
Replication has been a crucial part of Database Systems for decades for providing availability and disaster recovery. In recent times, with the evolution of distributed databases to address the need for highly available, scalable and globally distributed deployments operating across devices, the role of replication has evolved and it has become more significant than ever before. The database systems are developing extensive replication solutions to address the requirements at different levels such as intra-cluster, inter-cluster and edge to core etc., which also encompasses cloud, mobile and other IoT use cases.
Some of the most popular NoSQL database systems with versatile replication solutions are Couchbase and MongoDB. Let’s take a deeper look into each of these solutions and how they address these needs. For simplicity in comparison, let’s focus on replication for high availability and global deployments across multiple DCs.
Replication in MongoDB for Global Deployment
Master-Slave Architecture
Mongo replication architecture is based on a replica set, it consists of only one primary which captures all data changes and confirms writes. The secondaries copy the data from the primaries which are typically read-only unless they get elected to be a primary. Each replica set can consist of up to 50 secondaries. The members of the replica set can also be deployed in multiple data centers for protection against data center failures and geo-distributed applications. Data is replicated to secondaries asynchronously.

Fig. Mongo’s replication model
The median time for automatic failover of primary to secondary is ~12 seconds, which might be more when secondaries are deployed in different DCs due to network latency. This becomes a possibility for a single point of failure as secondaries cannot take writes.
Although reads are default from primary, users can specify the read preference to occur from secondaries to minimize the latency. However, since replications are asynchronous, they might risk the possibility of reading stale data, especially in geo-distributed applications.
Multi-Center deployment and Active-Active like set up
For multi-center deployments, although secondaries of a replica set can be deployed in a different data center, it is insufficient until every data center can take writes. Active-active deployments with the ability to take writes concurrently from multiple datacenters are critical for geo-distributed applications. Since Mongo can only take writes on primary, they recommend the below mentioned approach for addressing active-active use cases.
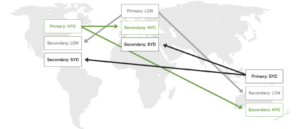
Fig. Active-Active like setup using MongoDB
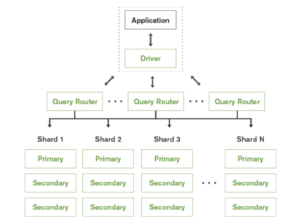
A shard in MongoDB is a logical storage unit that contains a subset of the entire sharded cluster’s dataset. In order to enable an active-active like set-up, Mongo advocates deploying a primary in every shard. Since every shard contains a distinct subset of data, the application can only modify different subsets of data concurrently. Hence, it is not completely active-active where the same dataset can be modified in different sites.
A Shard is completely transparent to the application and a query router is deployed to route the queries from the application to the respective shards. Query routing also adds additional overhead.
The deployment via this set-up can get extremely complicated as it scales because, not only every shard has to have a primary, for every shard’s primary, secondaries have to be located in other shards for high availability, and primary continues to be a single point of failure. For every shard, the number of replicas will be equal to the number of shards * number of datacenters. We would also need to maintain a quorum capable of electing primary at any point in time for every replica set. Learn more.
This setup is also very restrictive in terms of topology, deployments have to adhere to the hub and spoke model as primary is a bottleneck.
Cloud Deployments – Global Cluster
Mongo Atlas offers Global Cluster to enhance the geo-replication use cases. The deployment using Global Cluster is similar to the active-active like set-up, where you have primary for a shard in every zone and region where the cloud vendor offers support.
Via Global Cluster, Mongo is able to offer location-aware routing using the location metadata which is obtained from the cloud providers. This enables Mongo to route the queries to the data center closest to the point of origination and offer the least network latency. This is beneficial in most cases when updates are local. For cases where the writes are non-local, there is an added network latency as only the primary can take writes.
The biggest benefit of Global Clusters is that operational and deployment complexities involved in the setup and manageability are handled by Mongo as Atlas is a fully managed service. This will once again be restricted to a single cloud vendor’s deployment. Global Cluster cannot span across multiple cloud vendors and regions to support hybrid deployments as it’s a single cluster. More on Global Clusters here.
Replication in Couchbase for Global Deployment
Peer to peer architecture
Couchbase has adopted distinct replication schemes for replication within a cluster for node-level failures and replication across clusters for datacenter and regional level failures. Inter-cluster or Cross datacenter replication will be the focus of this discussion as we are interested in Global Deployments.
Couchbase follows a peer-to-peer architecture and this is reflected in their cross datacenter replication solution as well. With Couchbase, you can create multiple independent clusters and set up unidirectional or bi-directional replication streams between them. These independent clusters can be co-located within the same data-center or can exist in completely different geographies. This architecture of having peer-to-peer independent clusters provides multiple benefits such as workload isolation, the ability to set different policies, support for diverse topologies, heterogeneous scaling and also enables hybrid deployment.
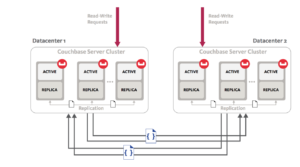
Couchbase’s solution is also considered highly performant as the replication happens from memory to memory and is highly parallel. The parallelism is customizable in accordance with performance requirements. They also have the ability to prioritize the existing replication streams over the new ones or vice versa. They also auto recover after any network interruption.
Another huge benefit is the flexible topology, clusters can be added or removed from the topology at any point without any impact on the rest of the system. This provides extremely good resource utilization. Eg. In a bi-directional ring topology, the clusters can act as a disaster recovery solution as well as take active traffic.
Multi-center and Active-Active set up
Cross Datacenter replication solution can be deployed anywhere across the globe wherever the customer owns a datacenter. It just takes a few clicks to create a new cluster and set up replication between them.
Couchbase’s XDCR supports true active-active set-up via bidirectional replication where users across the globe can modify the same data concurrently at multiple places. They support two modes of conflict resolution – Most update wins and Last Write Wins to resolve any conflicts that arise during an active-active setup.
At this point, Couchbase does not provide any location-aware routing, but since it’s a master-master architecture, the reads and writes are always local. Customers can deploy the data anywhere on any datacenter to suffice data locality. Customers can also fulfill the data residency and geo-fencing requirements by using advanced filtering to only replicate data that is relevant to the region.
Cloud Deployments
Couchbase is available on all major clouds: AWS, Azure, GCP and the Oracle Cloud.
Couchbase clusters can be deployed on any cloud, and replication streams can be set up between them. This includes multi-cloud and hybrid cloud deployments where clusters can be deployed on diverse clouds like private and public or two or more public clouds.
The deployment and administration of the replication systems are extremely simple and intuitive.
Couchbase does not have a DBaaS solution yet, but it is expected to be coming soon. However, support for automated deployment is currently provided through the Couchbase Autonomous Operator.
Summary of replication characteristics in Couchbase and Mongo DB
| Capabilities | Couchbase | MongoDB |
| Architecture | Completely independent cluster, which can be scaled and managed without any dependencies | Extension of intra-cluster, not an independent system |
| Performance | Memory-memory, stream-based, highly parallelized replication. The number of replication streams per node can be (2-100) | Secondaries replicate the data from primary’s oplog or any other secondary’s oplog. It is parallel but streams are 1-1 (primary-secondary) |
| Write Concerns | Any cluster can be configured to accept writes | Only primary can take writes which impacts write availability and non-local writes are very expensive |
| Read Concerns | Always local | Default primary which might be expensive can be configured to read from secondaries |
| Auto-failover | Cross cluster automatic failover can be enabled at the SDK level | Single cluster, automatic |
| Replication Flexibility | Very flexible – bucket level, advanced optimization techniques to customize | Tuning, choosing speed, bandwidth is not possible |
| Bandwidth optimization techniques | Advanced filtering, Data compression, Network bandwidth capping, Quality of Service to prioritize replication. | Data compression |
| Topology | Support for complex topologies – Bidirectional, Star, mesh, chain, ring anything | No support for complex topology -Unidirectional, Star. Primary is a bottleneck. |
| Active-Active | Supported | No true support(single master) |
| Conflict Resolution | Yes – most write wins, last write wins(LWW) | No conflict resolution. Only one primary supported. |
| Setup & Configuration | Easy configurability with intuitive UI and CLI with just a couple clicks. | Replica set distribution is tricky and can be painful as the replica sets increase. |
| Filtering to replicate subsets | Advanced filtering to replicate subsets of data using doc key IDs, values or metadata. | No filtering supported |
| Replication prioritization | Ability to prioritize on-going replication compared to new replication or vice versa. | No support for replication prioritization. |
Leave a comment
You must be logged in to post a comment.