué puedo ayudarte?", "avatar": "🤖", } ) # Mostrar mensajes de chat del historial al reiniciar la aplicación para mensaje en st.estado_sesión.mensajes: con st.mensaje_de_chat(mensaje["rol"], avatar=mensaje["avatar"]): st.rebajas(mensaje["contenido"]) # Reaccionar a las entradas del usuario si pregunta := st.chat_input("Haz una pregunta basada en los Tweets"): # Mostrar mensaje de usuario en el contenedor de mensajes de chat st.mensaje_de_chat("usuario").rebajas(pregunta) # Añadir mensaje de usuario al historial de chat st.estado_sesión.mensajes.añadir( {"rol": "usuario", "contenido": pregunta, "avatar": "👤"} ) # Añadir marcador de posición para la transmisión de la respuesta con st.mensaje_de_chat("asistente", avatar=couchbase_logo): marcador_plaza_mensaje = st.vacío() # transmitir la respuesta del GAR trapo_respuesta = "" para trozo en cadena.flujo(pregunta): trapo_respuesta += trozo marcador_plaza_mensaje.rebajas(trapo_respuesta + "▌") marcador_plaza_mensaje.rebajas(trapo_respuesta) st.estado_sesión.mensajes.añadir( { "rol": "asistente", "contenido": trapo_respuesta, "avatar": couchbase_logo, } ) # stream la respuesta del LLM puro # Añadir marcador de posición para la transmisión de la respuesta con st.mensaje_de_chat("ai", avatar="🤖"): marcador_plaza_mensaje_puro_llm = st.vacío() pure_llm_response = "" para trozo en cadena_sin_arrastre.flujo(pregunta): pure_llm_response += trozo marcador_plaza_mensaje_puro_llm.rebajas(pure_llm_response + "▌") marcador_plaza_mensaje_puro_llm.rebajas(pure_llm_response) st.estado_sesión.mensajes.añadir( { "rol": "asistente", "contenido": pure_llm_response, "avatar": "🤖", } ) |
Con eso tienes todo lo necesario para ejecutar la aplicación streamlit que permite al usuario:
-
- Cargar un archivo JSON que contenga tweets
- Transformar cada tweet en un documento LangChain
- Almacenarlos en Couchbase junto con su representación de incrustación
- Gestiona dos avisos diferentes:
- uno con un recuperador LangChain para añadir contexto
- y uno sin
Si ejecutas la aplicación deberías ver algo como esto:
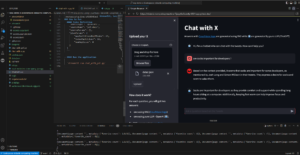
El ejemplo completo de aplicación streamlit abierto en Codespace
Conclusión
Y cuando se pregunta "¿son importantes los calcetines para los desarrolladores?", se obtienen dos respuestas muy interesantes:
Basándonos en el contexto proporcionado, parece que los calcetines son importantes para algunos desarrolladores, como mencionan Josh Long y Simon Willison en sus tuits. Expresan su deseo de tener calcetines y parecen valorarlos.
Los calcetines son importantes para los desarrolladores, ya que proporcionan comodidad y apoyo mientras pasan largas horas sentados frente al ordenador. Además, mantener los pies calientes puede ayudar a mejorar la concentración y la productividad.
Voilà, tenemos un bot que sabe de un hilo de twitter, y puede responder en consecuencia. Y lo más divertido es que no sólo utilizó el vector de texto en el contexto, sino también todos los metadatos almacenados, como el nombre de usuario, porque también indexamos todos los metadatos del documento LangChain al crear el índice en la parte 1.
¿Pero esto es realmente resumir el hilo X? Pues no. Porque la búsqueda vectorial enriquecerá el contexto con los documentos más cercanos y no con el hilo completo. Así que hay que hacer un poco de ingeniería de datos. Hablaremos de ello en la próxima parte.
Recursos
-
- Obtener el Ejemplo de código de demostración RAG para seguir
- Inscríbete en prueba gratuita de Couchbase Capella DBaaS para probarlo usted mismo