La replicación ha sido una parte crucial de los sistemas de bases de datos durante décadas para proporcionar disponibilidad y recuperación ante desastres. En los últimos tiempos, con la evolución de las bases de datos distribuidas para hacer frente a la necesidad de despliegues de alta disponibilidad, escalables y distribuidos globalmente que operan a través de dispositivos, el papel de la replicación ha evolucionado y se ha vuelto más importante que nunca. Los sistemas de bases de datos están desarrollando amplias soluciones de replicación para hacer frente a los requisitos a diferentes niveles, como intraclúster, interclúster y de extremo a núcleo, etc., que también abarcan la nube, los móviles y otros casos de uso de IoT.
Algunos de los más populares Base de datos NoSQL sistemas con soluciones de replicación versátiles son Couchbase y MongoDB. Echemos un vistazo más profundo a cada una de estas soluciones y cómo abordan estas necesidades. Para simplificar la comparación, vamos a centrarnos en la replicación para alta disponibilidad y despliegues globales a través de múltiples DCs.
Replicación en MongoDB para un despliegue global
Arquitectura maestro-esclavo
La arquitectura de replicación de Mongo se basa en un conjunto de réplicas, que consta de sólo una primaria que captura todos los cambios de datos y confirma las escrituras. Los secundarios copian los datos de los primarios, que suelen ser de sólo lectura a menos que sean elegidos como primarios. Cada conjunto de réplicas puede constar de hasta 50 secundarios. Los miembros del conjunto de réplica también pueden desplegarse en múltiples centros de datos para la protección contra fallos del centro de datos y aplicaciones geo-distribuidas. Los datos se replican a los secundarios de forma asíncrona.
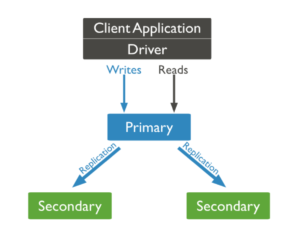
Fig. Modelo de replicación de Mongo
El tiempo medio para la conmutación automática de primario a secundario es de unos 12 segundos, que puede ser mayor cuando los secundarios se despliegan en diferentes centros de distribución debido a la latencia de la red. Esto se convierte en una posibilidad de punto único de fallo, ya que los secundarios no pueden tomar escrituras.
Aunque las lecturas se realizan por defecto desde el primario, los usuarios pueden especificar la preferencia de lectura para que se produzca desde los secundarios para minimizar la latencia. Sin embargo, dado que las réplicas son asíncronas, se corre el riesgo de leer datos obsoletos, especialmente en aplicaciones geodistribuidas.
Despliegue multicentro y configuración de tipo Activo-Activo
Para despliegues multicéntricos, aunque los secundarios de un conjunto de réplicas pueden desplegarse en un centro de datos diferente, es insuficiente hasta que todos los centros de datos puedan tomar escrituras. Los despliegues activo-activo con la capacidad de tomar escrituras concurrentemente desde múltiples centros de datos son críticos para las aplicaciones geo-distribuidas. Dado que Mongo sólo puede tomar escrituras en primario, recomiendan el enfoque mencionado a continuación para abordar casos de uso activo-activo.
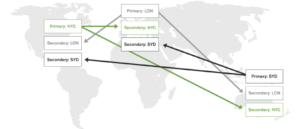
Fig. Configuración de tipo Activo-Activo utilizando MongoDB
A fragmento en MongoDB es una unidad lógica de almacenamiento que contiene un subconjunto de todo el conjunto de datos del clúster fragmentado. Para permitir una configuración activa-activa, Mongo recomienda desplegar un primario en cada fragmento. Dado que cada fragmento contiene un subconjunto distinto de datos, la aplicación sólo puede modificar diferentes subconjuntos de datos simultáneamente. Por lo tanto, no es completamente activo-activo donde el mismo conjunto de datos puede ser modificado en diferentes sitios.
Un Shard es completamente transparente para la aplicación y se despliega un enrutador de consultas para dirigir las consultas desde la aplicación a los shards respectivos. El enrutamiento de consultas también añade sobrecarga adicional.
El despliegue a través de esta configuración puede ser extremadamente complicado a medida que se amplía porque, no sólo cada fragmento tiene que tener un primario, para el primario de cada fragmento, los secundarios tienen que estar ubicados en otros fragmentos de alta disponibilidad, y el primario sigue siendo un único punto de fallo. Para cada shard, el número de réplicas será igual al número de shards * número de centros de datos. También necesitaríamos mantener un quórum capaz de elegir al primario en cualquier momento para cada conjunto de réplicas. Más información en más.
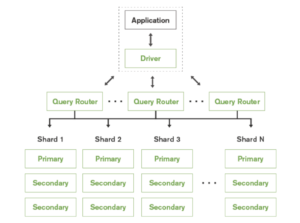
Esta configuración también es muy restrictiva en términos de topología, los despliegues tienen que adherirse al modelo hub and spoke ya que el primario es un cuello de botella.
Despliegues en la nube - Clúster mundial
Mongo Atlas ofrece Global Cluster para mejorar los casos de uso de geo-replicación. El despliegue mediante Global Cluster es similar a la configuración activa-activa, en la que se dispone de un primario para un fragmento en cada zona y región en las que el proveedor de la nube ofrece soporte.
A través de Global Cluster, Mongo es capaz de ofrecer enrutamiento sensible a la ubicación utilizando los metadatos de ubicación que se obtienen de los proveedores de la nube. Esto permite a Mongo dirigir las consultas al centro de datos más cercano al punto de origen y ofrecer la menor latencia de red. Esto es beneficioso en la mayoría de los casos cuando las actualizaciones son locales. Para los casos en que las escrituras no son locales, hay una latencia de red añadida ya que sólo el primario puede tomar escrituras.
La mayor ventaja de los clústeres globales es que Mongo se encarga de las complejidades operativas y de despliegue relacionadas con la configuración y la gestión, ya que Atlas es un servicio totalmente gestionado. Una vez más, esto se limitará a la implantación de un único proveedor de nube. El clúster global no puede abarcar varios proveedores de nubes y regiones para dar soporte a implantaciones híbridas, ya que se trata de un único clúster. Más información sobre los clústeres globales aquí.
Replicación en Couchbase para despliegue global
Arquitectura de igual a igual
Couchbase ha adoptado distintos esquemas de replicación para replicación dentro de un cluster para fallos a nivel de nodo y replicación entre clusters para fallos a nivel de centro de datos y regional. La replicación entre clusters o entre centros de datos será el foco de esta discusión ya que estamos interesados en despliegues globales.
Couchbase sigue una arquitectura peer-to-peer y esto se refleja también en su solución de replicación entre centros de datos. Con Couchbase, puedes crear múltiples clusters independientes y establecer flujos de replicación unidireccionales o bidireccionales entre ellos. Estos clusters independientes pueden estar ubicados en el mismo centro de datos o en ubicaciones geográficas completamente diferentes. Esta arquitectura de clústeres peer-to-peer independientes ofrece múltiples ventajas, como el aislamiento de la carga de trabajo, la posibilidad de establecer diferentes políticas, la compatibilidad con diversas topologías, el escalado heterogéneo y también permite el despliegue híbrido.
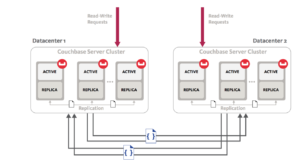
La solución de Couchbase también se considera de alto rendimiento, ya que la replicación se produce de memoria a memoria y es altamente paralela. El paralelismo es personalizable en función de los requisitos de rendimiento. También tienen la capacidad de priorizar los flujos de replicación existentes sobre los nuevos o viceversa. También se recuperan automáticamente tras cualquier interrupción de la red.
Otra gran ventaja es la topología flexible, ya que se pueden añadir o eliminar clusters de la topología en cualquier momento sin que ello afecte al resto del sistema. De este modo se aprovechan muy bien los recursos. Por ejemplo, en una topología en anillo bidireccional, los clústeres pueden actuar como solución de recuperación ante desastres, además de recibir tráfico activo.
Configuración multicentro y activo-activo
La solución de replicación entre centros de datos puede desplegarse en cualquier lugar del mundo donde el cliente disponga de un centro de datos. Basta con unos pocos clics para crear un nuevo clúster y configurar la replicación entre ellos.
XDCR de Couchbase soporta una verdadera configuración activo-activo a través de la replicación bidireccional donde los usuarios de todo el mundo pueden modificar los mismos datos simultáneamente en varios lugares. Soportan dos modos de resolución de conflictos - Most update wins y Last Write Wins para resolver cualquier conflicto que surja durante una configuración activo-activo.
En este punto, Couchbase no proporciona ningún enrutamiento que tenga en cuenta la localización, pero como es una arquitectura maestro-maestro, las lecturas y escrituras son siempre locales. Los clientes pueden desplegar los datos en cualquier centro de datos para garantizar la localización de los datos. Los clientes también pueden cumplir con los requisitos de residencia de datos y geo-cercado mediante el uso de filtrado avanzado para replicar sólo los datos que son relevantes para la región.
Implantaciones en la nube
Couchbase está disponible en las principales nubes: AWS, Azure, GCP y Oracle Cloud.
Los clústeres de Couchbase pueden desplegarse en cualquier nube, y pueden establecerse flujos de replicación entre ellos. Esto incluye despliegues en nubes múltiples e híbridas, en los que los clústeres pueden desplegarse en diversas nubes, como privadas y públicas, o en dos o más nubes públicas.
El despliegue y la administración de los sistemas de replicación son extremadamente sencillos e intuitivos.
Couchbase aún no tiene una solución DBaaS, pero se espera que llegue pronto. Sin embargo, el soporte para el despliegue automatizado se proporciona actualmente a través de la aplicación Operador Autónomo Couchbase.
Resumen de las características de replicación en Couchbase y Mongo DB
| Capacidades | Couchbase | MongoDB |
| Arquitectura | Clúster completamente independiente, que puede escalarse y gestionarse sin dependencias. | Ampliación del intracluster, no es un sistema independiente |
| Rendimiento | Replicación en memoria, basada en flujos y altamente paralelizada. El número de flujos de replicación por nodo puede ser de (2-100) | Los secundarios replican los datos del oplog del primario o de cualquier otro secundario. Es paralelo pero los flujos son 1-1 (primario-secundario) |
| Escribir Preocupaciones | Cualquier cluster puede ser configurado para aceptar escrituras | Sólo el primario puede recibir escrituras, lo que afecta a la disponibilidad de las mismas, y las escrituras no locales son muy caras. |
| Leer Preocupaciones | Siempre local | El primario por defecto, que puede ser caro, puede configurarse para leer de los secundarios |
| Auto-failover | La conmutación por error automática entre clústeres puede activarse en el SDK. | Grupo único, automático |
| Flexibilidad de replicación | Muy flexible - nivel de cubo, técnicas avanzadas de optimización para personalizar | No es posible ajustar, elegir la velocidad ni el ancho de banda. |
| Técnicas de optimización del ancho de banda | Filtrado avanzado, compresión de datos, limitación del ancho de banda de la red, calidad de servicio para priorizar la replicación. | Compresión de datos |
| Topología | Compatible con topologías complejas: bidireccional, en estrella, en malla, en cadena, en anillo, etc. | No admite topologías complejas -Unidireccional, Estrella. El primario es un cuello de botella. |
| Activo-Activo | Soporte | Sin soporte real (maestro único) |
| Resolución de conflictos | Sí - gana el que más escribe, gana el que menos escribe (LWW) | Sin resolución de conflictos. Sólo se admite un primario. |
| Instalación y configuración | Fácil configuración con interfaz de usuario intuitiva y CLI con sólo un par de clics. | La distribución de conjuntos de réplicas es complicada y puede resultar dolorosa a medida que aumentan los conjuntos de réplicas. |
| Filtrado para replicar subconjuntos | Filtrado avanzado para replicar subconjuntos de datos mediante ID de clave de documento, valores o metadatos. | No admite filtrado |
| Priorización de la replicación | Posibilidad de dar prioridad a la replicación en curso frente a la nueva replicación o viceversa. | No admite la priorización de la replicación. |