Este blog se publicó originalmente en el blog personal de Cecile Le Pape. Para ver la entrada original, haga clic en aquí.
En mi entrada anteriorEn el artículo de la semana pasada, hablé de cómo configurar un servicio flexible de gestión de contenidos utilizando Couchbase como repositorio de metadatos, sobre un servidor Apache Chemistry. Los blobs en sí (pdf, pptx, docx, etc) se almacenan en un sistema de archivos separado o en un almacén de blobs. Hoy, me gustaría mostrar como Couchbase puede ser usado para almacenar los blobs mismos, usando un gestor de chunk personalizado. La idea es almacenar no sólo los metadatos de un documento (fecha de creación, creador, nombre, etc.) sino además el propio blob.
El objetivo de esta nueva arquitectura es reducir el número de sistemas diferentes (y licencias que pagar) y también beneficiarse directamente de las funciones de replicación que ofrece Couchbase.
Primero, recordemos que Couchbase no es un almacén de blobs. Es un almacén de documentos basado en memoria, con una gestión de caché adhoc ajustada para que la mayoría de los datos almacenados en Couchbase estén en RAM para una consulta rápida. Los datos también se replican entre nodos (si la replicación está habilitada) dentro del cluster y opcionalmente fuera del cluster si se usa XDCR. Esta es la razón por la que los datos almacenados en Couchbase no pueden ser mayores de 20 MB. Este es un límite duro, y en la vida real 1MB ya es un documento grande para almacenar.
Sabiendo esto, la cuestión es: ¿cómo puedo almacenar grandes datos binarios en Couchbase? Respuesta sencilla: ¡en trozos!
La nueva arquitectura tiene ahora este aspecto:
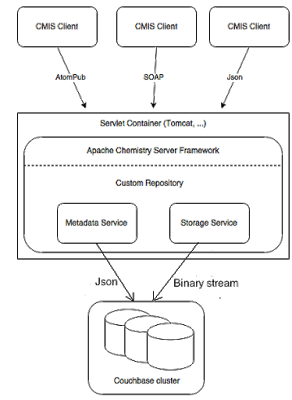
Ahora hay 2 buckets en Couchbase:
- cmismeta : utilizado para almacenar metadatos
- cmisstore : utilizado para almacenar blobs
Cuando se crea una carpeta, sólo se modifica el bucket cmismeta con una nueva entrada porque, por supuesto, una carpeta no está asociada a ningún blob. Se trata simplemente de una estructura utilizada por el usuario para organizar los documentos y navegar en el árbol de carpetas. Las carpetas son virtuales. El punto de entrada de la estructura es la carpeta raíz tal y como se describe anteriormente.
Cuando un documento (por ejemplo un pdf o un pptx) se inserta en una carpeta, ocurren 3 cosas:
- Un documento json que contiene todos sus metadatos se inserta en el bucket cmismeta, con una clave única. Digamos, por ejemplo, que el documento tiene la clave L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=.
- Se crea un nuevo documento json con la misma clave en el bucket de cmisstore. Este documento contiene el número de chunk, el tamaño máximo de cada chunk (el mismo para todos los chunk excepto para el último que puede ser más pequeño) y el tipo mime de la aplicación.
- El blob adjunto al documento se fragmenta en trozos binarios (el tamaño depende de un parámetro que puedes establecer en las propiedades del proyecto). Por defecto, un trozo tiene un tamaño de 500 KB. Cada trozo se almacena en el bucket de cmisstore como un documento binario, con la misma clave "L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=" como prefijo, y un sufijo "::partxxx" donde xxx es el número del chunk (0, 1, 2, ...).
Por ejemplo, si inserto un pptx llamado CouchbaseOverview.pptx cuyo tamaño es de 4476932 bytes en Couchbase, obtengo:
- En el cubo cmismeta, un documento json llamado L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
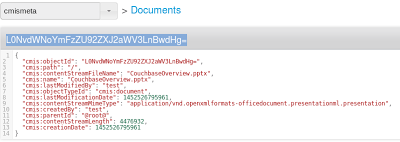
- En bucket cmisstore, un documento json también llamado L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
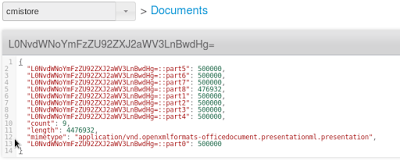
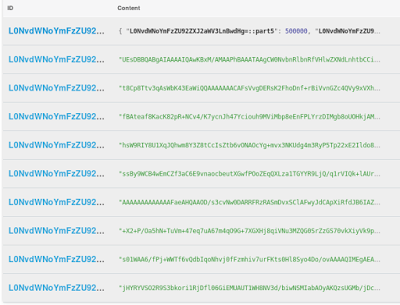
-
9 trozos que contienen datos binarios y se denominan L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part0, L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part1, ... , L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part8
El CouchbaseStorageService es la clase que implementa la interfaz StorageService ya utilizada para almacenamiento local o almacenamiento S3 como mostré en mi blog anterior. La primera diferencia es la reutilización de la misma instancia de CouchbaseCluster que la utilizada para el MetadataService, ya que sólo se debe instanciar un Couchbase Environnement para ahorrar muchos recursos (RAM, CPU, Red, etc).
Veamos ahora el método writeContent propiamente dicho:
*/
público void escribirContenido(Cadena dataId, ContentStream contentStream)
JsonDocument jsondoc = JsonDocument.create(dataId, doc);
Ahora, ¿qué hacer para recuperar el archivo de Couchbase? La idea principal es obtener cada parte, concatenarlas en el mismo orden en que fueron cortadas y enviar el array de bytes al stream. Probablemente hay muchas maneras de hacer esto, yo simplemente implemento una sencilla usando un array de bytes en el que escribo cada byte.
lanza StorageException {
JsonDocument doc = cubo.get(dataId);
JsonObject json = doc.content();
Entero nbparts = json.getInt("contar");
Entero longitud = json.getInt("longitud");
cubo.get(dataId + PARTE_SUFIX + i,DocumentoBinario.clase);
Finalmente veamos que ocurre en la herramienta workbench proporcionada por Apache Chemistry ? Puedo ver el documento en la carpeta raíz y si hago doble clic sobre él, el contenido se transmite desde Couchbase y se muestra en el visor asociado (aquí powerpoint) basado en el tipo mime.
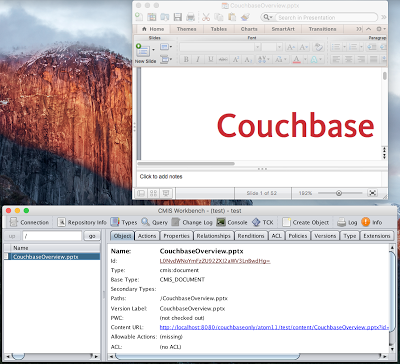
Workbench y documento abierto en powerpoint tras doble click
Este es un gran artículo, me pregunto si sería para formatos de vídeo también.