Introducción
Como la mayoría de vosotros sabéis, Couchbase es una base de datos que proporciona a los usuarios una serie de opciones de consistencia y tolerancia a fallos para asegurar que el estado de sus datos cumple ciertos criterios o garantías. Los usuarios pueden especificar distintos niveles de replicación, persistencia, réplicas, grupos de servidores, etc. para garantizar que sus datos sean duraderos, consistentes y correctos bajo ciertos escenarios de fallos y operaciones de cluster. Para la próxima versión 6.5.0, se han introducido las nuevas mejoras siguientes durabilidad proporcionarán a los usuarios aún más seguridad y garantías en caso de fallos. Como reconocemos que las garantías son tan buenas como sus pruebas, vamos a dar un vistazo en profundidad a cómo usamos Jespen, un estándar de la industria, para probar la durabilidad de las bases de datos en Couchbase.
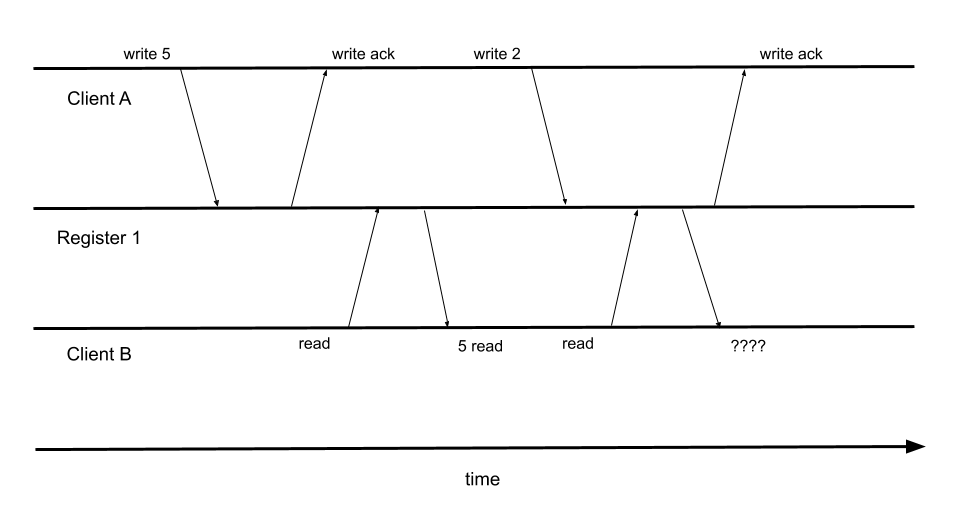
El marco Jepsen funciona disparando operaciones de cliente a un clúster mientras inyecta simultáneamente algún tipo de caos como particiones de red, matanza de procesos, ralentización de discos, etc. A continuación, Jepsen analiza el historial de operaciones con comprobadores de historial de operaciones integrados o personalizados. En particular, Jepsen viene con un consistencia linealizable comprobador. Couchbase, con los nuevos niveles de durabilidad mejorados en 6.5.0, sólo afirma ser coherencia secuencial. Sin embargo, la consistencia linealizable implica consistencia secuencial [1]. Por lo tanto, pasar la comprobación de consistencia linealizable también implica que el historial de operaciones es realmente consistente secuencialmente. Sin embargo, no superar la comprobación de consistencia linealizable no implica que el historial de la operación no sea secuencialmente consistente. En resumen, cuando una operación pasa el chequeo de consistencia linealizable, podemos asumir que Couchbase es secuencialmente consistente. Si una operación falla el chequeo de consistencia linealizable, Couchbase aún puede ser secuencialmente consistente, pero se requiere mayor investigación para confirmarlo.
Nuestro objetivo con Jepsen es probar, desde muchos ángulos diferentes, que nuestro cliente Java SDK y el motor KV del lado del servidor funcionan al unísono para: 1.) No perder nunca escrituras reconocidas; y 2.) Proporcionar, como mínimo, un modelo de consistencia secuencial mientras se aplican al sistema operaciones de cluster y fallos.
Arquitectura
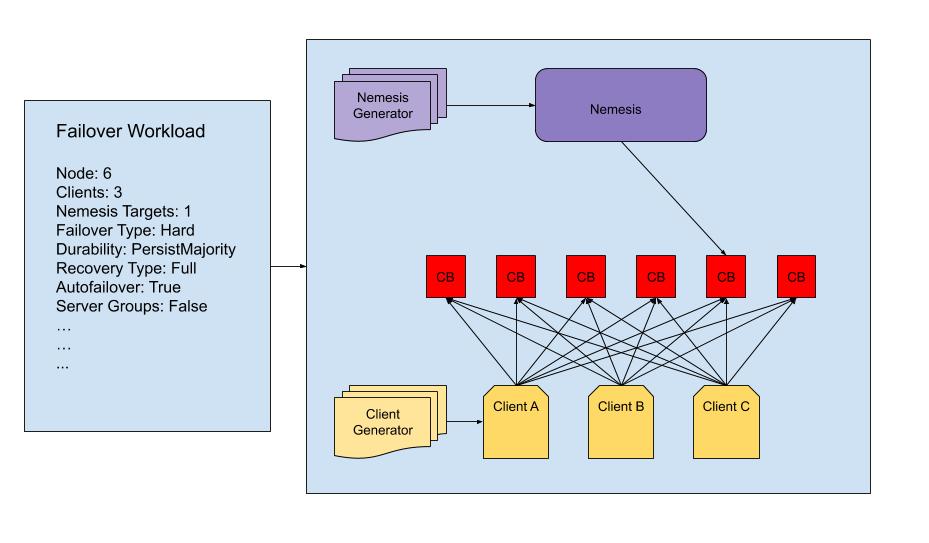
Jepsen proporciona interfaces para las siguientes abstracciones: Database, Client, Checker, Nemesis, Generators, y Workload. Para crear una prueba Jepsen, tuvimos que implementar todos estos específicamente para Couchbase. Cada test es una combinación de estas abstracciones y parámetros adicionales.
Base de datos
Implementamos la lógica de configuración, desmontaje y recopilación de registros para un clúster de Couchbase. Esta lógica incluye soporte para configuraciones personalizadas de cubos, grupos de servidores y conmutación automática por error. El soporte completo para cada posible configuración de bucket y cluster no tiene mucho sentido porque el número de posibles clusters hará que probar todas las permutaciones sea inviable. Sin embargo, hemos creado soporte para todas las configuraciones y opciones de cluster más críticas.
Cliente
Hemos implementado dos clientes diferentes: un cliente "register" y un cliente "set". El cliente de registro escribirá, leerá y comparará e intercambiará valores de claves independientes en un bucket de Couchbase. El cliente "set" sólo añade y elimina documentos de un bucket. Puedes pensar en el bucket como el conjunto y en el documento como un miembro de ese conjunto. Utilizamos este cliente con un verificador de conjuntos personalizado en lugar del verificador de linealidad, ya que no estamos actualizando ningún documento. Las pruebas que utilizan el cliente de conjuntos y el verificador de conjuntos funcionan entrelazando fases de adición de documentos a un cubo o de eliminación de documentos de un cubo.
Ambos clientes reciben operaciones de un proceso generador. (Más adelante hablaremos de ello).
Se debe tener especial cuidado para manejar los errores del cliente. Por ejemplo, una DurabilityImpossibleException y una RequestTimeoutException deben ser tratadas de forma diferente por Jepsen. En la primera, sabemos que la operación ha fallado, pero en la segunda, la operación podría haber tenido éxito. En el caso de que no podamos distinguir si una operación ha fallado o ha tenido éxito, el comprobador de linealidad de Jepsen realizará una comprobación asumiendo que la operación ha fallado y otra asumiendo que la operación ha pasado. El efecto es que se duplica el tiempo de comprobación para cada operación ambigua. Por lo tanto, queremos escenarios de prueba que limiten el número potencial de resultados de este tipo de operaciones. El comprobador de linealidad pasará si al menos una de las dos historias posibles es linealizable.
Checker
Para nuestras pruebas, podemos elegir entre tres comprobadores: comprobador de linealidad, comprobador de conjuntos y comprobador de cordura. El verificador de linealidad viene con Jepsen y se utiliza para comprobar la coherencia de claves independientes en un cubo. Hemos implementado un comprobador de conjuntos para asegurarnos de que las pruebas con el cliente de conjuntos tienen el conjunto correcto de documentos en un cubo. Por último, hemos implementado un verificador de sanidad que garantizará que la propia prueba haya pasado por la secuencia de cambios de estado del clúster sin errores. Por ejemplo, una prueba puede implicar un reequilibrio que falla cuando no debería. En este caso, el verificador de sanidad marcará la prueba como "desconocida" en lugar de "fallida", ya que estamos denotando pruebas fallidas como aquellas que fallan el verificador de conjunto o el verificador de linealidad. El verificador de sanidad también se asegura de que al menos algunas operaciones tengan éxito.
Némesis
Tradicionalmente en Jepsen, una némesis es un proceso que recibirá operaciones de un proceso generador y luego actuará contra el sistema en consecuencia. Por ejemplo, la némesis de partición incorporada puede recibir una operación de bloqueo y restauración que particionará la red y restaurará la red entre dos nodos. La mayoría de las némesis incorporadas son suficientes para escenarios muy básicos, pero queríamos probar escenarios adicionales que puedan, por ejemplo, ralentizar un disco aleatorio en un grupo de servidores aleatorio, matar el proceso memcached del mismo servidor y finalmente restaurar el disco.
Para poder probar cualquier escenario que queramos, creamos una única némesis de Couchbase que modela el cluster de Couchbase a través de cambios de estado desde un estado inicial. Mantenemos un mapa de nodos y su estado de red, servidor, disco y cluster. Cada vez que se produce una operación, el estado se actualiza para reflejar el cambio en el sistema. Las operaciones que se pasan a nuestra némesis especifican las opciones de orientación de los nodos, una operación y los parámetros de la operación. Las opciones de selección de nodos indican a la némesis, por ejemplo, que se dirija a un subconjunto aleatorio de nodos de tamaño dos de entre todos los nodos sanos de un grupo de servidores aleatorio. Esta es la razón principal por la que rastreamos el estado de los nodos: nos da más flexibilidad en la forma en que nuestra némesis puede actuar.
Nuestra némesis tiene soporte para las siguientes acciones: conmutación por error (graceful y hard), recuperación (completa y delta), partición de red personalizada, recuperación de red, espera de conmutación por error automática, reequilibrio en un conjunto de nodos, reequilibrio fuera de un conjunto de nodos, intercambio de reequilibrio de dos conjuntos de nodos, fallo de un reequilibrio, matar un proceso (memcached, babysitter, ns_server) en un conjunto de nodos, reiniciar los mismos procesos en un conjunto de nodos, ralentizar el cliente dcp, reiniciar el cliente dcp, activar la compactación, hacer fallar un disco en un conjunto de nodos, ralentizar un disco en un conjunto de nodos y recuperar un disco en un conjunto de nodos. Tenemos previsto soportar más operaciones némesis en el futuro.
Generadores
Otra pieza clave de una prueba Jepsen son los generadores de operaciones cliente y némesis. Estos generadores crearán una secuencia finita o infinita de operaciones. Cada prueba tendrá su propio generador némesis, pero lo más probable es que comparta un generador cliente común. Un generador némesis, por ejemplo, podría ser una secuencia de partición, suspensión y restauración, repetida infinitamente. Un generador de cliente especificará una secuencia aleatoria e infinita de operación de cliente, así como los parámetros asociados, como el nivel de durabilidad, la clave del documento, el nuevo valor a escribir o cas, etc. Cuando se inicia una prueba, el generador de cliente alimenta operaciones de cliente al cliente y el generador de némesis alimenta operaciones a la némesis. La prueba continuará hasta que el generador de némesis haya completado un número determinado de operaciones, se alcance un límite de tiempo o se produzca un error.
Carga de trabajo
Una carga de trabajo Jepsen es simplemente un mapa que une todos los componentes anteriores - junto con cualquier parámetro adicional - en una sola prueba. Nuestras cargas de trabajo modificarán la lógica generadora de némesis y clientes en función de los parámetros de entrada, como la activación de grupos de servidores y la conmutación por error automática.
Desafíos
Durante la elaboración de estas pruebas nos encontramos con dos problemas principales, ambos derivados de la escasez de recursos: 1.) El elevado número de permutaciones de la configuración del clúster; y 2.) El tiempo necesario para ejecutar el verificador de linealidad.
Dado que Couchbase es una plataforma de datos compleja y altamente personalizable, hay cientos de ajustes que modificar. Algunos ajustes son binarios (por ejemplo: conmutación automática por error activada), mientras que otros son continuos (cuota de RAM para KV). Esto crea un número extremadamente alto de posibles estados iniciales del clúster para probar. Luego, con las casi infinitas formas en que podríamos componer nuestras operaciones némesis, tenemos un espacio de pruebas demasiado grande para cubrirlo por completo.
El comprobador de linealizabilidad, aunque es muy útil y fruto de una investigación muy buena, tiene algunas limitaciones. El tiempo que tarda el verificador en analizar un historial crece exponencialmente con el número de operaciones. Además, las operaciones ambiguas también provocan un crecimiento exponencial. Así que tenemos un problema: queremos forzar al máximo a los clientes durante la duración de una prueba, pero si forzamos demasiado a los clientes, el verificador puede quedarse sin memoria y no analizar el historial. Esto también significa que queremos que las pruebas se ejecuten lo más rápido posible, pero esto reducirá la superficie para encontrar un error.
Soluciones
Para superar estos retos, decidimos hacer lo siguiente: centrarnos en un subconjunto de parámetros de prueba que son los más críticos para nuestros clientes, mantener las pruebas lo más cortas posible y ejecutarlas con la mayor frecuencia posible. Al probar únicamente parámetros comunes como las réplicas de cubos, todos los nuevos niveles de durabilidad mejorados, la conmutación por error automática, etc., podemos centrarnos en un conjunto manejable de pruebas que constituirán una base sólida para demostrar nuestras garantías de durabilidad.
Primero nos centramos en las configuraciones críticas de KV, con planes para añadir nuevos servicios y configuraciones (consulta, índice, xdcr, etc.) a medida que se añadan nuevas funciones y a petición del cliente. A continuación, ajustamos nuestro némesis para que funcionara lo más rápido posible, reduciendo los tiempos de espera, sondeando el estado de las operaciones, limitando el número de operaciones y no cargando ningún documento. Tener cubos vacíos al comienzo de las pruebas acelera los reequilibrios posteriores durante la prueba. Sin embargo, necesitamos probar escenarios en los que los cubos tienen grandes cantidades de datos y una cantidad relativamente pequeña de RAM por cubo. Estos escenarios de alta densidad de datos, que están en preparación, requerirán mucho más tiempo de ejecución. Tenemos que ajustar el tamaño inicial de la carga de datos para que las operaciones de reequilibrio sean lo suficientemente rápidas como para que el comprobador de linealidad no se quede sin memoria. Además, debido al límite de velocidad de las operaciones del cliente, tenemos que ejecutar las pruebas varias veces. Con una tasa de operaciones de cliente más lenta, hay menos probabilidades de que dos operaciones se solapen o de que una operación se produzca en un momento de error, pero si ejecutamos la prueba varias veces podemos aumentar el número total de operaciones solapadas y, con suerte, descubrir un error.
Para ejecutar las pruebas con la mayor frecuencia posible, hemos creado una jerarquía de suites de pruebas. Nuestras suites se dividen en cuatro categorías: sanidad, diaria, semanal y completa. El conjunto de pruebas de sanidad tiene un pequeño subconjunto de pruebas que deben ejecutarse después de que lleguen nuevas confirmaciones, y tardan menos de una hora en completarse. El conjunto diario, más amplio, no debería tardar más de 12 horas en ejecutarse, y el semanal debería terminar en dos días. El conjunto de pruebas completo es una lista de todas las pruebas y tarda aproximadamente una semana en completarse. Para crear las suites reducimos la suite de pruebas completa eliminando pruebas similares y manteniendo la cobertura al máximo. Actualmente, nuestro conjunto completo tiene 612 pruebas, el semanal tiene 396, el diario tiene 227 y el de cordura tiene 6 pruebas. También tenemos un conjunto de errores de versiones anteriores (4.6.x, 5.0.x, 5.5.x, 6.0.x) que utilizamos para verificar que ya no están presentes en el producto. Ejemplos de este tipo de errores son MB-29369 y MB-29480.
Resultados
Nuestras pruebas Jepsen han tenido éxito en encontrar varios bugs dentro de Couchbase. Estos fallos se dividen en dos categorías: fallos generales del producto y fallos de durabilidad y consistencia de los datos. Los bugs de durabilidad y consistencia son la razón por la que empezamos nuestras pruebas Jepsen, por lo que los consideramos de mayor importancia ya que tenemos una suite de regresión funcional completa que captura bugs generales del producto. Algunos ejemplos de errores de durabilidad y consistencia que hemos encontrado son MB-35135, MB-35060y MB-35053.
Nuestro trabajo inicial con Jepsen y los errores que nos ha ayudado a encontrar nos han dado una mayor confianza en la capacidad de Couchbase para mantener tus datos seguros a través de una amplia gama de escenarios de fallo y operaciones de clúster. Sin embargo, se necesitan pruebas continuas, ya que Jepsen puede detectar un error después de cientos de ejecuciones. Seguiremos ejecutando nuestras pruebas de Jepsen diaria y semanalmente, al tiempo que desarrollamos la compatibilidad con más escenarios. Jepsen es una herramienta indispensable a la hora de construir sistemas con garantías de coherencia y durabilidad de los datos, y seguiremos utilizándola y ampliando sus capacidades.
Enlaces:
[1] https://courses.csail.mit.edu/6.852/01/papers/p91-attiya.pdf
[3] https://jepsen.io/consistency/models/linearizable
[4] https://jepsen.io/consistency/models/sequential
[5] https://github.com/jepsen-io/jepsen
Más recursos
Descargar
Descargar Couchbase Server 6.5
Documentación
Notas de la versión de Couchbase Server 6.5
Novedades de Couchbase Server 6.5
Blogs
Blog: Anuncio de Couchbase Server 6.5 GA - Novedades y mejoras
Blog: Couchbase lleva las Transacciones Distribuidas Multidocumento ACID a NoSQL