En el mundo actual, impulsado por los datos, la capacidad de recopilar y preparar datos de forma eficiente es crucial para el éxito de cualquier aplicación. Tanto si estás desarrollando un chatbot, un sistema de recomendación o cualquier solución basada en IA, la calidad y la estructura de tus datos pueden hacer que tu proyecto sea un éxito o un fracaso. En este artículo, te llevaremos a explorar el proceso de recopilación de información y fragmentación inteligente, centrándonos en cómo preparar los datos para Generación mejorada por recuperación (RAG) en cualquier aplicación con la base de datos de su elección.
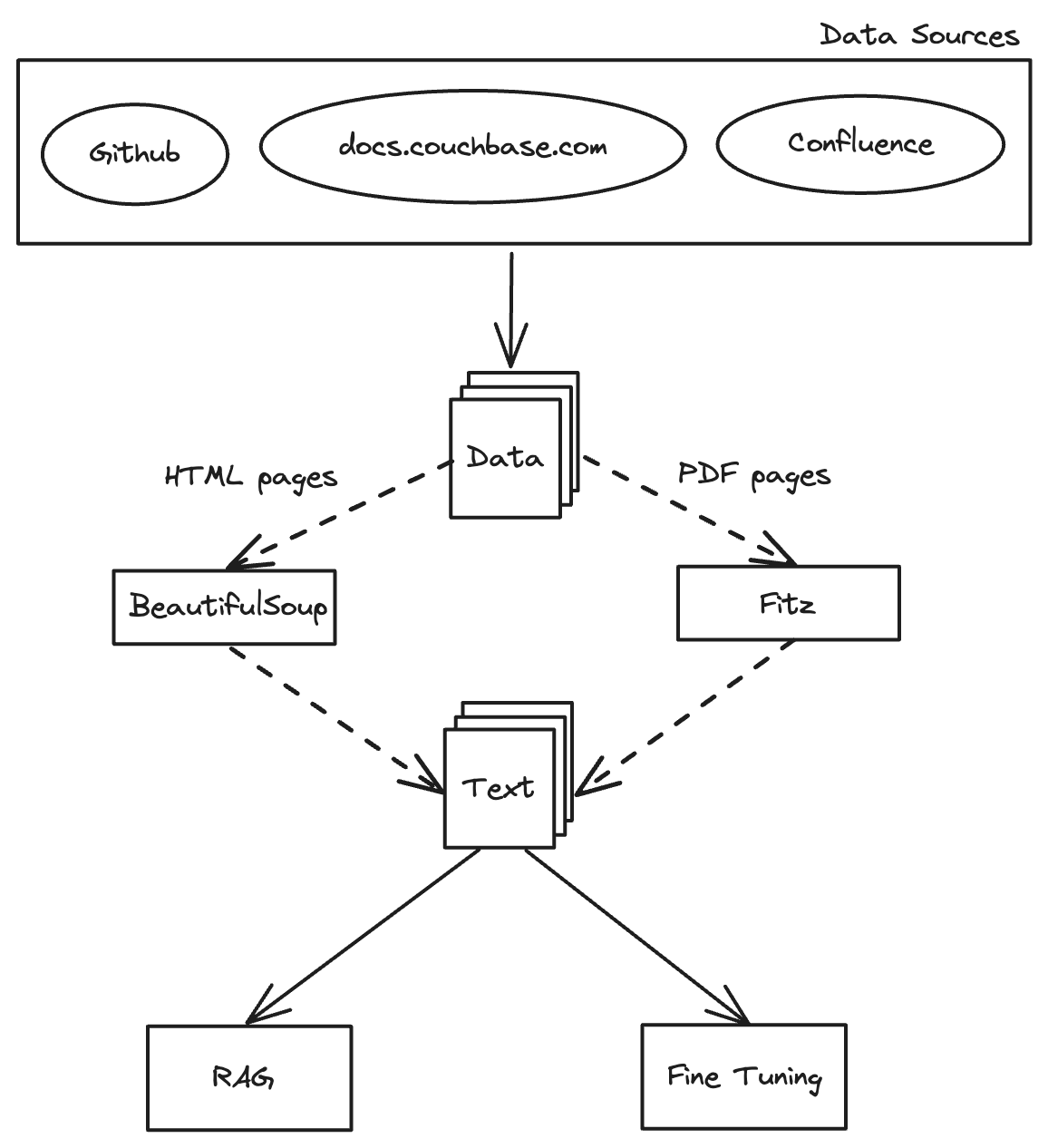
Resumen de la conversión de documentos para el GAR
Recogida de datos: La base del GAR
La magia de la chatarra
Imagínese una araña, no de las espeluznantes, sino una diligente araña bibliotecaria en la inmensa biblioteca de Internet. Esta araña, encarnada por Scrapy's Araña comienza en la entrada (la URL inicial) y visita metódicamente todas las habitaciones (páginas web), recopilando valiosos libros (páginas HTML). Cada vez que encuentra una puerta a otra habitación (un hipervínculo), la abre y continúa su exploración, asegurándose de que ninguna habitación quede sin revisar. Así es como funciona Scrapy: recopilando sistemática y meticulosamente cada pieza de información.
Aprovechamiento de Scrapy para la recogida de datos
Chatarra es un framework basado en Python diseñado para extraer datos de sitios web. Es como darle superpoderes de araña a nuestra bibliotecaria. Con Scrapy, podemos construir arañas web que naveguen por páginas web y extraigan la información deseada con precisión. En nuestro caso, desplegamos Scrapy para rastrear el sitio web de documentación de Couchbase y descargar páginas HTML para su posterior procesamiento y análisis.
Configuración del proyecto Scrapy
Antes de que nuestra araña pueda comenzar su viaje, necesitamos configurar un proyecto Scrapy. He aquí cómo hacerlo:
- Instalar Scrapy: Si aún no has instalado Scrapy, puedes hacerlo usando pip:
1pip install scrapy
- Crear un nuevo proyecto Scrapy: Configure su nuevo proyecto Scrapy con el siguiente comando:
1scrapy startproject couchbase_docs
Creación de la araña
Con el proyecto Scrapy configurado, ahora creamos la araña que rastreará el sitio web de documentación de Couchbase y descargará las páginas HTML. Así es como se ve:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from pathlib import Path import scrapy class CouchbaseSpider(scrapy.Spider): name = "couchbase" start_urls = ["https://docs.couchbase.com/home/index.html",] def parse(self, response): # Download HTML content of the current page page = response.url.split("/")[-1] filename = f"{page}.html" Path(filename).write_bytes(response.body) self.log(f"Saved file {filename}") # Extract links and follow them for href in response.css("ul a::attr(href)").getall(): if href.endswith(".html") or "docs.couchbase.com" in href: yield response.follow(href, self.parse) |
Correr la araña
Para ejecutar la araña e iniciar el proceso de recogida de datos, ejecute el siguiente comando dentro del directorio del proyecto Scrapy:
|
1 |
scrapy crawl couchbase |
Este comando iniciará la araña, que comenzará a rastrear las URL especificadas y a guardar el contenido HTML. La araña extrae enlaces de cada página y los sigue recursivamente, garantizando una recopilación exhaustiva de datos.
Al automatizar la recopilación de datos con Scrapy, nos aseguramos de que todo el contenido HTML relevante del sitio web de documentación de Couchbase se recupera de forma eficiente y sistemática, sentando una base sólida para su posterior procesamiento y análisis.
Extracción de contenido textual: Transformación de datos brutos
Tras recopilar las páginas HTML del sitio web de documentación de Couchbase, el siguiente paso crucial es extraer el contenido de texto. Esto transforma los datos en bruto en un formato utilizable para su análisis y posterior procesamiento. Además, es posible que tengamos archivos PDF que contengan datos valiosos, que también extraeremos. Aquí, discutiremos cómo usar scripts de Python para analizar archivos HTML y PDFs, extraer datos de texto, y almacenarlos para su posterior procesamiento.
Extracción de texto de páginas HTML
Para extraer el contenido de texto de las páginas HTML, utilizaremos un script de Python que analiza los archivos HTML y recupera los datos de texto encerrados dentro de <p> etiquetas. Este enfoque captura el cuerpo principal del texto de cada página, excluyendo cualquier marcado HTML o elemento estructural.
Función de Python para la extracción de texto
A continuación se muestra una función de Python que demuestra cómo extraer contenido de texto de páginas HTML y almacenarlo en archivos de texto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from bs4 import BeautifulSoup def get_data(html_content): soup = BeautifulSoup(html_content, "html.parser") title = str(soup).split('<title>')[1].split('</title>')[0] if " | Couchbase Docs" in title: title = title[:(title.index(" | Couchbase Docs"))].replace(" ", "_") else: title = title.replace(" ", "_") data = "" lines = soup.find_all('p') for line in lines: data += " " + line.text return title, data |
¿Cómo utilizarlo?
Para utilizar el obtener_datos() incorpórela a su script o aplicación Python y proporcione el contenido HTML como parámetro. La función devolverá el contenido de texto extraído.
|
1 2 3 4 |
html_content = '<html><head><title>Sample Page</title></head><body><p>This is a sample paragraph.</p></body></html>' title, text = get_data(html_content) print(title) # Output: Sample_Page print(text) # Output: This is a sample paragraph. |
Extraer contenido de texto de PDF
Para extraer el contenido textual de los PDF, utilizaremos un script de Python que lee un archivo PDF y recupera sus datos. Este proceso garantiza la captura de toda la información textual relevante para el análisis.
Función de Python para la extracción de texto
A continuación se muestra una función de Python que demuestra cómo extraer contenido de texto de archivos PDF:
|
1 2 3 4 5 6 7 8 |
from PyPDF2 import PdfReader def extract_text_from_pdf(pdf_file): reader = PdfReader(pdf_file) text = '' for page in reader.pages: text += page.extract_text() return text |
¿Cómo utilizarlo?
Para utilizar la función extract_text_from_pdf(), incorpórela a su script o aplicación Python y proporcione la ruta del archivo PDF como parámetro. La función devolverá el contenido de texto extraído.
|
1 2 |
pdf_path = 'sample.pdf' text = extract_text_from_pdf(pdf_path) |
Con el contenido de texto extraído y guardado, hemos completado el proceso de obtención de datos de la documentación de Couchbase.
Agrupación: Cómo gestionar los datos
Imagina que tienes una novela larga y quieres hacer un resumen. En lugar de leer todo el libro de una vez, lo divides en capítulos, párrafos y frases. De esta forma, puedes entender y procesar fácilmente cada parte, haciendo la tarea más manejable. Del mismo modo, la fragmentación en el tratamiento de textos ayuda a dividir grandes textos en unidades más pequeñas y significativas. Al organizar el texto en trozos manejables, podemos facilitar el procesamiento, la recuperación y el análisis de la información.
Agrupación semántica y de contenidos para el GAR
Para la Generación Mejorada por Recuperación (RAG), la fragmentación es especialmente importante. Aplicamos métodos de fragmentación semántica y de contenido para optimizar los datos para el proceso RAG, que consiste en recuperar información relevante y generar respuestas basadas en esa información.
Divisor de texto de caracteres recursivos

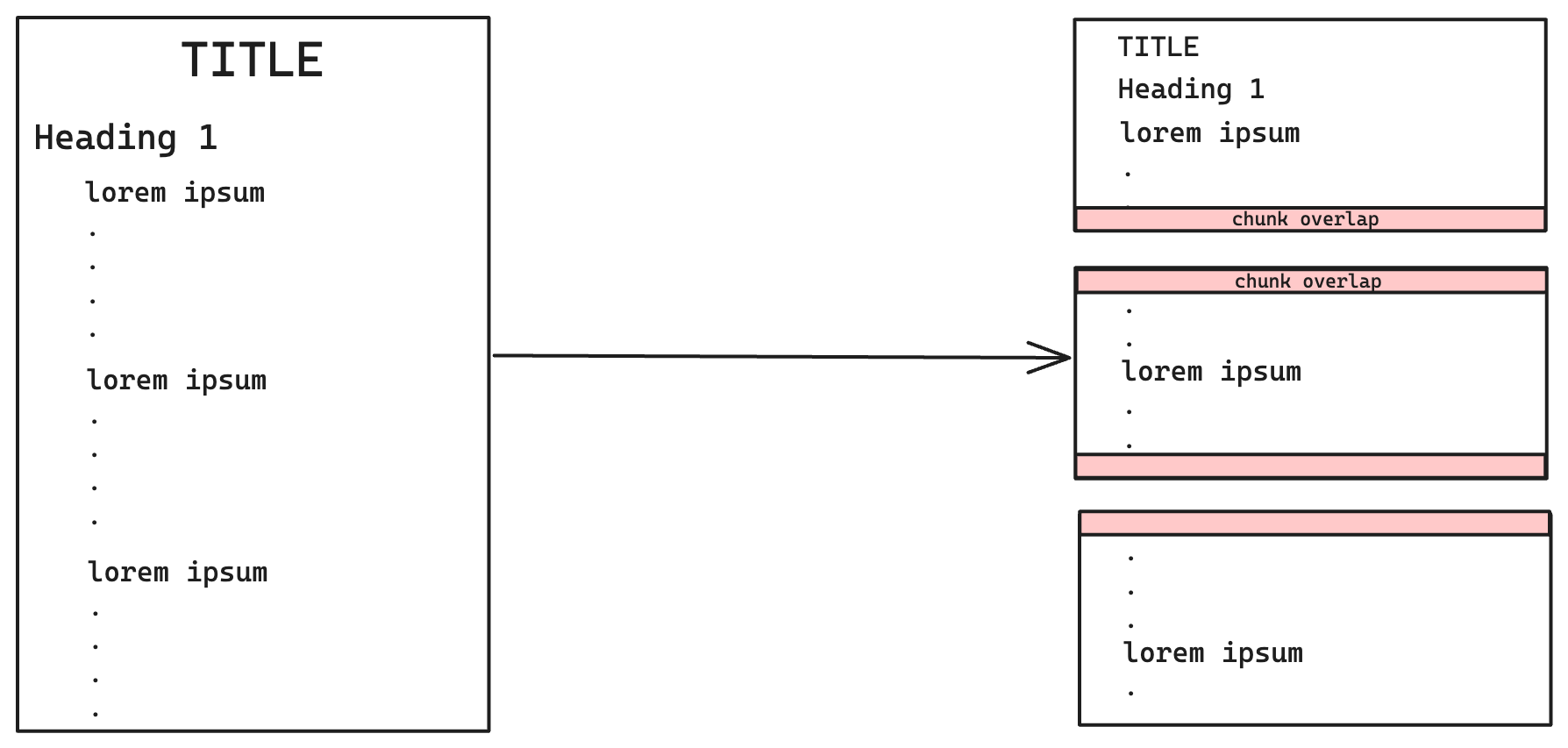
Divisor de texto de caracteres recursivo El chunking de Langchain consiste en descomponer un texto en trozos más pequeños utilizando patrones recursivos dentro de los caracteres del texto. Esta técnica utiliza separadores como \n\n (doble línea nueva), \n (nueva línea), (espacio) y "" (cadena vacía).
Agrupación semántica


La fragmentación semántica es una técnica de tratamiento de textos que se centra en agrupar palabras o frases en función de su significado semántico o contexto. Este enfoque mejora la comprensión al crear trozos significativos que captan las relaciones subyacentes en el texto. Es especialmente útil para tareas que requieren un análisis detallado de la estructura del texto y la organización del contenido.
Aplicación de la fragmentación semántica y de contenidos
En nuestro proyecto hemos aplicado métodos de fragmentación semántica y de contenido. La fragmentación semántica preserva la estructura jerárquica del texto y garantiza que cada fragmento mantenga su integridad contextual. La fragmentación por contenido se aplicó para eliminar los trozos redundantes y optimizar la eficiencia de almacenamiento y procesamiento.
Aplicación de Python
He aquí una implementación en Python del chunking semántico y de contenido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import hashlib from langchain.text_splitter import RecursiveCharacterTextSplitter # Global set to store unique chunk hash values across all files global_unique_hashes = set() def hash_text(text): # Generate a hash value for the text using SHA-256 hash_object = hashlib.sha256(text.encode()) return hash_object.hexdigest() def chunk_text(text, title, Chunk_size=2000, Overlap=50, Length_function=len, debug_mode=0): global global_unique_hashes chunks = RecursiveCharacterTextSplitter( chunk_size=Chunk_size, chunk_overlap=Overlap, length_function=Length_function ).create_documents([text]) if debug_mode: for idx, chunk in enumerate(chunks): print(f"Chunk {idx+1}: {chunk}\n") print('\n') # Deduplication mechanism unique_chunks = [] for chunk in chunks: chunk_hash = hash_text(chunk.page_content) if chunk_hash not in global_unique_hashes: unique_chunks.append(chunk) global_unique_hashes.add(chunk_hash) for sentence in unique_chunks: sentence.page_content = title + " " + sentence.page_content return unique_chunks |
A continuación, estos trozos optimizados se incrustan y almacenan en el clúster Couchbase para una recuperación eficiente, garantizando una integración perfecta con el proceso RAG.
Al emplear técnicas de fragmentación semántica y de contenido, hemos estructurado y optimizado eficazmente los datos textuales para el proceso RAG y su almacenamiento en el clúster Couchbase. El siguiente paso es incrustar los trozos que acabamos de generar.
Incrustación de trozos: La galaxia de los datos
Imagine cada fragmento de texto como una estrella en una galaxia inmensa. Al incrustar estos trozos, asignamos a cada estrella una ubicación precisa en esta galaxia, basándonos en sus características y relaciones con otras estrellas. Este mapa espacial nos permite navegar por la galaxia con más eficacia, encontrar conexiones y comprender el universo más amplio de la información.
Incrustación de fragmentos de texto para el GAR
La incrustación de trozos de texto es un paso crucial en el proceso de Generación Mejorada de Recuperación (RAG). Consiste en transformar el texto en vectores numéricos que capturan el significado semántico y el contexto de cada fragmento, lo que facilita a los modelos de aprendizaje automático el análisis y la generación de respuestas.
Utilización del modelo BAAI BGE-M3
Para incrustar los trozos, utilizamos la función Modelo BAAI BGE-M3. Este modelo es capaz de incrustar texto en un espacio vectorial de alta dimensión, capturando el significado semántico y el contexto de cada trozo.
Función de incrustación
La función de incrustación toma los trozos generados en el paso anterior y los incrusta en un espacio vectorial de 1024 dimensiones utilizando el modelo BAAI BGE-M3. Este proceso mejora la representación de cada trozo, lo que facilita un análisis más preciso y rico en contextos.
Script Python para incrustación
Aquí tienes un script en Python que demuestra cómo incrustar trozos de texto utilizando el modelo BAAI BGE-M3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import json import numpy as np from json import JSONEncoder from baai_model import BGEM3FlagModel embed_model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) class NumpyEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return JSONEncoder.default(self, obj) def embed(chunks): embedded_chunks = [] for sentence in chunks: emb = embed_model.encode(str(sentence.page_content), batch_size=12, max_length=600)['dense_vecs'] embedding = np.array(emb) np.set_printoptions(suppress=True) json_dump = json.dumps(embedding, cls=NumpyEncoder) embedded_chunk = { "data": str(sentence.page_content), "vector_data": json.loads(json_dump) } embedded_chunks.append(embedded_chunk) return embedded_chunks |
¿Cómo utilizarlo?
Para utilizar la función embed(), incorpórela a su script o aplicación Python y proporcione como entrada los trozos generados en los pasos anteriores. La función devolverá una lista de trozos incrustados.
|
1 2 3 4 5 6 7 |
chunks = [ # Assume chunks is a list of text chunks generated previously {"page_content": "This is the first chunk of text."}, {"page_content": "This is the second chunk of text."} ] embedded_chunks = embed(chunks) |
Estos fragmentos optimizados, ahora integrados en un espacio vectorial de alta dimensión, están listos para su almacenamiento y recuperación, lo que garantiza una utilización eficiente de los recursos y una integración perfecta con el proceso GAR. Al incrustar los trozos de texto, transformamos el texto bruto en un formato que los modelos de aprendizaje automático pueden procesar y analizar con eficacia, lo que permite respuestas más precisas y contextualizadas en el sistema GAR.
Almacenamiento de trozos incrustados: Recuperación eficaz
Una vez incrustados los trozos de texto, el siguiente paso es almacenar estos vectores en una base de datos. Estos trozos incrustados pueden empujarse a bases de datos vectoriales o bases de datos tradicionales con soporte de búsqueda vectorial, como Couchbase, Elasticsearch o Pinecone, para facilitar una recuperación eficiente para aplicaciones de generación mejorada de recuperación (RAG).
Bases de datos vectoriales
Las bases de datos vectoriales están diseñadas específicamente para manejar y buscar vectores de alta dimensión de forma eficiente. Al almacenar trozos incrustados en una base de datos vectorial, podemos aprovechar las capacidades de búsqueda avanzada para recuperar rápidamente la información más relevante basándonos en el contexto y el significado semántico de las consultas.
Integración con aplicaciones RAG
Con los datos preparados y almacenados, ya están listos para su uso en aplicaciones GAR. Los vectores incrustados permiten a estas aplicaciones recuperar información contextualmente relevante y generar respuestas más precisas y significativas, mejorando la experiencia general del usuario.
Conclusión
Siguiendo esta guía, hemos preparado con éxito los datos para la Generación Mejorada de Recuperación. Hemos tratado la recopilación de datos mediante Scrapy, la extracción de contenido textual de HTML y PDF, las técnicas de fragmentación y la incrustación de fragmentos de texto mediante el modelo BAAI BGE-M3. Estos pasos garantizan que los datos estén organizados, optimizados y listos para su uso en aplicaciones RAG.
Para más contenidos técnicos y atractivos, consulte otros blogs relacionados con la búsqueda de vectores en nuestro sitio web y permanezca atento a la próxima parte de esta serie.