Recapitulemos
En las dos entregas anteriores de esta seriediscutimos los drivers detrás de la creación de microservicios. También vimos por qué Couchbase es el almacén de datos perfecto para utilizar con una arquitectura de este tipo. También vimos tres variantes de un microservicio de perfil de usuario de ejemplo. Dos fueron escritas en Python, y una fue escrita en Node.js para comparar. En esta última parte de la serie, discutiremos un método para generar datos de prueba para el esquema del microservicio.
¿Por qué utilizar datos de prueba?
Unas pruebas rigurosas son fundamentales para lanzar un software estable. En una buena estrategia de pruebas intervienen muchos elementos. En la última década, el término "DevOps" se ha utilizado a menudo para referirse tanto a las herramientas utilizadas en el desarrollo y las pruebas de software como a la cultura, los procesos y los procedimientos que deben aplicarse para lograr un desarrollo rápido y ágil. Independientemente de la terminología, hay un hilo común: la automatización y la orquestación. Estas dos cosas pueden ser fácilmente su propia serie de blog, por lo que no nos detendremos demasiado en ellos, excepto para decir que la generación de datos de prueba es un aspecto esencial de DevOps y el desarrollo ágil de software y pruebas.
Personalmente he caído en la trampa de no tener un buen conjunto de datos de desarrollo. Por conveniencia, creé manualmente algunos datos para que se ajustaran al esquema deseado y así poder hacer pruebas unitarias sobre el código. Pero al día siguiente, me di cuenta de que el código que funcionaba bien con mi pequeño conjunto de datos no funcionaba demasiado bien cuando se ejecutaba contra una base de datos de prueba con miles de registros y datos más realistas.
Generación de datos JSON para probar el microservicio Python
Hay muchas formas de introducir datos de prueba en una base de datos de prueba o de desarrollo. Un método consiste en copiar y desinfectar los datos de producción, si es posible. Puede que no sea factible disponer de copias de producción completas para múltiples entornos de desarrollo y prueba en función de los recursos disponibles. Las plataformas de bases de datos deben tener el tamaño adecuado, y hay que tener cuidado de eliminar los datos sensibles por razones de cumplimiento y seguridad. Las copias de producción completas deben ser un requisito para los entornos de pruebas de regresión y de desarrollo previo. La generación de datos sintéticos y aleatorios con un conjunto de datos mínimo para las pruebas unitarias y el desarrollo suele ser adecuada.
Con una base de datos relacional, puede ser un reto crear una instancia de base de datos con un subconjunto de tablas porque los modelos relacionales normalmente requieren que todas las estructuras de datos estén presentes. Sin embargo, con el formato de documento JSON de Couchbase, es mucho más fácil hacerlo. Mirando el ejemplo del microservicio, el esquema se construyó alrededor de Scopes y Collections de Couchbase. Estos podrían ser fácilmente parte de un esquema más grande con más colecciones y ámbitos. Pero todo lo que necesitamos son las colecciones para acceder a las claves, los perfiles de usuario y las imágenes de usuario, ya que eso es todo lo que nuestro servicio de ejemplo necesita para funcionar.
En la segunda parte de la serie de blogs, utilizamos JMeter para realizar pruebas de rendimiento. Para realizar pruebas de rendimiento, la base de datos debe tener al menos miles de registros para que JMeter disponga de un conjunto de datos razonable para la generación de pruebas. El microservicio simplemente obtiene elementos de perfil y los devuelve a través de la API REST. Se supone que otros componentes de la aplicación consumen los datos y ejecutan la lógica empresarial utilizando los resultados.
Volviendo a las tres colecciones de perfiles, a continuación se muestra un ejemplo de un documento de la colección datos_usuario colección. El servicio no comprueba si el campo de imagen tiene un ID que haga referencia a un registro de imagen. El servicio sólo devuelve los datos del perfil o los datos de la imagen. Se supone que cualquiera que lo consuma manejará esa lógica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": 1, "nombre": "Michael Jones", "apodo": "mjones", "foto": "", "user_id": "michaeljones2104", "email": "michael.jones@example.com", "email_verificado": "Verdadero", "nombre": "Michael", "apellido": "Jones", "dirección": "0208 River Parkway", "ciudad": "Strongdol", "estado": "IL", "código_zip": "29954", "teléfono": "363-555-9036", "fecha_de_nacimiento": "10/27/1958" } |
La colección user_images es sencilla, con un ID de registro (que puede ser referenciado por un perfil de usuario), un campo de tipo de imagen para poder soportar múltiples codecs de imagen y la propia imagen codificada en Base64. Como se señaló en el primer post de la serie, Couchbase soporta documentos binarios, pero hemos utilizado JSON por su portabilidad y extensibilidad en la aplicación de ejemplo. Esto viene a expensas de un poco de ancho de banda de red adicional para obtener los datos y ciclos de procesador para hacer la decodificación.
|
1 2 3 4 5 |
{ "record_id": 1, "tipo": "jpeg", "imagen": "AAAAD..." } |
La base servicio_aut contiene el token de autenticación, pero puede ampliarse fácilmente para incluir otros campos de autenticación.
|
1 2 3 4 |
{ "record_id": 1, "token": "6j6nW3KD0ZXodBv1" } |
Generación de datos JSON aleatorios de muestra
Escribí una utilidad llamada cb_perf para generar datos aleatorios e insertarlos en Couchbase. La utilidad también realiza algunas pruebas de rendimiento para calibrar las capacidades de Python en una plataforma. Herramientas como YCSB utilizan un esquema poco realista ya que el único objetivo es medir el rendimiento bruto. Yo quería la capacidad de tomar JSON arbitrario e insertarlo con datos sintéticos aleatorios.
Para probar el microservicio de ejemplo, añadí el esquema a cb_perf para poder generar conjuntos de datos de prueba en cualquier clúster de Couchbase. El sitio cb_perf utiliza un archivo de definición de esquema JSON. Para cada colección, se define la estructura de datos JSON.
Puedes especificar expresiones Jinja2 con variables que mapeen a tipos de datos aleatorios para cada valor JSON. De esta forma, cada registro será diferente. También puedes definir qué índices crear. En este caso, creamos un índice primario e índices secundarios en algunos campos.
Especifica que record_id es un campo ID y que el recuento global de registros solicitado no debe sobrescribirse (por lo que podemos crear tantos registros como queramos).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "nombre": "datos_usuario", "esquema": { "record_id": "record_id", "nombre": "{{ rand_first }} {{ rand_last }}", "apodo": "{{ rand_nickname }}", "foto": "", "user_id": "{{ rand_username }}", "email": "{{ rand_email }}", "email_verificado": "{{ rand_bool }}", "nombre": "{{ rand_first }}", "apellido": "{{ rand_last }}", "dirección": "{{ rand_address }}", "ciudad": "{{ rand_city }}", "estado": "{{ rand_state }}", "código_zip": "{{ rand_zip_code }}", "teléfono": "{{ rand_phone }}", "fecha_de_nacimiento": "{{ rand_dob_1 }}" }, "idkey": "record_id", "primary_index": verdadero, "override_count": falso, "índices": [ "record_id", "apodo", "user_id" ] }, |
Aprovechamos la cb_perf randomizer para la colección de imágenes para crear una imagen JPEG aleatoria (crea un mapa aleatorio de valores RGB para hacer una imagen de colores aleatorios). Definimos lo siguiente:
-
- Establecer record_id como ID de la imagen.
- Crear un índice primario y secundario en el campo ID.
- Utilice una cantidad de imágenes igual a la cantidad de registros solicitada.
- Anular la utilidad de tamaño de lote por defecto para operaciones asíncronas (el valor por defecto es 100) para establecerlo en 10 ya que estos documentos son grandes (aproximadamente 70KiB por documento). No queremos crear un cuello de botella si cargamos datos a través de una red de área amplia o Internet. El valor predeterminado se puede utilizar en una red privada de alto rendimiento, como una VPC en la nube o un centro de datos empresarial.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "nombre": "user_images", "esquema": { "record_id": "record_id", "tipo": "jpeg", "imagen": "{{ rand_image }}" }, "idkey": "record_id", "primary_index": verdadero, "override_count": falso, "tamaño_lote": 10, "índices": [ "record_id" ] }, |
Creamos un único registro de autenticación en la base de datos servicio_aut ya que es lo único que se necesita.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "nombre": "service_auth", "esquema": { "record_id": "record_id", "token": "{{ rand_hash }}" }, "idkey": "record_id", "primary_index": verdadero, "override_count": verdadero, "record_count": 1, "índices": [ "record_id" ] } |
Por último, conectamos los registros de imágenes con los registros de perfiles. Para ello, utilizamos la regla "enlace" como parte de la definición del esquema. Las reglas del esquema se ejecutan después de cargar los datos. Simplemente extraemos la lista de claves de registros de imagen y actualizamos el campo de imagen en los documentos de perfil para incluir una referencia a la clave de imagen.
|
1 2 3 4 5 6 7 8 |
"reglas": [ { "nombre": "rule0", "tipo": "enlace", "clave_extranjera": "sample_app:profiles:user_data:picture", "clave_primaria": "sample_app:profiles:user_images:record_id" } ] |
Carga de los datos generados
Cb_perf tiene un modo de carga que crea el número especificado de registros del esquema solicitado para cargar los datos.
|
1 |
% ./cb_perf carga --host db.ejemplo.com --esquema perfil_demo -u desarrollador -p contraseña --cuente 1000 |
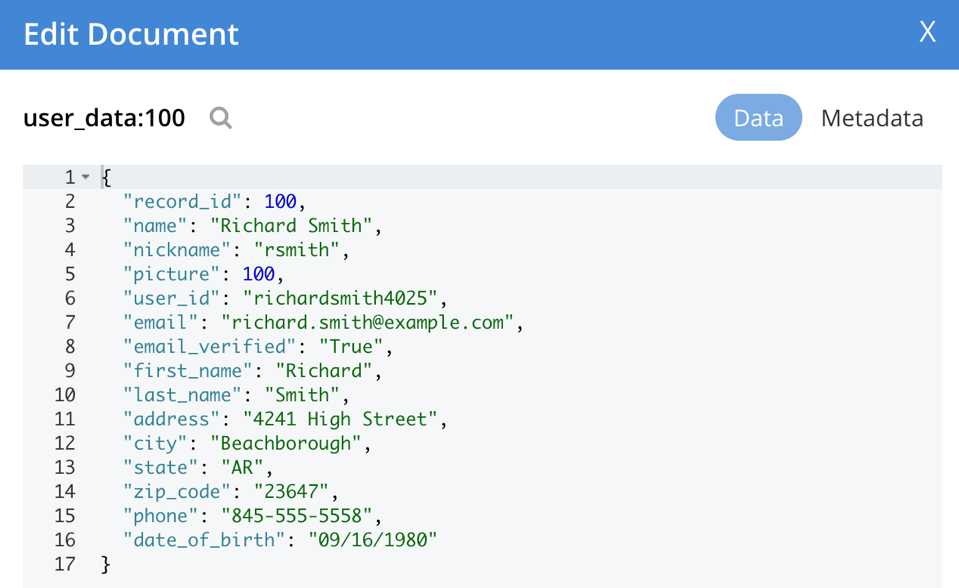
Una vez completado, se cargarán los datos y se crearán los índices. Ya estás listo para ejecutar y probar los microservicios. La utilidad genera automáticamente los IDs de los documentos (el ID del documento de Couchbase en los metadatos del documento, en contraposición al ID del registro en el documento) para que sean el nombre de la colección, más dos puntos y el ID del registro. Aquí podemos ver un ejemplo de lo que se ha cargado en el UI de Couchbase.
Siguiente
Esto completa la serie Construyendo un Microservicio Python con Couchbase. Sin embargo, estate atento a futuras actualizaciones sobre nuevas funcionalidades que se añadan a cb_perf y otros temas. Gracias por leer esta serie. Espero que le haya resultado informativa.
Recursos de Python y enlaces a series de blogs
-
- Descarga la utilidad cb_perf de mi GitHub
- Lea las entradas anteriores de esta serie:
- Documentación sobre Couchbase Python SDK - Primeros pasos con el SDK de Python
Dato curioso aleatorio
En un universo muy, muy lejano, en una época tecnológica diferente, Perl era el lenguaje interpretado más popular. Pasó de ser un lenguaje de procesamiento de textos (como el clásico AWK de UNIX) a convertirse en un lenguaje de propósito general omnipresente. Entre 1996 y 2000, la comunidad de Perl decidió tomar prestado el antiguo concurso de C ofuscado y organizó competiciones de Perl ofuscado. La sintaxis suelta y libre de Perl puede dar lugar a programas difíciles de descifrar, por lo que es natural que se celebrara un concurso de este tipo. Todos los programadores miran en algún momento algo que han escrito, quizá alimentados por la cafeína y la falta de sueño, y se preguntan qué hace.
|
1 |
pitón3 -c "print(bytearray([ord(b'a')+b%26 for b in [19,7,0,13,10,18]]).decode('utf-8'))" |
