Requisitos previos
Como se menciona en Parte 1 del blog, necesitamos ejecutar Prometheus y Grafana en el entorno Kubernetes en nuestro Amazon EKS. La forma recomendada es utilizar Kube-Prometheusun proyecto de código abierto. Esto no sólo simplificará el despliegue, sino que añade muchos más componentes, como el Exportador de nodos Prometheus que supervisa las métricas del host Linux y se utiliza normalmente en un entorno Kubernetes.
Clonar el https://github.com/coreos/kube-prometheus de Github, pero no crees ningún manifiesto todavía.
Componentes incluidos en este paquete:
- En Operador de Prometheus
- Alta disponibilidad Prometeo
- Alta disponibilidad Gestor de alertas
- Exportador de nodos Prometheus
- Adaptador de Prometheus para las API de métricas de Kubernetes
- kube-state-metrics
- Grafana
|
1 2 3 4 5 6 |
➜ kube-prometheus git:(master) ✗ ls DCO README.md examples jsonnet scripts LICENSE build.sh experimental jsonnetfile.json sync-to-internal-registry.jsonnet Makefile code-of-conduct.md go.mod jsonnetfile.lock.json test.sh NOTICE docs go.sum kustomization.yaml tests OWNERS example.jsonnet hack manifests |
Nota:
Este tutorial funciona sobre la base de que los manifiestos que traen los recursos pertinentes para Prometheus Operator todavía se encuentran en la carpeta manifiestos.
Si se han producido cambios, le rogamos que se adapte a ellos, ya que el repositorio es experimental y está sujeto a cambios.
Crear el Couchbase ServiceMonitor
ServiceMonitor indica a Prometheus que supervise un recurso de servicio que define los puntos finales que Prometheus rastrea para las métricas entrantes proporcionadas por couchbase-exporter. Este archivo,couchbase-serviceMonitor.yaml, debe ser kube-prometheus/manifestos directorio.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: couchbase namespace: default # <1> labels: app: couchbase spec: endpoints: - port: metrics # <2> interval: 5s # <3> namespaceSelector: matchNames: - default # <4> selector: matchLabels: app: couchbase # <5> |
Leyenda:
- Puede que desee incluir nuestro Couchbase
ServiceMonitoren elcontroljunto con los demás espacios de nombresServicioMonitores. Para los ejemplos de este tutorial lo hemos dejado en elpor defectopara facilitar su uso. - En
puertopuede ser un valor de cadena y funcionará para diferentes números de puerto del servicio siempre que el nombre coincida. intervaloindica a Prometheus la frecuencia con la que debe rastrear el endpoint. En este caso queremos que coincida con el espacio de nombres del archivoServicioque crearemos en el siguiente paso,- tenga en cuenta que el espacio de nombres nuestro
Serviciodebe coincidir con el espacio de nombres del clúster de Couchbase del que queremos obtener las métricas. - Similar a la
namespaceSelector, se trata de un simplelabelSelectorque seleccionará el servicio que vamos a crear.
Crear el servicio de métricas Couchbase
En Servicio definirá el puerto que describimos en nuestro ServiceMonitor en spec.endpoint[0].port antes. su expediente,couchbase-service.yaml, debe ser kube-prometheus/manifestos directorio.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Service metadata: name: couchbase-metrics namespace: default # <1> labels: app: couchbase spec: ports: - name: metrics port: 9091 # <2> protocol: TCP selector: app: couchbase couchbase_cluster: cb-example # <3> |
Leyenda:
- Como se ha mencionado anteriormente, asegúrese de que el
Servicioestá en el mismo espacio de nombres que el clúster de Couchbase del que desea obtener métricas, de lo contrario no se seleccionará ningún pod y no se mostrará ningún endpoint en Prometheus Targets. Asegúrese también de que este valor coincide conspec.namespaceSelectoren elServiceMonitor. - Mantenga este puerto en su valor por defecto de 9091 ya que este es el puerto al que exportará Couchbase Exporter.
- Se puede añadir un nivel más de granularidad a tu selector en el caso de que tengas más de un Cluster Couchbase funcionando en el mismo espacio de nombres.
Descubrimiento de servicios dinámicos Prometheus
Prometheus descubre los puntos finales de monitorización, dinámicamente, haciendo coincidir las etiquetas del ServiceMonitor con los Servicios que especifican el clúster y los puntos finales, Puerto 9091 en nuestro caso.

Crear los manifiestos
Siga el comando específico dado en el LÉEME de Github para que aparezcan nuestros recursos creados junto con los demás manifiestos predeterminados proporcionados.
Componentes como Prometheus, AlertManager, NodeExporter y Grafana deberían arrancar y podemos confirmarlo inspeccionando los pods en el namespace control.
Comencemos.
Crear el espacio de nombres Kubernetes y CRDs
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
kube-prometheus git:(master) $ kubectl create -f manifests/setup namespace/monitoring created customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created clusterrole.rbac.authorization.k8s.io/prometheus-operator created clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created service/prometheus-operator created serviceaccount/prometheus-operator created |
Espere unos minutos antes del siguiente paso, pero puede ser necesario ejecutar el comando varias veces para que todos los componentes se creen correctamente.
Crear los recursos restantes
|
1 2 3 4 5 6 7 8 9 10 11 |
kube-prometheus git:(master) $ kubectl create -f manifests/ alertmanager.monitoring.coreos.com/main created secret/alertmanager-main created service/alertmanager-main created serviceaccount/alertmanager-main created servicemonitor.monitoring.coreos.com/alertmanager created service/couchbase-metrics created servicemonitor.monitoring.coreos.com/couchbase created ... servicemonitor.monitoring.coreos.com/kubelet created |
Comprobar los espacios de nombres de supervisión
Componentes como Prometheus, AlertManager, NodeExporter y Grafana deberían arrancar y podemos confirmarlo inspeccionando los pods en el namespace control.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
$ kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 69m alertmanager-main-1 2/2 Running 0 69m alertmanager-main-2 2/2 Running 0 69m grafana-75d8c76bdd-4l284 1/1 Running 0 69m kube-state-metrics-54dc88ccd8-nntts 3/3 Running 0 69m node-exporter-pk65z 2/2 Running 0 69m node-exporter-s9k9n 2/2 Running 0 69m node-exporter-vhjpw 2/2 Running 0 69m prometheus-adapter-8667948d79-vfcbv 1/1 Running 0 69m prometheus-k8s-0 3/3 Running 1 69m prometheus-k8s-1 3/3 Running 0 69m prometheus-operator-696554666f-9cnnv 2/2 Running 0 89m |
Comprueba que nuestro ServiceMonitor ha sido creado.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
$ kubectl get servicemonitors --all-namespaces NAMESPACE NAME AGE default couchbase 2m33s monitoring alertmanager 2m33s monitoring coredns 2m22s monitoring grafana 2m26s monitoring kube-apiserver 2m22s monitoring kube-controller-manager 2m22s monitoring kube-scheduler 2m21s monitoring kube-state-metrics 2m25s monitoring kubelet 2m21s monitoring node-exporter 2m25s monitoring prometheus 2m22s monitoring prometheus-operator 2m23s |
Comprobar que nuestro Servicio ha sido creado.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ kubectl get svc --all-namespaces NAMESPACE NAME PORT(S) default cb-example 8091/TCP,8092/TCP,8093/TCP, default cb-example-srv 11210/TCP,11207/TCP default couchbase-metrics 9091/TCP default couchbase-operator 8080/TCP,8383/TCP default couchbase-operator-admission 443/TCP default kubernetes 443/TCP kube-system kube-dns 53/UDP,53/TCP kube-system kubelet 10250/TCP,10255/TCP,4194/TCP,... monitoring alertmanager-main 9093/TCP monitoring alertmanager-operated 9093/TCP,9094/TCP,9094/UDP monitoring grafana 3000/TCP monitoring kube-state-metrics 8443/TCP,9443/TCP monitoring node-exporter 9100/TCP monitoring prometheus-adapter 443/TCP monitoring prometheus-k8s 9090/TCP monitoring prometheus-operated 9090/TCP monitoring prometheus-operator 8443/TCP |
En la salida anterior, no sólo vemos los servicios, sino también los puertos. Usaremos esta información para reenviar estos puertos, como hicimos con la interfaz de administración de Couchbase, para acceder a estos servicios.
Para comprobar que todo funciona correctamente con la implantación de Prometheus Operator, ejecute el siguiente comando para ver los registros:
|
1 |
$ kubectl logs -f deployments/prometheus-operator -n monitoring prometheus-operator |
Reenvío de puertos
Ya hemos reenviado el puerto 8091 de Couchbase Admin UI desde un nodo de Couchbase anteriormente, pero voy a dar esto de nuevo, esta vez desde el punto de vista del servicio.
Además de ese puerto, en realidad sólo necesitamos el acceso al servicio Grafana, Puerto 3000. Sin embargo, vamos a acceder al servicio Prometheus Puerto 9090 también. Entonces podemos echar un vistazo a todas las métricas de los diferentes exportadores y probar un poco de PromQL, el Prometheus Query Language también.
Ahora bien, las 3 anteriores deberían ser suficientes. Sin embargo, hay alguna ventaja adicional de echar un vistazo a las métricas de cada servicio individual también. El exportador de Couchbase expone las métricas de Couchbase en el puerto 9091. Por lo tanto, podemos reenviar esos puertos también. Ten en cuenta que sólo necesitas acceso a Grafana.
|
1 2 3 4 5 6 |
kubectl --namespace default port-forward svc/cb-example 8091 & kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090 & kubectl --namespace monitoring port-forward svc/grafana 3000 & kubectl --namespace monitoring port-forward svc/alertmanager-main 9093 & kubectl --namespace monitoring port-forward svc/node-exporter 9100 & kubectl --namespace default port-forward svc/couchbase-metrics 9091 & |
Echa un vistazo a Prometheus Targets
Acceso: https://localhost:9090/targets
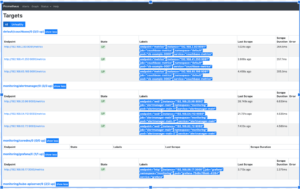
Todos los objetivos de Prometheus deberían estar ARRIBA. Hay bastantes de estos desde Kube-Prometheus desplegado un montón de exportadores.
Consulta las métricas de Couchbase sin procesar
Acceso: https://localhost:9091/metrics
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# HELP cbbucketinfo_basic_dataused_bytes basic_dataused # TYPE cbbucketinfo_basic_dataused_bytes gauge cbbucketinfo_basic_dataused_bytes{bucket="pillow"} 1.84784896e+08 cbbucketinfo_basic_dataused_bytes{bucket="travel-sample"} 1.51648256e+08 # HELP cbbucketinfo_basic_diskfetches basic_diskfetches # TYPE cbbucketinfo_basic_diskfetches gauge cbbucketinfo_basic_diskfetches{bucket="pillow"} 0 cbbucketinfo_basic_diskfetches{bucket="travel-sample"} 0 # HELP cbbucketinfo_basic_diskused_bytes basic_diskused # TYPE cbbucketinfo_basic_diskused_bytes gauge cbbucketinfo_basic_diskused_bytes{bucket="pillow"} 1.98967788e+08 cbbucketinfo_basic_diskused_bytes{bucket="travel-sample"} 1.91734038e+08 |
Esta salida es útil, ya que permite buscar rápidamente en la lista.
Prueba una consulta PromQL básica
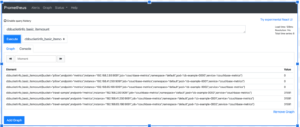
En la interfaz de usuario anterior, haga clic en Gráfico primero.
El cuadro desplegable le ofrece la lista de métricas raspadas. Esta es la lista completa de todos las métricas raspadas por todos los exportadores y esa es una lista bastante desalentadora. Un método para reducir la lista a sólo métricas Couchbase, es, por supuesto, acceder al punto final 9091 como se describió anteriormente.
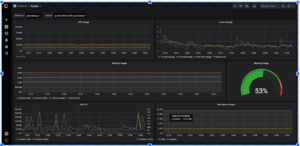
Eche un vistazo a Grafana
Acceso: https://localhost:3000

El nombre de usuario y la contraseña son: admin/admin
El despliegue kube-prometheus de Grafana ya tiene definida la fuente de datos Prometheus y un amplio conjunto de Cuadros de mando por defecto. Echemos un vistazo al Cuadro de mandos del nodo por defecto
Crear un panel de Grafana de ejemplo para supervisar las métricas de Couchbase
No vamos a construir un Dashboard completo, sino una pequeña muestra con algunos paneles para mostrar cómo se hace. Este dashboard monitorizará el número de elementos en un bucket y el número de operaciones GET y SET.
Nota: Por favor, ejecute la aplicación de lucha de almohadas tal y como se describe en la Parte 1. Esto generará las operaciones que nos interesa monitorizar.
Métricas Prometheus
Acceso: https://localhost:9091/gráfico
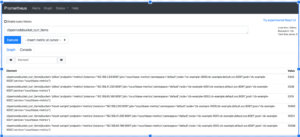
Estamos interesados en los elementos actuales de un cubo. Hay un par de métricas que proporcionan esto, a nivel de cluster y por nodo. Vamos a utilizar la métrica por nodo. Así permitiremos que Prometheus gestione todas las agregaciones, según las mejores prácticas. Otra ventaja es que incluso podemos mostrar los elementos actuales en el cubo, por nodo, sólo para comprobar si nuestro conjunto de datos está sesgado.
Veamos un elemento:
|
1 |
cbpernodebucket_curr_items{bucket="pillow",endpoint="metrics",instance="192.168.2.93:9091",job="couchbase-metrics",namespace="default",node="cb-example-0000.cb-example.default.svc:8091",pod="cb-example-0000",service="couchbase-metrics"} |
En el ejemplo anterior, nos interesan estas etiquetas: cuboparte de nodo (la parte central, cb-ejemplo que es el nombre del cluster, y vaina. También estamos interesados en servicio para filtrar. Esto nos ayudará a diseñar un panel de control en el que podremos ver las métricas por bucket, nodo o clúster.
El cuadro de mandos de muestra
Vamos a crear un nuevo salpicadero de muestra en blanco.

Añadir variables
Como queremos las métricas por cubo, nodo y cluster, vamos a añadir estas variables para que se puedan seleccionar en un desplegable.
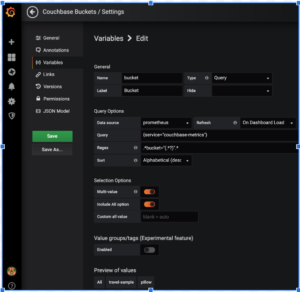
El ejemplo anterior crea la variable bucket. Observe la expresión Query y Regex.
Vamos a crear 2 más para tener 3 variables:
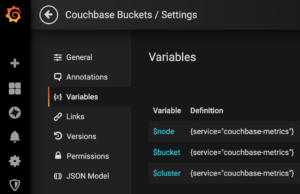
La consulta no cambia para estos 3, pero aquí están las expresiones Regex:
|
1 2 3 4 5 |
Query: {service="couchbase-metrics"} $node: Regex= .*pod="(.*?)".* $bucket: Regex= .*bucket="(.*?)".* $cluster: Regex=.*node=\".*\.(.*)\..*\..*:8091\".* |
Creación de un panel
Crear 3 paneles para elementos actuales, GETs y SETs
Puede duplicar cada panel y editarlos. Estas son las consultas:
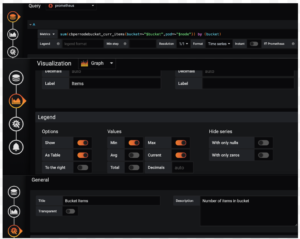
Panel Items: sum(cbpernodebucket_curr_items{bucket=~"$bucket",pod=~"$node"}) by (bucket)
Panel GETs: sum(cbpernodebucket_cmd_get{bucket=~"$bucket",pod=~"$node"}) by (bucket)
Panel SETs: sum(cbpernodebucket_cmd_set{bucket=~"$bucket",pod=~"$node"}) by (bucket)
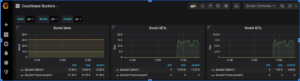
El ejemplo completo de Grafana Dashboard
Este es el aspecto final de nuestro panel de control de muestra.
Limpieza
Por último, limpie su despliegue:
|
1 2 3 4 5 6 7 |
kube-prometheus git:(master) $ kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup cao-2 $ kubectl delete -f pillowfight-data-loader.yaml cao-2 $ kubectl delete -f my-cluster.yaml cao-2 $ bin/cbopcfg | kubectl delete -f - cao-2 $ kubectl delete -f crd.yaml cao-2 $ eksctl delete cluster --region=us-east-1 --name=prasadCAO2 |
Recursos:
- Descargar Couchbase Autonomous Operator 2.0 Beta para Kubernetes
- Introducción a Couchbase Autonomous Operator 2.0 Beta
- Tutorial - Operador autónomo de Couchbase en EKS
- Comparta su opinión sobre el Foros de Couchbase