El modelado de datos JSON es una parte vital del uso de una base de datos de documentos como Couchbase. Más allá de la comprensión de los conceptos básicos de JSON, hay dos enfoques clave para modelar las relaciones entre los datos que serán cubiertos en esta entrada del blog.
Los ejemplos de este post se basarán en el ejemplo de facturas que mostré en Herramientas CSV para migrar a Couchbase desde una base relacional.
Actualización de datos importados
En el ejemplo anterior, partí de dos tablas de una base de datos relacional: Facturas e InvoicesItems. Cada partida de factura pertenece a una factura, lo que se hace con una clave ajena en una base de datos relacional.
Hice una importación muy directa (ingenua) de estos datos a Couchbase. Cada fila se convirtió en un documento en un bucket "staging".

A continuación, debemos decidir si ese diseño de modelado de datos JSON es apropiado o no (no creo que lo sea, como si el hecho de que el cubo se llame "staging" no lo delatara ya).
Dos enfoques para el modelado de datos JSON de relaciones
Con una base de datos relacional, sólo hay una solución: normalizar los datos. Esto significa tablas separadas con claves externas que unan los datos.
Con una base de datos de documentos, hay dos enfoques. Puede mantener los datos normalizados o puede desnormalizar los datos anidándolos en su documento padre.
Normalizado (documentos separados)
Un ejemplo del estado final del normalizado representa una única factura repartida en varios documentos:
|
1 2 3 4 5 6 7 8 9 10 11 |
clave - factura::1 { "BillTo": "Lynn Hess", "FechaFactura": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive" } clave - elemento de factura::1811cfcc-05b6-4ace-a52a-be3aad24dc52 { "InvoiceId": "1", "Precio": "1000.00", "Producto: "Pastilla de freno", "Cantidad": "24" } clave - elemento de factura::29109f4a-761f-49a6-9b0d-f448627d7148 { "InvoiceId": "1", "Precio": "10.00", "Producto: "Volante", "Cantidad": "5" } clave - elemento de factura::bf9d3256-9c8a-4378-877d-2a563b163d45 { "InvoiceId": "1", "Precio": "20.00", "Producto: "Neumático", "Cantidad": "2" } |
Esto coincide con la importación directa de CSV. En InvoiceId de cada documento de factura es similar a la idea de una clave foránea, pero ten en cuenta que Couchbase (y las bases de datos de documentos distribuidas en general) no imponen esta relación de la misma manera que las bases de datos relacionales. Este es un compromiso hecho para satisfacer las necesidades de flexibilidad, escalabilidad y rendimiento de un sistema distribuido.
Tenga en cuenta que, en este ejemplo, los documentos "hijos" apuntan al padre a través de InvoiceId. Pero también podría ser al revés: el documento "padre" podría contener una matriz con las claves de cada documento "hijo".
Desnormalizado (anidado)
El estado final del anidado se utilizaría un único documento para representar una factura.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
clave - factura::1 { "BillTo": "Lynn Hess", "FechaFactura": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive", "Artículos": [ { "Precio": "1000.00", "Producto: "Pastilla de freno", "Cantidad": "24" }, { "Precio": "10.00", "Producto: "Volante", "Cantidad": "5" }, { "Precio": "20.00", "Producto: "Neumático", "Cantidad": "2" } ] } |
Tenga en cuenta que "InvoiceId" ya no está presente en los objetos de la carpeta Artículos array. Estos datos ya no son extranjeros, ahora son nacionales, por lo que ese campo ya no es necesario.
Reglas básicas del modelado de datos JSON
Puede que ya esté pensando que el segundo es una opción natural en este caso. Una factura en este sistema es una raíz agregada. Sin embargo, no siempre es sencillo y obvio cuándo y cómo elegir entre estos dos enfoques en su aplicación.
He aquí algunas reglas generales sobre cuándo elegir cada modelo:
| Si... | Entonces considera... |
|---|---|
|
La relación es de 1 a 1 o de 1 a muchos |
Objetos anidados |
|
La relación es muchos-a-1 o muchos-a-muchos |
Documentos separados |
|
Los datos leídos son en su mayoría campos padre |
Documento aparte |
|
Los datos leídos son en su mayoría campos padre + hijo |
Objetos anidados |
|
Las lecturas de datos son en su mayoría parentales o niño (no ambos) |
Documentos separados |
|
Las escrituras de datos son en su mayoría de los padres y niño (ambos) |
Objetos anidados |
Ejemplo de modelización
Para profundizar en este tema, hagamos algunas suposiciones sobre el sistema de facturación que estamos construyendo.
- Un usuario suele ver la factura completa (incluidas las partidas de la factura)
- Cuando un usuario crea una factura (o realiza cambios), está actualizando tanto los campos "raíz" como los "artículos" juntos
- Existen algunos consultas (pero no muchas) en el sistema que sólo se interesan por los datos raíz de la factura e ignoran los campos "artículos".
Entonces, basándonos en ese conocimiento, sabemos que:
- La relación es de 1 a muchos (una sola factura tiene muchos artículos)
- Las lecturas de datos son sobre todo campos padre + hijo juntos
Por tanto, los "objetos anidados" parecen el diseño adecuado.
Recuerde que no se trata de reglas rígidas que se apliquen siempre. Son simplemente directrices que le ayudarán a empezar. La única "mejor práctica" es utilizar tus propios conocimientos y experiencia.
Transformación de datos de puesta en escena con N1QL
Ahora que hemos hecho algunos ejercicios de modelado de datos JSON, es el momento de transformar los datos en el cubo de preparación de documentos separados que vinieron directamente de la base de datos relacional al diseño de objetos anidados.
Hay muchos enfoques para esto, pero voy a mantenerlo muy simple y utilizar el potente Couchbase Lenguaje N1QL para ejecutar consultas SQL en datos JSON.
Preparación de los datos
En primer lugar, cree un bucket de "operación". Voy a transformar los datos y moverlos desde el cubo "staging" (que contiene los datos directos de la base de datos) al cubo "operación". Importación CSV) al cubo "operación".
A continuación, voy a marcar los documentos "raíz" con un campo "tipo". Esta es una forma de marcar los documentos como de un tipo determinado, y será útil más adelante.
|
1 2 3 |
ACTUALIZACIÓN puesta en escena SET tipo = factura DONDE NúmeroFactura IS NO FALTA; |
Sé que los documentos raíz tienen un campo llamado "InvoiceNum" y que los artículos no tienen este campo. Así que esta es una forma segura de diferenciar.
A continuación, tengo que modificar los elementos. Anteriormente tenían una clave externa que era sólo un número. Ahora esos valores deben actualizarse para que apunten a la nueva clave de documento.
|
1 2 |
ACTUALIZACIÓN puesta en escena s SET s.InvoiceId = "factura:: || s.InvoiceId; |
Se trata simplemente de añadir "invoice::" al valor. Tenga en cuenta que los documentos raíz no tienen un campo InvoiceId, por lo que no se verán afectados por esta consulta.
Después de esto, necesito crear un índice en ese campo.
Preparar un índice
|
1 |
CREAR ÍNDICE ix_invoiceid EN puesta en escena(InvoiceId); |
Este índice será necesario para la próxima unión transformacional.
Ahora, antes de hacer operativos estos datos, vamos a ejecutar un SELECCIONE para obtener una vista previa y asegurarnos de que los datos se van a unir como esperamos. Utilice N1QL NEST operación:
|
1 2 3 4 |
SELECCIONE i.*, t AS Artículos DESDE puesta en escena AS i NEST puesta en escena AS t EN CLAVE t.InvoiceId PARA i DONDE i.tipo = factura; |
El resultado de esta consulta debería ser un total de tres documentos de factura raíz.
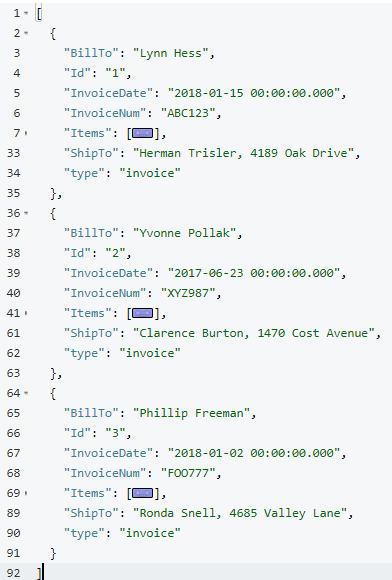
Los elementos de la factura deberían estar ahora anidados en una matriz "Elementos" dentro de su factura principal (los he contraído en la captura de pantalla anterior en aras de la brevedad).
Mover los datos fuera de la puesta en escena
Una vez que haya verificado que todo parece correcto, puede mover los datos al cubo de "operaciones" mediante un comando INSERTAR que no será más que una ligera variación del comando anterior SELECCIONE mando.
|
1 2 3 4 5 |
INSERTAR EN operación (CLAVE k, VALOR v) SELECCIONE META(i).id AS k, { i.BillTo, i.FechaFactura, i.NúmeroFactura, "Artículos": t } AS v DESDE puesta en escena i NEST puesta en escena t EN CLAVE t.InvoiceId PARA i donde i.tipo = factura; |
Si eres nuevo en N1QL, hay un par de cosas que señalar aquí:
INSERTARutilizará siempreCLAVEyVALOR. En esta cláusula no se enumeran todos los campos, como se haría en una base de datos relacional.META(i).ides una forma de acceder a la clave de un documento- La sintaxis literal JSON que se SELECCIONA COMO v es una forma de especificar los campos sobre los que se desea pasar. Aquí se podrían utilizar comodines.
NESTes un tipo de unión que anidará los datos en una matriz en lugar de en el nivel raíz.PARA iespecifica el lado izquierdo delEN LA LLAVEjoin. Esta sintaxis es probablemente la parte menos estándar de N1QL, pero la próxima versión de Couchbase Server incluirá la funcionalidad "ANSI JOIN" que será mucho más natural de leer y escribir.
Después de ejecutar esta consulta, debería tener un total de 3 documentos en su bucket "operación" que representan 3 facturas.
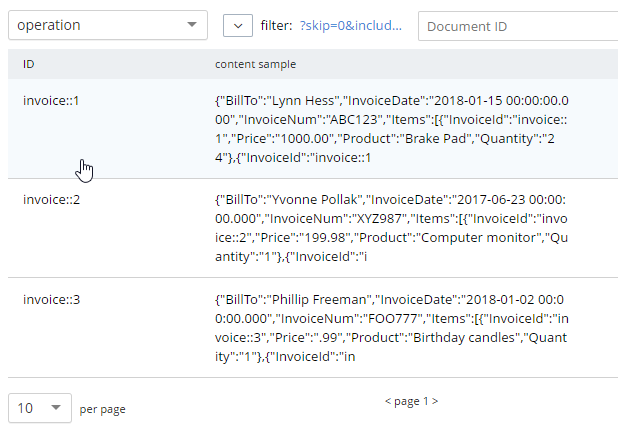
Puede eliminar o vaciar el cubo de almacenamiento, ya que ahora contiene datos obsoletos. O puedes conservarlo para seguir experimentando.
Resumen
Migrar datos directamente a Couchbase Server puede ser tan fácil como importar vía CSV y transformar con unas pocas líneas de N1QL. Hacer el modelado real y tomar decisiones requiere más tiempo y reflexión. Una vez que decidas cómo modelar, N1QL te da la flexibilidad para transformar datos relacionales planos y dispersos en un modelo de documentos orientado a la agregación.
Más recursos:
- Uso de Hackolade para colaborar en el modelado de datos JSON.
- Parte de la serie SQL Server aborda el mismo tipo de decisiones de modelado de datos JSON
- Cómo Couchbase supera a Oraclesi está pensando en trasladar algunos de sus datos fuera de Oracle
- Pasar de Relational a NoSQL: Cómo empezar libro blanco.
No dude en ponerse en contacto conmigo si tiene alguna pregunta o necesita ayuda. Soy
@mgroves en Twitter. También puede hacer preguntas en Foros de Couchbase. Hay expertos en N1QL allí que son muy receptivos y pueden ayudarte a escribir el N1QL para acomodar tu modelado de datos JSON.